Se utiliza ampliamente para la limpieza, visualización y modelado de datos.
Se puede ampliar con paquetes (librerías) desarrollados por otros usuarios.
Google Colab
Plataforma gratuita de colaboración en la nube de Google para crear documentos Python.
Ejecuta Python y colabora en cuadernos Jupyter gratis.
Aprovecha la potencia de las GPU gratis para acelerar tus proyectos de ciencia de datos.
Guarda y sube fácilmente tus cuadernos a Google Drive.
Probemos un comando en Python
¿Qué crees que sucederá si ejecutamos este comando?
print("Hello world!")
Hello world!
Probemos con otro comando
¿Qué crees que sucederá si ejecutamos este comando?
sum([1, 5, 10])
16
Usar Python como calculadora básica
5+1
6
10-3
7
2*4
8
9/3
3.0
Comentarios
A veces escribimos cosas en la ventana de código que queremos que Python ignore. Estos se llaman comentarios y comienzan con #.
Python ignorará los comentarios y simplemente ejecutará el código.
# puedes poner lo que sea después de ## por ejemplo... blah blah blah
Funciones en Python
Una de las mejores características de Python es la gran cantidad de comandos integrados que puedes usar. Estos se llaman funciones.
Las funciones tienen dos partes básicas:
La primera parte es el nombre de la función (por ejemplo, sum).
La segunda parte es el valor de entrada para la función, que va dentro de los paréntesis (sum([1, 5, 15])).
Python es estricto
Python es muy estricto. Por ejemplo, si escribes:
sum([1, 100])
101
te dará como resultado 101.
Pero si escribes:
Sum([1, 100])
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[11], line 1----> 1Sum([1, 100])
NameError: name 'Sum' is not defined
con la “s” en mayúscula, actuará como si no tuviera ni idea de lo que estamos hablando.
Guarda tu trabajo en objetos
Prácticamente cualquier cosa, incluyendo los resultados de cualquier función de Python, se puede guardar en un objeto.
Esto se logra usando el operador de asignación, que puede ser el símbolo de igual (=).
Puedes inventar cualquier nombre para un objeto de Python. Sin embargo, hay tres reglas básicas:
Debe ser diferente del nombre de una función en Python.
Debe ser lo más específico posible.
No debe contener espacios ni puntos.
Por ejemplo
# Este código asignará el número 18# al objeto llamado my_favorite_numbermi_numero_favorito =18
Tras ejecutar este código, no ocurre nada. Pero si ejecutamos el objeto por separado, podemos ver qué contiene.
mi_numero_favorito
18
También puedes usar print(mi_numero_favorito).
Listas
Hasta ahora hemos usado objetos de Python para almacenar un solo número. Pero en estadística trabajamos con variación, que por definición requiere más de un número.
Un objeto de Python también puede almacenar un conjunto completo de números, llamado lista.
Puedes pensar en una lista como un vector de números (o valores).
El comando [] se puede usar para combinar varios valores individuales en una lista.
Es importante saber que los números también pueden tratarse como caracteres, según el contexto.
Por ejemplo, cuando el número 20 se escribe entre comillas ("20"), se tratará como un carácter, aunque esté entre comillas.
Valores booleanos
Los valores booleanos son True o False.
Podríamos tener una pregunta como esta:
¿El primer elemento del vector many_greetings es "hola"?
Podemos pedirle a Python que lo averigüe y devuelva la respuesta True o False.
muchos_saludos[1] =="hola"
False
Operadores lógicos
La mayoría de las preguntas que le pedimos a Python que responda con True o False involucran operadores de comparación como >, <, >=, <= y ==.
El doble signo == comprueba si dos valores son iguales. Incluso existe un operador de comparación para comprobar si los valores no son iguales: !=.
Por ejemplo, 5 != 3 es una proposición True.
Operadores lógicos comunes
> (mayor que)
>= (mayor o igual que)
< (menor que)
<= (menor o igual que)
== (igual a)
!= (distinto de)
Pregunta
Lee este código y predice su respuesta. Luego, ejecuta el código en Google Colab y comprueba si acertaste.
A =1B =5comparacion = A > Bcomparacion
Cultura de la programación: Ensayo y error
La mejor manera de aprender a programar es experimentando y viendo qué sucede. Escribe código, ejecútalo y analiza por qué no funcionó.
Hay muchas maneras de cometer pequeños errores al programar (por ejemplo, escribir una mayúscula cuando se necesita una minúscula).
A menudo tenemos que encontrar estos errores mediante ensayo y error.
