import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, TimeSeriesSplit
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.ensemble import BaggingRegressor, RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.inspection import permutation_importanceEnsemble Methods for Regression
IN2004B: Generation of Value with Data Analytics
Alan R. Vazquez
Department of Industrial Engineering
Agenda
- Introduction
- Bagging
- Random Forests
- Boosting
- Ensemble Methods for Time Series
Introduction
Load the libraries
Before we start, let’s import the data science libraries into Python.
Here, we use specific functions from the pandas, matplotlib, seaborn and sklearn libraries in Python.
Decision trees
Simple and useful for interpretations.
Can handle continuous and categorical predictors and responses. So, they can be applied to both classification and regression problems.
Computationally efficient.
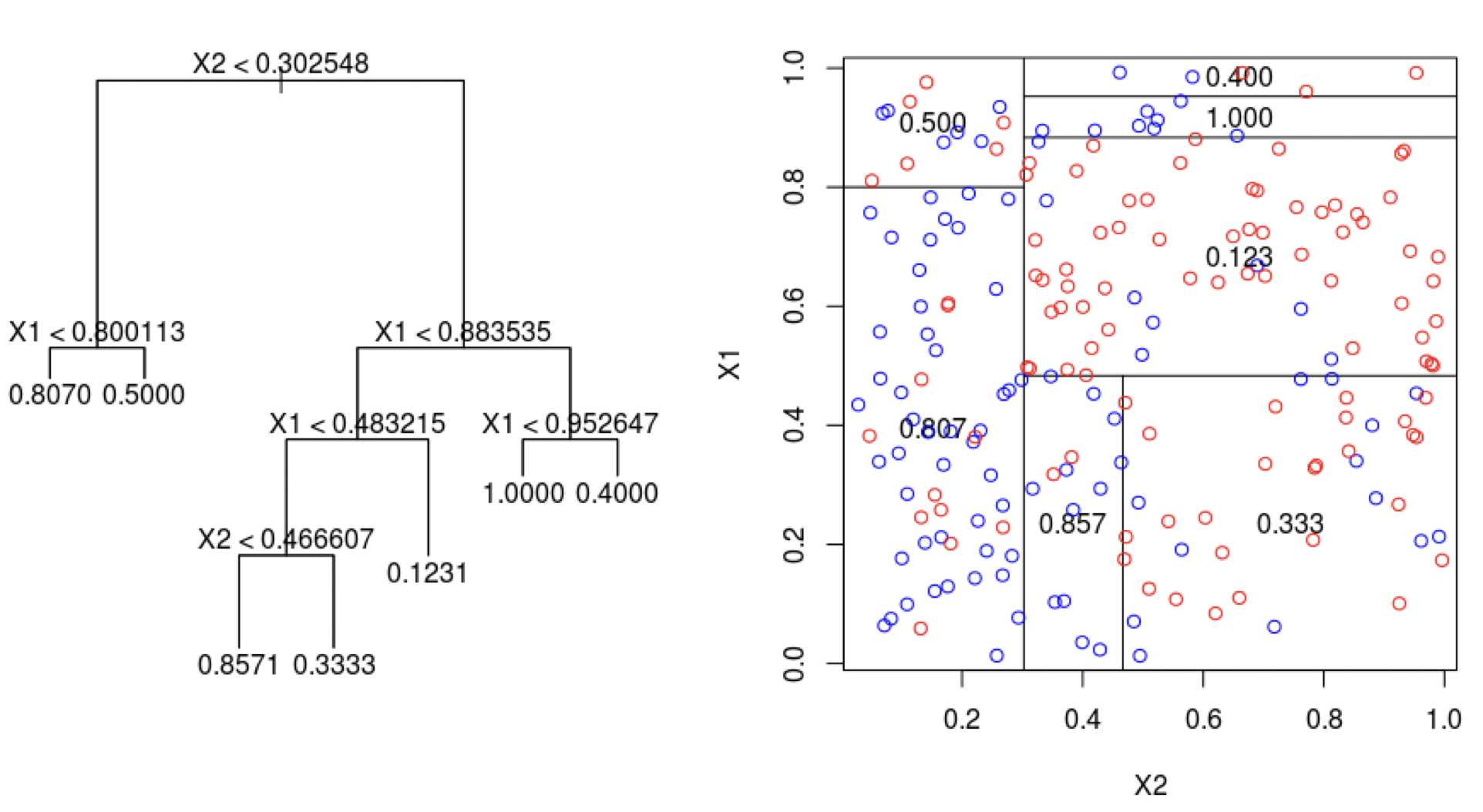
Decision trees for regression
The procedure for constructing a decision tree for regression is the same as for a classification tree.
That is, we use the CART algorithm for building large trees and cost complexity pruning to reduce them, if desired.
However, instead of using impurity to evaluate splits, we use the mean squared error.
To compute the mean squared error we use
The predicted response is the average response calculated in the node or region.
The actual responses are those of the observations in the region.
We refer to decision trees for regression as regression trees.
Example 1
The “Hitters.xlsx” dataset contains data collected from Major League Baseball players. It includes data on various statistics such as number of hits, years in the league, and salary. The goal is to predict a player’s salary based on performance statistics.
The response is the player’s salary (in $), contained in the column Salary.
For this example, we will focus on two predictors:
Hits: Number of hits in the season
Years: Number of years the player has been in the league
Read the dataset
We read the dataset
| AtBat | Hits | HmRun | Runs | RBI | Walks | Years | CAtBat | CHits | CHmRun | CRuns | CRBI | CWalks | League | Division | PutOuts | Assists | Errors | Salary | NewLeague | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 293 | 66 | 1 | 30 | 29 | 14 | 1 | 293 | 66 | 1 | 30 | 29 | 14 | A | E | 446 | 33 | 20 | NaN | A |
| 1 | 315 | 81 | 7 | 24 | 38 | 39 | 14 | 3449 | 835 | 69 | 321 | 414 | 375 | N | W | 632 | 43 | 10 | 475.0 | N |
| 2 | 479 | 130 | 18 | 66 | 72 | 76 | 3 | 1624 | 457 | 63 | 224 | 266 | 263 | A | W | 880 | 82 | 14 | 480.0 | A |
| 3 | 496 | 141 | 20 | 65 | 78 | 37 | 11 | 5628 | 1575 | 225 | 828 | 838 | 354 | N | E | 200 | 11 | 3 | 500.0 | N |
| 4 | 321 | 87 | 10 | 39 | 42 | 30 | 2 | 396 | 101 | 12 | 48 | 46 | 33 | N | E | 805 | 40 | 4 | 91.5 | N |
The data set has some missing observations. So, we remove the observations with at least one missing value in a predictor.
