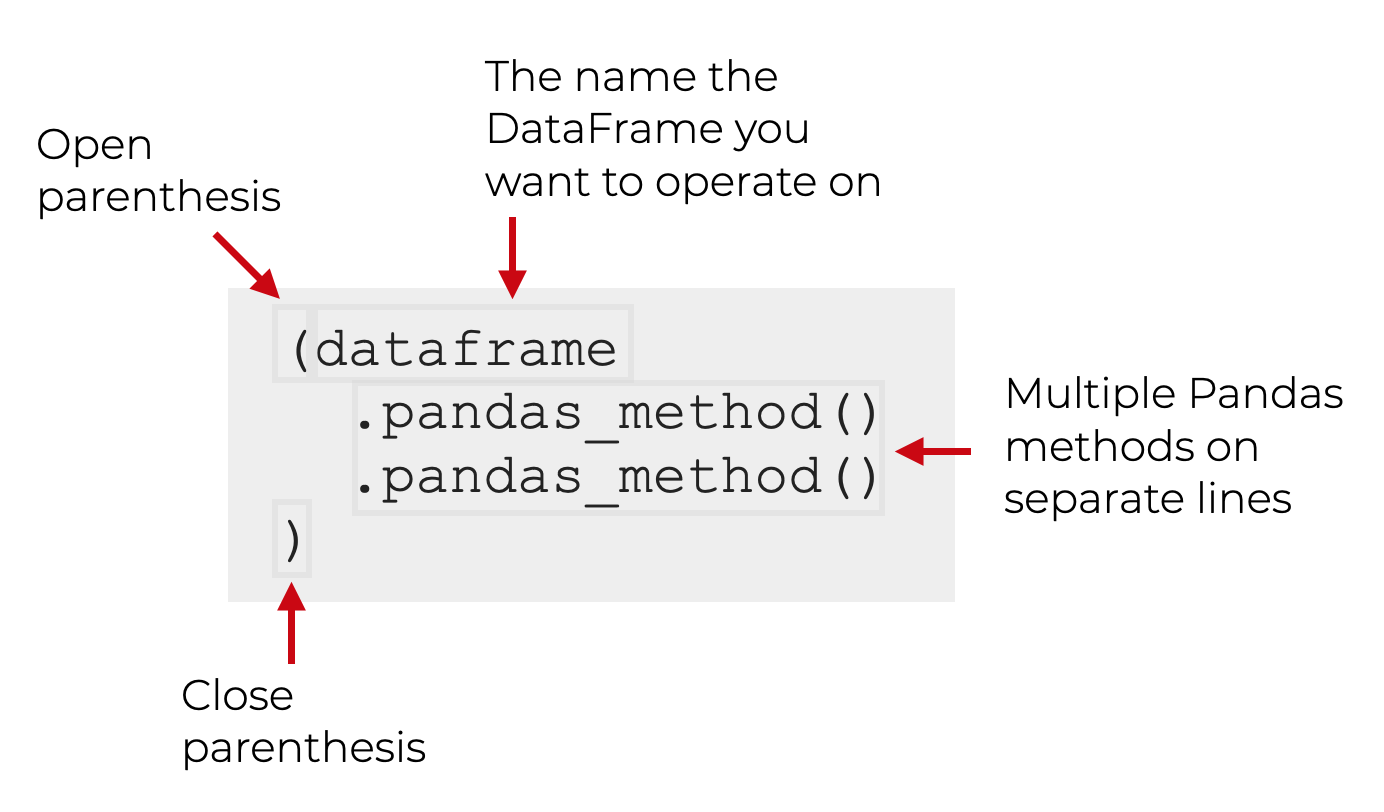
One of the most important techniques in pandas is chaining, which allows for cleaner and more readable data manipulation.
The general structure of chaining looks like this:
Key pandas methods
pandas provides methods or functions to solve common data manipulation tasks:
.filter() selects specific columns or rows.
.query() filters observations based on conditions.
.assign() adds new variables that are functions of existing variables.
.sort_values() changes the order of rows.
.agg() reduces multiple values to a single numerical summary.
To practice, we will use the dataset penguins_data.
Example 1
Let’s load the dataset and the pandas library.
import pandas as pd# Load the Excel file into a pandas DataFrame.penguins_data = pd.read_excel("penguins.xlsx")# Preview the dataset.penguins_data.head(4)
The .head() command allows us to print the first six rows of the newly produced dataframe. We must remove it to have the entire new dataframe.
We can also use .filter() to select rows too. To this end, we set axis = 1. We can select specific rows, such as 0 and 10.
(penguins_data .filter([0, 10], axis =0))
species
island
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g
sex
year
0
Adelie
Torgersen
39.1
18.7
181.0
3750.0
male
2007
10
Adelie
Torgersen
37.8
17.1
186.0
3300.0
NaN
2007
Or, we can select a set of rows using the function range(). For example, let’s select the first 5 rows.