Librerías de Python
Las librerías son las unidades fundamentales del código Python reproducible. Incluyen funciones reutilizables, documentación sobre cómo usarlas y datos de ejemplo.
En este curso, trabajaremos principalmente con las siguientes librerías:
pandas para manipulación de datos
matplotlib y seaborn para visualización de datos
scipy y statsmodels para el análisis de datos
Lectura de Datos con Python
Carga de datos en Python
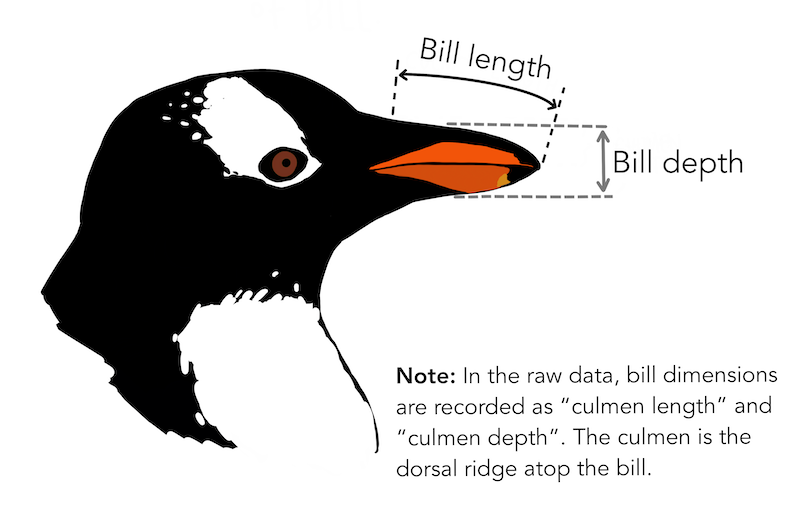
En este curso, asumiremos que los datos están almacenados en un archivo de Excel. Como ejemplo, utilizaremos el archivo penguins.xlsx.
El archivo debe haber sido subido previamente a Google Colab.
El conjunto de datos penguins.xlsx contiene información sobre pingüinos que viven en tres islas.
Librería pandas
pandas es una librería de Python de código abierto para la manipulación y el análisis de datos.
Está construida sobre numpy para operaciones de datos de alto rendimiento.
Permite al usuario importar, limpiar, transformar y analizar datos de forma eficiente.
El comando .head() nos permite imprimir las primeras seis filas del nuevo dataframe. Debemos eliminarlo para obtener el dataframe completo.
También podemos usar .filter() para seleccionar filas. Para ello, establecemos axis = 1. Podemos seleccionar filas específicas, como la 0 y la 10.
(penguins_data .filter([0, 10], axis =0))
species
island
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g
sex
year
0
Adelie
Torgersen
39.1
18.7
181.0
3750.0
male
2007
10
Adelie
Torgersen
37.8
17.1
186.0
3300.0
NaN
2007
O bien, podemos seleccionar un conjunto de filas usando la función range(). Por ejemplo, seleccionemos las primeras 5 filas.
(penguins_data .filter(range(5), axis =0))
species
island
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g
sex
year
0
Adelie
Torgersen
39.1
18.7
181.0
3750.0
male
2007
1
Adelie
Torgersen
39.5
17.4
186.0
3800.0
female
2007
2
Adelie
Torgersen
40.3
18.0
195.0
3250.0
female
2007
3
Adelie
Torgersen
NaN
NaN
NaN
NaN
NaN
2007
4
Adelie
Torgersen
36.7
19.3
193.0
3450.0
female
2007
Filtrado de filas con .query()
Una forma alternativa de seleccionar filas es mediante .query(). A diferencia de .filter(), .query() nos permite filtrar los datos utilizando sentencias o consultas que involucran las variables.
Por ejemplo, filtremos los datos de la especie “Gentoo”.
Incluso podemos combinar.filter() y .query(). Por ejemplo, seleccionemos las columnas species, body_mass_g y sex, y luego filtremos los datos para la especie “Gentoo”.
Con .assign(), podemos crear nuevas columnas (variables) que son funciones de las existentes. Esta función utiliza una palabra clave especial de Python llamada lambda. Técnicamente, esta palabra clave define una función anónima.
Por ejemplo, creamos una nueva variable LDRatio que es igual a la relación entre bill_length_mm y bill_depth_mm.
En este código, el df después de lambda indica que el dataframe (penguins_data) se denominará df dentro de la función. Los dos puntos : marcan el inicio de la función.
Un criminólogo está desarrollando un sistema basado en reglas para clasificar los tipos de vidrio encontrados en investigaciones criminales.