| AtBat | Hits | HmRun | Runs | RBI | Walks | Years | CAtBat | CHits | CHmRun | CRuns | CRBI | CWalks | League | Division | PutOuts | Assists | Errors | Salary | NewLeague | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 315 | 81 | 7 | 24 | 38 | 39 | 14 | 3449 | 835 | 69 | 321 | 414 | 375 | N | W | 632 | 43 | 10 | 475.0 | N |
| 2 | 479 | 130 | 18 | 66 | 72 | 76 | 3 | 1624 | 457 | 63 | 224 | 266 | 263 | A | W | 880 | 82 | 14 | 480.0 | A |
| 3 | 496 | 141 | 20 | 65 | 78 | 37 | 11 | 5628 | 1575 | 225 | 828 | 838 | 354 | N | E | 200 | 11 | 3 | 500.0 | N |
| 4 | 321 | 87 | 10 | 39 | 42 | 30 | 2 | 396 | 101 | 12 | 48 | 46 | 33 | N | E | 805 | 40 | 4 | 91.5 | N |
| 5 | 594 | 169 | 4 | 74 | 51 | 35 | 11 | 4408 | 1133 | 19 | 501 | 336 | 194 | A | W | 282 | 421 | 25 | 750.0 | A |
Generating training and validation data
Select the predictors and response
We partition the full dataset into 70% for training and the other 30% for validation.
Regression trees in Python
We train a regression tree using the DecisionTreeRegressor() function from regression.
We use max_depth = 3 to have a small tree as an example.
Plotting the tree
To see the decision tree, we use the plot_tree function from scikit-learn and some commands from matplotlib.
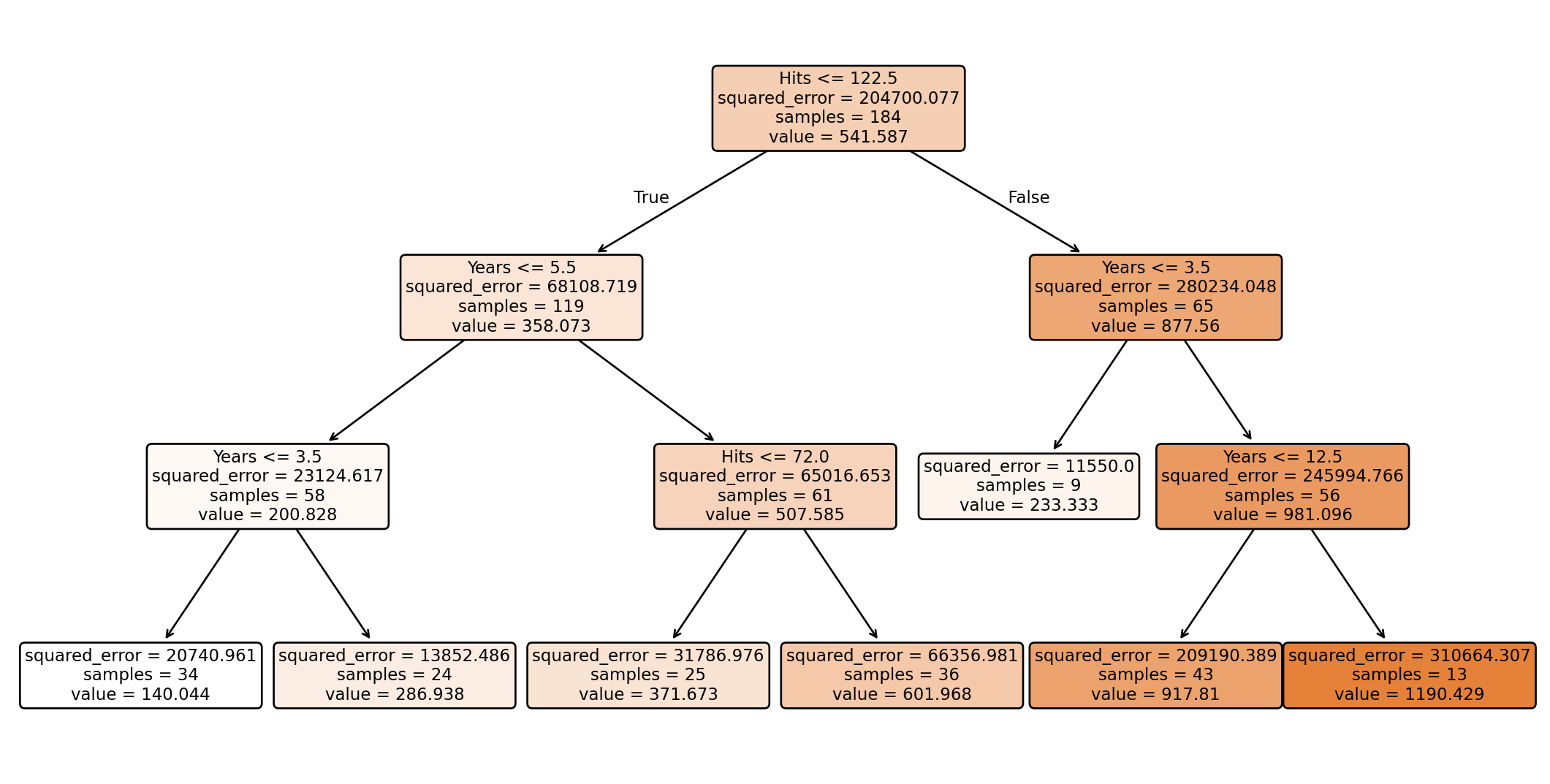
Visualize the regions
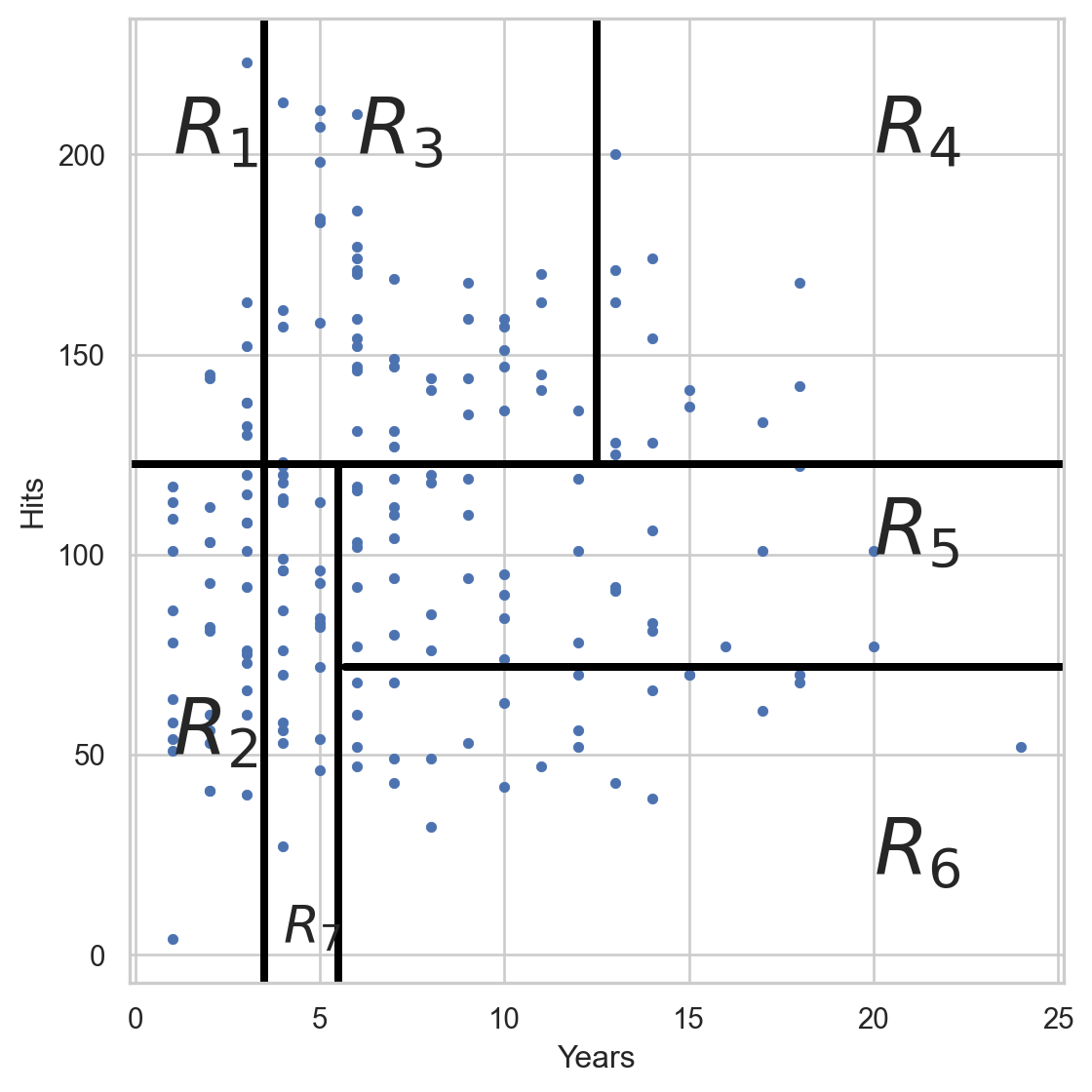
Visualize the predictions
We predict with the average response (\(Y\)) of the observations in each region.
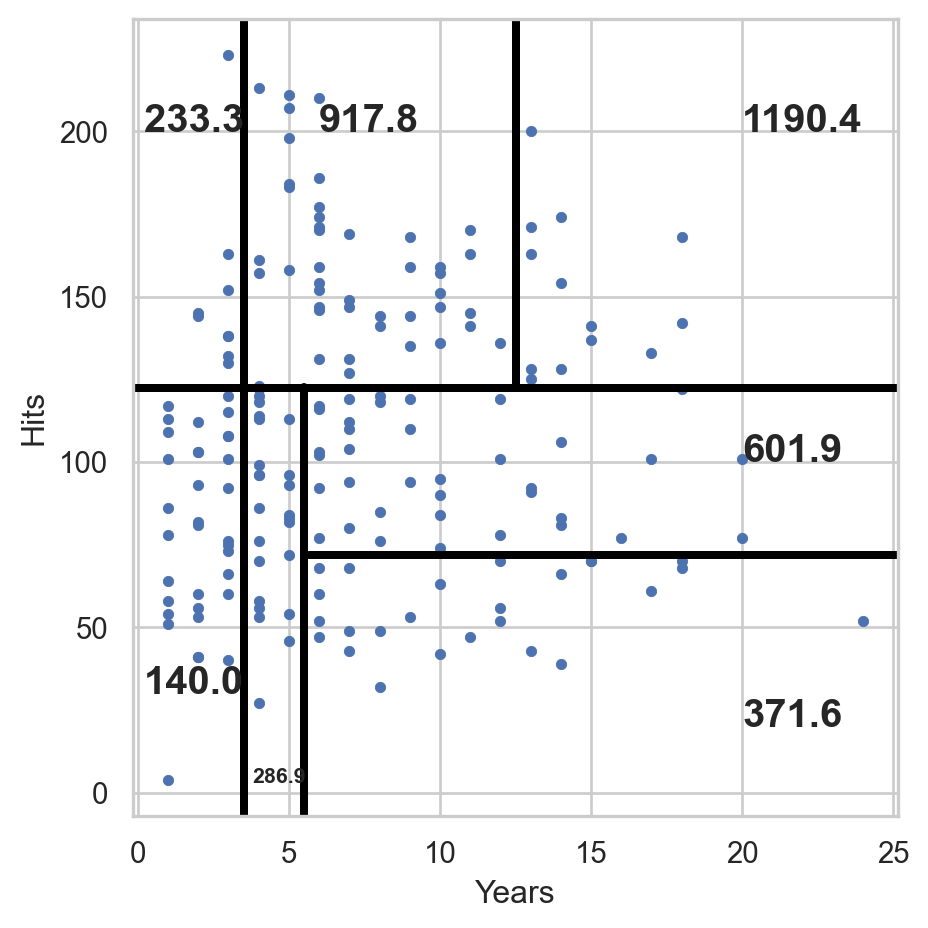
Predictions on the validation data
To predict the responses on the validation data, we use the function .predict() using the predictor values in the validation dataset contained in X_valid.