(penguins_data .filter(range(5), axis =0))
species
island
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g
sex
year
0
Adelie
Torgersen
39.1
18.7
181.0
3750.0
male
2007
1
Adelie
Torgersen
39.5
17.4
186.0
3800.0
female
2007
2
Adelie
Torgersen
40.3
18.0
195.0
3250.0
female
2007
3
Adelie
Torgersen
NaN
NaN
NaN
NaN
NaN
2007
4
Adelie
Torgersen
36.7
19.3
193.0
3450.0
female
2007
Filtering rows with .query()
An alternative way of selecting rows is .query(). Compared to .filter(), .query() allows us to filter the data using statements or queries involving the variables.
For example, let’s filter the data for the species “Gentoo.”
We can even combine.filter() and .query(). For example, let’s select the columns species, body_mass_g and sex, then filter the data for the “Gentoo” species.
With .assign(), we can create new columns (variables) that are functions of existing ones. This function uses a special Python keyword called lambda. Technically, this keyword defines an anonymous function.
For example, we create a new variable LDRatio equaling the ratio of bill_length_mm and bill_depth_mm.
In this code, the df after lambda indicates that the dataframe (penguins_data) will be referred to as df inside the function. The colon : sets the start of the function.
Data wrangling is the process of transforming raw data into a clean and structured format.
It involves merging, reshaping, filtering, and organizing data for analysis.
Here, we illustrate some special functions of the pandas for cleaning common issues with a dataset.
Example 2
Consider an industrial engineer who receives a messy Excel file from a manufacturing client. The data file is called “industrial_dataset.xlsx”, which file includes data about machine maintenance logs, production output, and operator comments.
The goal is to clean and prepare this dataset using pandas so it can be analyzed.
Let’s read the data set into Python.
# Load the Excel file into a pandas DataFrame.client_data = pd.read_excel("industrial_dataset.xlsx")
# Preview the dataset.client_data.head()
Machine ID
Output (units)
Maintenance Date
Operator
Comment
0
101
1200
2023-01-10
Ana
ok
1
101
1200
2023-01-10
Ana
ok
2
102
1050
2023-01-12
Bob
Needs oil!
3
103
error
2023-01-13
Charlie
All good\n
4
103
950
2023-01-13
Charlie
All good\n
Remove duplicate rows
Duplicate or identical rows are rows that have the same entries in every column in the dataset.
If only one row is needed for the analysis, we can remove the duplicates using the .drop_duplicates() function.
The client_data_single dataframe does not have duplicate rows.
client_data_single.head()
Machine ID
Output (units)
Maintenance Date
Operator
Comment
0
101
1200
2023-01-10
Ana
ok
1
101
1200
2023-01-10
Ana
ok
2
102
1050
2023-01-12
Bob
Needs oil!
3
103
error
2023-01-13
Charlie
All good\n
4
103
950
2023-01-13
Charlie
All good\n
Add an index column
In some cases, it is useful to have a unique identifier for each row in the dataset. We can create an identifier using the function .assign with some extra syntaxis.
In the dataset, there are columns with missing values. If we would like to fill them with specific values or text, we use the .fillna() function. In this function, we use the syntaxis 'Variable': 'Replace', where the Variable is the column in the dataset and Replace is the text or number to fill the entry in.
Let’s fill in the missing entries of the columns Operator, Maintenance Date, and Comment.
The column has the numbers of units but also text such as “error”.
We can replace the “error” in this column by a user-specified value, say, 0. To this end, we use the function .replace(). The function has two inputs. The first one is the value to replace and the second one is the replacement value.
There are some cases in which we want to split a column according to a character. For example, consider the column Comment from the dataset.
complete_data['Comment']
0 ok
1 ok
2 Needs oil!
3 All good\n
4 All good\n
...
95 Requires part: valve
96 ok
97 Delay: maintenance\n
98 Needs oil!
99 All good\n
Name: Comment, Length: 100, dtype: object
The column has some values such as “Requires part: valve” and “Delay: maintenance” that we may want to split into columns.
0 ok
1 ok
2 Needs oil!
3 All good\n
4 All good\n
...
95 Requires part: valve
96 ok
97 Delay: maintenance\n
98 Needs oil!
99 All good\n
Name: Comment, Length: 100, dtype: object
We can split the values in the column according to the colon “:”.
That is, everything before the colon will be in a column. Everything after the colon will be in another column. To achieve this, we use the function str.split().
One input of the function is the symbol or character for which we cant to make a split. The other input, expand = True tells Python that we want to create new columns.
0 ok
1 ok
2 Needs oil!
3 All good
4 All good
...
95 Requires part
96 ok
97 Delay
98 Needs oil!
99 All good
Name: First_comment, Length: 100, dtype: object
We can also remove other characters.
augmented_data['First_comment'].str.strip("!")
0 ok
1 ok
2 Needs oil
3 All good
4 All good
...
95 Requires part
96 ok
97 Delay
98 Needs oil
99 All good
Name: First_comment, Length: 100, dtype: object
Transform text case
When working with text columns such as those containing names, it might be possible to have different ways of writing. A common case is when having lower case or upper case names or a combination thereof.
For example, consider the column Operator containing the names of the operators.
complete_data['Operator'].head()
0 Ana
1 Ana
2 Bob
3 Charlie
4 Charlie
Name: Operator, dtype: object
Remove extra spaces
To deal with names, we first use the .str.strip() to remove leading and trailing characters from strings.