array([ 917.80951163, 601.96761111, 286.9375 , 286.9375 ,
286.9375 , 140.04411765, 917.80951163, 371.67336 ,
917.80951163, 917.80951163, 286.9375 , 140.04411765,
286.9375 , 140.04411765, 140.04411765, 601.96761111,
917.80951163, 371.67336 , 917.80951163, 917.80951163,
1190.42853846, 233.33333333, 286.9375 , 140.04411765,
917.80951163, 917.80951163, 233.33333333, 917.80951163,
140.04411765, 140.04411765, 140.04411765, 601.96761111,
601.96761111, 1190.42853846, 917.80951163, 233.33333333,
371.67336 , 371.67336 , 286.9375 , 601.96761111,
917.80951163, 1190.42853846, 601.96761111, 371.67336 ,
917.80951163, 1190.42853846, 233.33333333, 917.80951163,
601.96761111, 1190.42853846, 917.80951163, 371.67336 ,
1190.42853846, 233.33333333, 917.80951163, 286.9375 ,
601.96761111, 371.67336 , 233.33333333, 140.04411765,
233.33333333, 140.04411765, 917.80951163, 371.67336 ,
1190.42853846, 917.80951163, 917.80951163, 917.80951163,
917.80951163, 140.04411765, 286.9375 , 917.80951163,
601.96761111, 140.04411765, 601.96761111, 601.96761111,
601.96761111, 601.96761111, 917.80951163])Validation RMSE
Recall that the responses from the validation dataset are in Y_valid, and the model predictions are in Y_pred. We compute the root mean squared error on the validation data using the mse() function.
Limitations of decision trees
In general, decision trees do not work well for classification and regression problems.
However, they can be combined to build effective algorithms for these problems.
Ensamble methods
Ensemble methods are frameworks to combine decision trees.
Here, we will cover two popular ensamble methods:
Bagging. Ensemble many deep trees.
- Quintessential method: Random Forests.
Boosting. Ensemble small trees sequentially.
Bagging
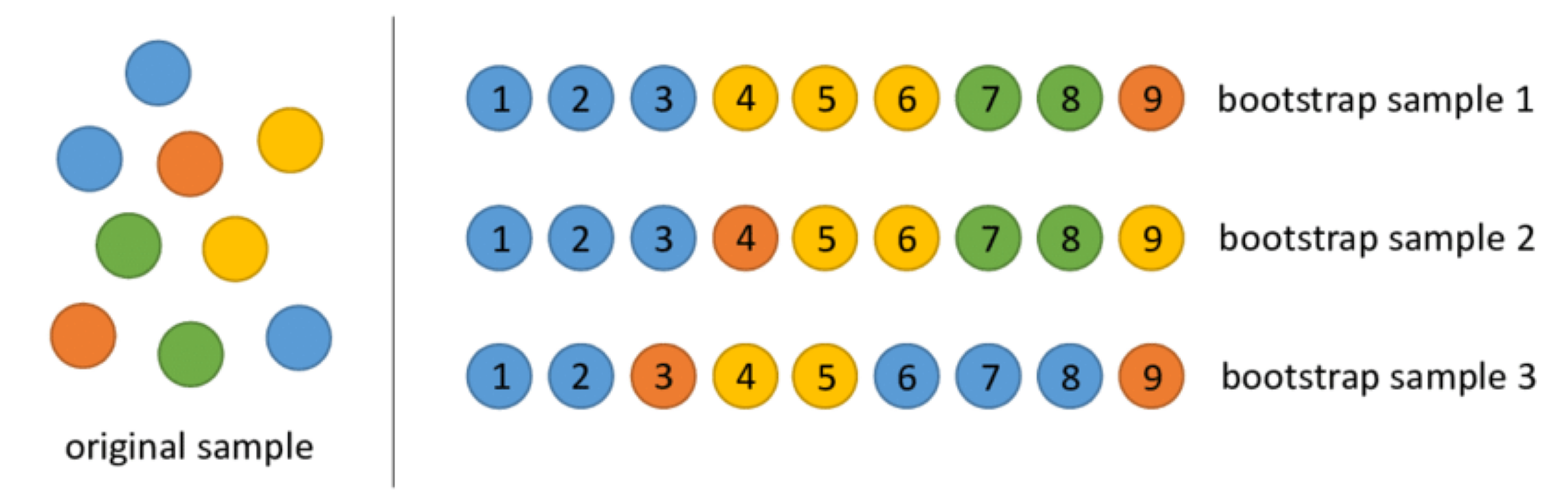
Bootstrap samples
Bootstrap samples are samples obtained with replacement from the original sample. So, an observation can occur more than one in a bootstrap sample.
Bootstrap samples are the building block of the bootstrap method, which is a statistical technique for estimating quantities about a population by averaging estimates from multiple small data samples.
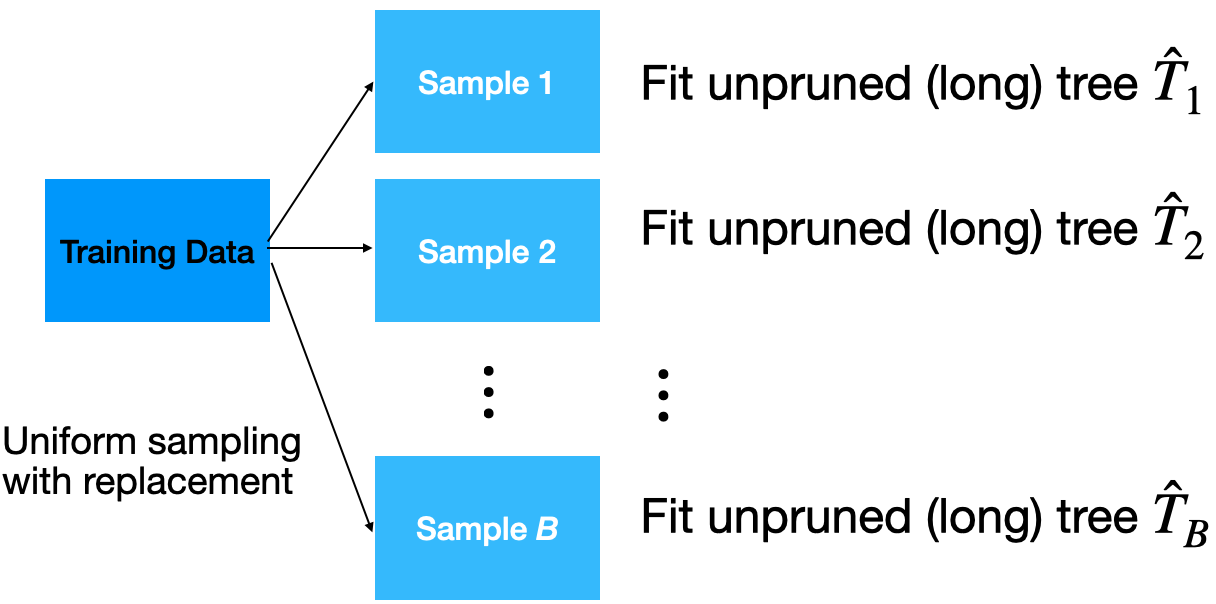
Bagging
Given a training dataset, bagging averages the predictions from decision trees over a collection of bootstrap samples.
Predictions
Let \(\boldsymbol{x} = (x_1, x_2, \ldots, x_p)\) be a vector of new predictor values.
For regression problems:
Each regression tree outputs the average value depending on the region \(\boldsymbol{x}\) falls in. For the b-th tree, denote such average as \(\hat{T}_{b}(\boldsymbol{x})\).
Predict using the average of all regression trees
\[\hat{f}_{bag}(\boldsymbol{x}) = \frac{1}{B} \sum_{b=1}^{B} \hat{T}_{b}(\boldsymbol{x}). \]
Implementation
How many trees? No risk of overfitting, so use plenty.
No pruning necessary to build the trees. However, one can still decide to apply some pruning or early stopping mechanism.
The size of bootstrap samples is the same as the size of the training dataset, but we can use a different size.
Example 2
The “BostonHousing.xlsx” contains data collected by the US Bureau of the Census concerning housing in the area of Boston, Massachusetts. The dataset includes data on 506 census housing tracts in the Boston area in 1970s.
The goal is to predict the median house price in new tracts based on information such as crime rate, pollution, and number of rooms.
The response is the median value of owner-occupied homes in $1000s, contained in the column MEDV.
The predictors
CRIM: per capita crime rate by town.ZN: proportion of residential land zoned for lots over 25,000 sq.ft.INDUS: proportion of non-retail business acres per town.CHAS: Charles River (‘Yes’ if tract bounds river; ‘No’ otherwise).NOX: nitrogen oxides concentration (parts per 10 million).RM: average number of rooms per dwelling.AGE: proportion of owner-occupied units built prior to 1940.DIS: weighted mean of distances to five Boston employment centersRAD: index of accessibility to radial highways (‘Low’, ‘Medium’, ‘High’).TAX: full-value property-tax rate per $10,000.PTRATIO: pupil-teacher ratio by town.LSTAT: lower status of the population (percent).
Read the dataset
We read the dataset and set the variable CHAS and RAD as categorical.
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | No | 0.538 | 6.575 | 65.2 | 4.0900 | Low | 296 | 15.3 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | No | 0.469 | 6.421 | 78.9 | 4.9671 | Low | 242 | 17.8 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | No | 0.469 | 7.185 | 61.1 | 4.9671 | Low | 242 | 17.8 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | No | 0.458 | 6.998 | 45.8 | 6.0622 | Low | 222 | 18.7 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | No | 0.458 | 7.147 | 54.2 | 6.0622 | Low | 222 | 18.7 | 5.33 | 36.2 |
Generating predictors in Python
We use the function .drop() from pandas to drop the response column MEDV and store the result in X_full.
Unfortunately, bagging does not work with categorical predictors such as CHAS and RAD. So, we must transform them into dummy variables using the code below.
# Turn categorical predictors into dummy variables.
X_dummies = pd.get_dummies(X_full[['CHAS', 'RAD']], drop_first = True, dtype = 'int')
# Drop original predictors from the dataset.
X_other = X_full.drop(['CHAS', 'RAD'], axis=1)
# Update the predictor matrix.
X_full = pd.concat([X_other, X_dummies], axis=1)Next, we use the function .filter() from pandas to extract the column MEDV from the data frame. We store the result in Y_full.
We partition the full dataset into 80% for training and the other 20% for validation.
Bagging in Python
We define a bagging algorithm for regression using the BaggingRegressor function from scikit-learn.
The n_estimators argument is the number of decision trees to generate in bagging. Ideally, it should be high, around 500.
random_state allows us to obtain the same bagging algorithm in different runs of the algorithm.
Predictions on the validation data
To predict the responses on the validation data, we use the function .predict() using the predictor values in the validation dataset contained in X_valid.
array([19.6658, 13.7368, 21.1204, 44.2054, 25.0334, 34.5046, 30.0714,
14.9126, 23.185 , 20.2232, 17.0034, 20.0364, 19.7258, 8.9552,
24.2136, 29.2074, 21.12 , 20.8784, 25.4168, 18.6084, 22.7604,
26.452 , 24.025 , 35.9372, 23.5698, 20.2344, 8.3688, 15.9038,
47.4466, 24.2666, 34.4922, 23.2298, 24.4656, 13.3668, 22.6112,
12.7678, 27.8812, 19.8882, 22.7836, 18.9106, 9.0864, 24.6914,
21.9024, 12.3184, 27.1866, 33.0508, 19.436 , 25.7136, 19.4562,
25.3064, 26.8094, 16.9618, 20.8276, 28.7036, 27.884 , 12.5904,
23.2554, 38.432 , 20.3296, 22.0288, 17.894 , 15.8226, 13.5456,
21.0472, 23.069 , 20.6296, 20.5934, 15.8522, 32.7326, 33.4602,
15.3956, 17.5128, 21.2734, 20.6626, 29.7304, 15.4016, 18.9904,
19.0864, 32.4364, 21.6208, 22.1254, 20.5334, 23.8114, 21.0438,
34.0556, 21.5676, 19.8904, 19.025 , 21.4108, 15.335 , 46.5098,
23.533 , 8.2252, 14.905 , 25.672 , 16.1982, 22.2198, 45.0716,
14.5424, 21.2396, 14.9436, 22.3806])Validation RMSE
We compute the root mean squared error on the validation data using the mse() function.
A single deep tree
To compare the bagging, let’s use a single deep tree.
And compute the validation RMSE of that tree.
5.87The validation RMSE of the tree is higher than that of the bagging algorithm. So, ensembeling several trees improves the prediction performance.
Advantages
Bagging will have lower prediction errors than a single regression tree.
The fact that, for each tree, not all of the original observations were used, can be exploited to produce an estimate of the accuracy for classification. This estimate is called the out-of-bag error estimate which is an estimate of the RMSE on the test dataset.
Limitations
Loss of interpretability: the final bagged classifier is not a tree, and so we forfeit the clear interpretative ability of a classification tree.
Computational complexity: we are essentially multiplying the work of growing (and possibly pruning) a single tree by \(B\).
Fundamental issue: bagging a good model can improve predictive performance, but bagging a bad one can seriously degrade it.
Other issues
Suppose a variable is very important and decisive.
It will probably appear near the top of a large number of trees.
And these trees will tend to vote the same way.
In some sense, then, many of the trees are “correlated”.
This will degrade the performance of bagging.
Random Forest
Random Forest
Exactly as bagging, but…
- When splitting the nodes using the CART algorithm, instead of going through all possible splits for all possible variables, we go through all possible splits on a random sample of a small number of variables \(m\), where \(m < p\).
Random forests can improve the performance of bagging.
Why does it work?
Not so dominant predictors will get a chance to appear by themselves and show “their stuff”.
This adds more diversity to the trees.
The fact that the trees in the forest are not (strongly) correlated means lower variability in the predictions and so, a bettter performance overall.
Tuning parameter
How do we set \(m\)?
- For regression, can use \(m = \sqrt{p}\) and a minimum leaf node size of 5.
In practice, sometimes the best values for these parameters will depend on the problem. So, we can treat \(m\) as a tuning parameter.
Note that if \(m = p\), we get bagging.
The final product is a black box

A black box. Inside the box are several hundred trees, each slightly different.
You put an observation into the black box, and the black box classifies it or predicts it for you.
Random Forest in Python
In Python, we define a RandomForest algorithm for classification using the RandomForestRegressor function from scikit-learn.
n_estimators sets the number of decision trees to use, min_samples_leaf sets the minimum size for the terminal nodes, and max_features sets the maximum number of predictors to try in each split.
Validation RMSE
Evaluate the performance of random forest.
Predictor importance
Random Forests and bagged trees are a black box. But “Importance” is a statistic that attempts to give us some insight.
The importance statistic assumes that we have trained a random forest and we have validation data.
Calculation of importance
We record the prediction error of the trained algorithm on the validation data. This serves as a baseline.
Next, a variable is “taken out” by having all of its values permuted in the validation dataset. We then compute the prediction error of the algorithm on the perturbed validation data.
The importance statistic is the difference between the error due to the perturbation and the baseline. A larger difference means an important predictor for the algorithm.
In Python, we use compute the predictor importance using the permutation_importance() function.
Code
# Create DataFrame
importance_df = pd.DataFrame({
'Feature': X_valid.columns,
'Importance': result.importances_mean
}).sort_values(by='Importance', ascending=False)
# Plot bar chart
plt.figure(figsize=(8, 5))
plt.bar(importance_df['Feature'], importance_df['Importance'])
plt.xticks(rotation=90)
plt.title('Permutation Feature Importance')
plt.show()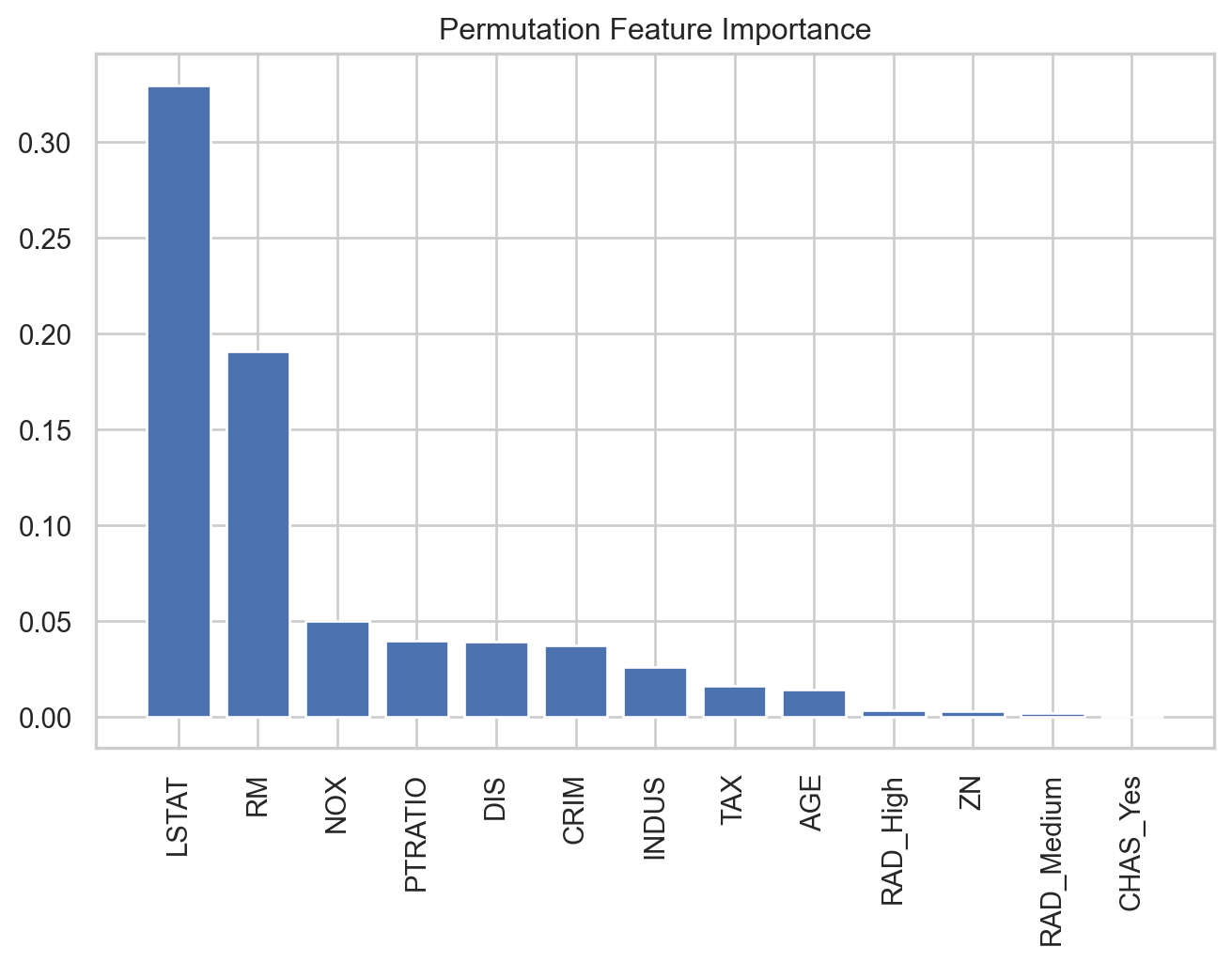
Boosting
Boosting
In boosting, we also grow multiple decision trees. But instead of growing trees randomly, each new tree depends on the previous one.
Boosting is easier to understand in the context of regression, rather than classification.
Idea: Explore cooperation between desicion trees, rather than diversity as in Bagging and Random Forest.
Boosting for regression
Boosting creates a sequence of trees, each one building upon the previous.
Earlier trees are small, and the next tree is created with the residuals of the previous tree.
In other words, at each step, we try to explain the information that we didn’t explain in previous steps.
Gradually, the sequence “learns” to predict.
Something a little odd: earlier trees are deliberately “held back” to keep them from explaining too much. This creates “slow learning”.
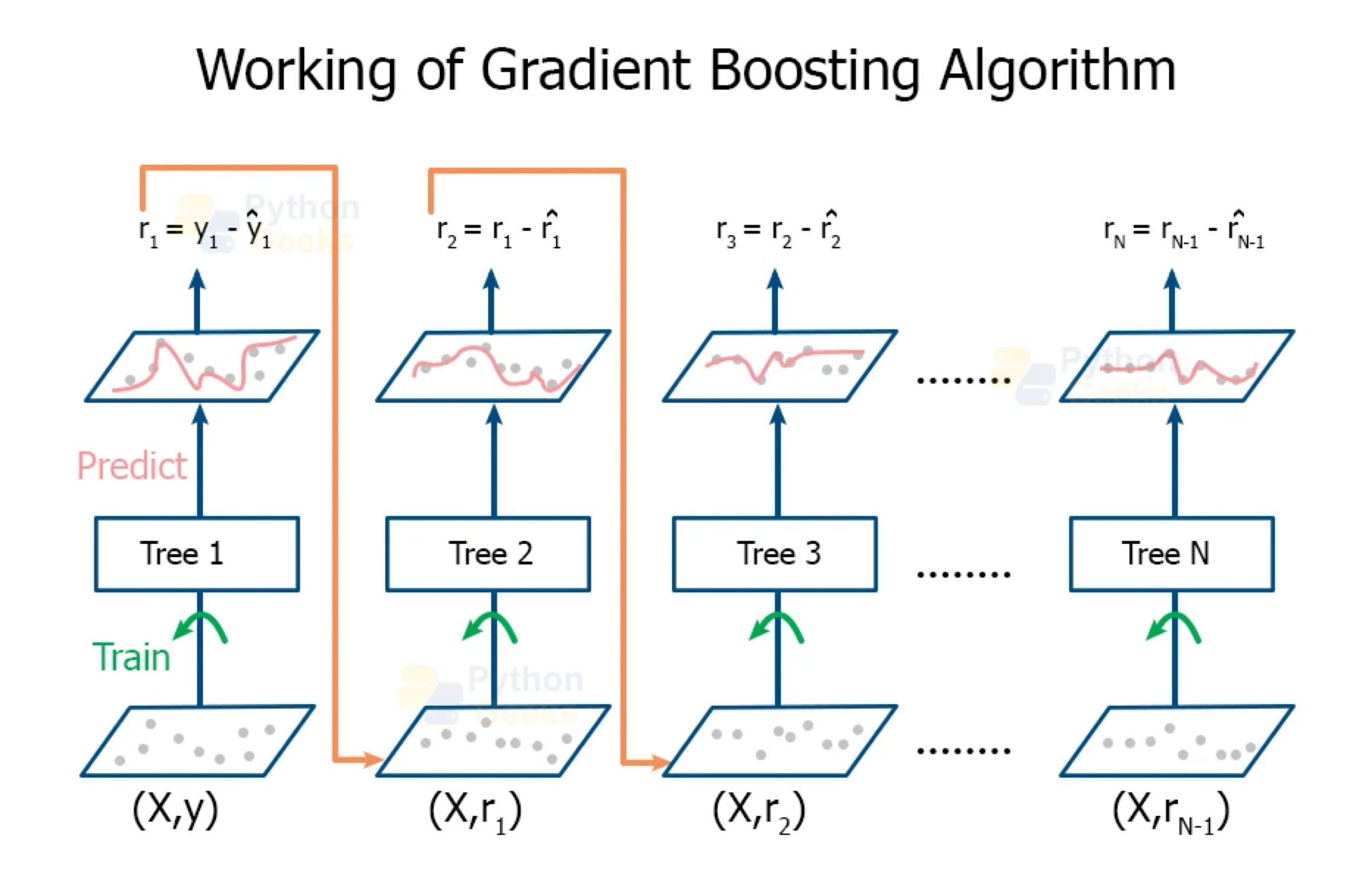
https://pythongeeks.org/gradient-boosting-algorithm-in-machine-learning/
Initially, the boosted tree is \(\hat{f}(\boldsymbol{x}) = 0\) and the residuals of this tree are \(r_i = y_i - f(\boldsymbol{x}_i)\) for all \(i\) in the training data.
At each step \(b\) in the process (\(b = 1, \ldots, B\)), we
- Build a regression tree \(\hat{T}_b\) with \(d\) splits to the training data \((\boldsymbol{X}, \boldsymbol{r})\). This tree has \(d+1\) terminal nodes.
- Update the boosted tree \(\hat{f}\) by adding in a shrunken version of the new tree: \(\hat{f}(\boldsymbol{x}) \leftarrow \hat{f}(\boldsymbol{x}) + \lambda \hat{T}_b(\boldsymbol{x})\).
- Update the residuals using shrunken tree, \(r_i \leftarrow r_i - \lambda \hat{T}_b(x_i)\).
The final boosted tree is: \(\hat{f}(\boldsymbol{x}) = \sum_{b=1}^{B} \lambda \hat{T}_b (\boldsymbol{x}).\)
Why does this work?
By using a small tree, we are deliberately leaving information out of the first round of the model. So what gets fit is the “easy” stuff.
The residuals have all of the information that we haven’t yet explained. We continue iterating on the residuals, fitting them with small trees, so that we slowly explain the bits of the variation that are harder to explain.
This process is called “learning”: at each iteration, we get a better fit.
By multiplying by \(\lambda <1\), we “slow down” the learning (by making it harder to fit all of the variation), and there is research that says that slower learning is better.
Tuning parameters
The number of trees \(B\). Unlike bagging and random forest, boosting can overfit if \(B\) is too large. We use so-called K-fold cross-validation to select \(B\).
The shrinkage parameter \(\lambda\), a small positive number. Typical values are 0.01 or 0.001. Very small \(\lambda\) can require using a very large value of B to achieve good performance.
The number of splits \(d\) in each tree. Common choices are 1, 4 or 5. Often \(d = 1\), in which case each tree is a stump.
Boosting in Python
In Python, we define a Boosting algorithm for classification using the GradientBoostingRegressor function from scikit-learn.
n_estimators sets the number of decision trees to use, learning_rate sets the value of \(\lambda\), and max_depth sets the depth of the tree.
Validation RMSE for boosting
Evaluate the performance of the boosting algorithm.
Predictor importance
We can also apply predictor importance to the gradient boosting algorithm.
Code
# Compute permutation importance
result = permutation_importance(GBalgorithm, X_valid, Y_valid, n_repeats=5, random_state=59227)
# Create DataFrame
importance_df = pd.DataFrame({
'Feature': X_valid.columns,
'Importance': result.importances_mean
}).sort_values(by='Importance', ascending=False)
# Plot bar chart
plt.figure(figsize=(5, 3))
plt.bar(importance_df['Feature'], importance_df['Importance'])
plt.xticks(rotation=90)
plt.title('Permutation Feature Importance')
plt.show()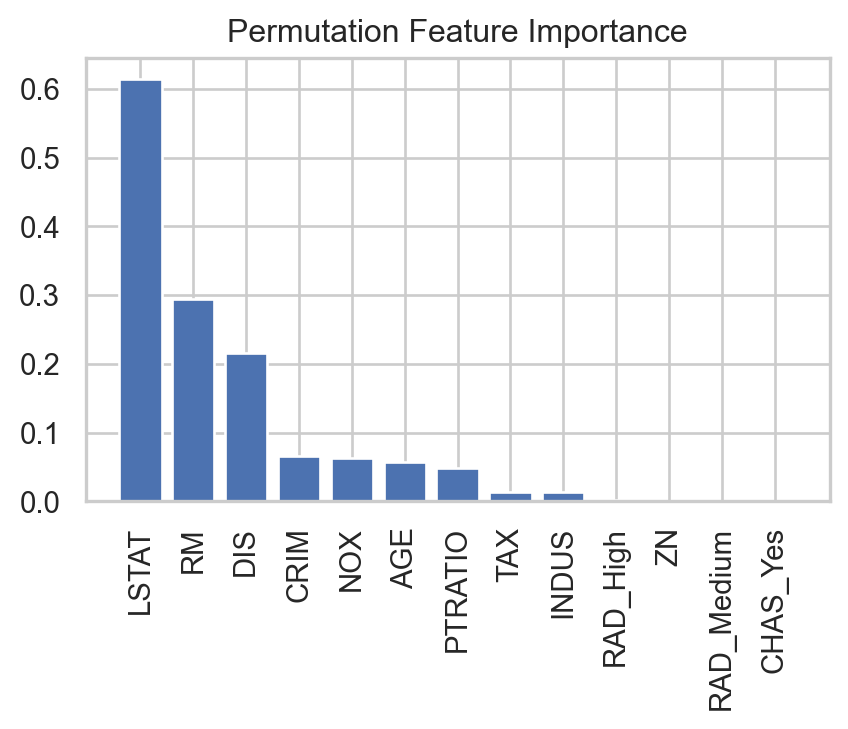
Issues with boosting
Loss of interpretability: the final boosted model is a weighted sum of trees, which we cannot interpret easily.
Computational complexity: since it uses slow learners, it can be time consuming. However, we are growing small trees, each step can be done relatively quickly in some cases (e.g. AdaBoost).
Ensemble methods for Time Series
Example 3
Let’s consider the dataset consisting of weekly cases of chickenpox (a childhood disease) in Hungary. The dataset has the number of reported cases in Budapest from January 2005 to December 2013.
The goal is to predict the number of reported cases weekly starting in 2014.
Return to main page
![]()
Tecnologico de Monterrey