Los datos consisten en 214 muestras de vidrio etiquetadas en una de siete categorías.
Hay nueve predictores, incluyendo el índice de refracción y los porcentajes de ocho elementos: Na, Mg, Al, Is, K, Ca, Ba y Fe. La respuesta es el tipo de vidrio.
El conjunto de datos se encuentra en el archivo “glass.xlsx”. Vamos a cargarlo usando pandas.
# Cargar el archivo de Excel en un DataFrame de pandas.glass_data = pd.read_excel("glass.xlsx")
La variable Type es categórica. Por lo tanto, asegurémonos de que Python lo sepa usando el siguiente código.
Las librerías matplotlib y seaborn vienen preinstaladas en Google Colab. Sin embargo, debemos indicarle a Google Colab que queremos usarlas, junto con sus funciones, mediante el siguiente comando:
import matplotlib.pyplot as pltimport seaborn as sns
Al igual que con pandas, el comando as sns nos permite usar un nombre corto para seaborn. De forma similar, renombramos matplotlib como plt.
Histograma
Representación gráfica que muestra la distribución de la muestra, indicando las regiones donde se concentran los puntos y las regiones donde son menos numerosos.
Las barras del histograma se tocan. Un espacio indica que no hay observaciones en ese intervalo.
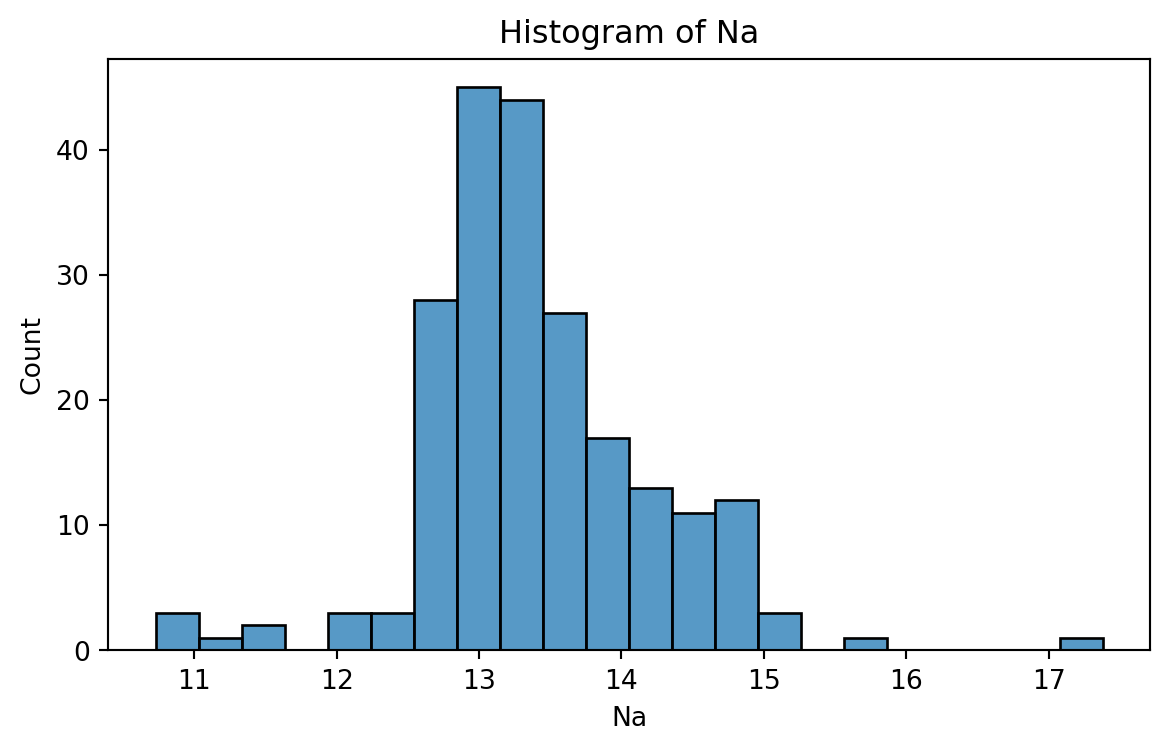
Histograma de Na
Para crear un histograma, utilizamos la función histplot() de seabron.
Code
plt.figure(figsize=(7,4)) # Crea espacio para la figura.sns.histplot(data = glass_data, x ='Na') # Crea el histograma.plt.title("Histogram of Na") # Título de la gráfica.plt.xlabel("Na") # Etiqueta del eje Xplt.show() # Muestra la Gráfica
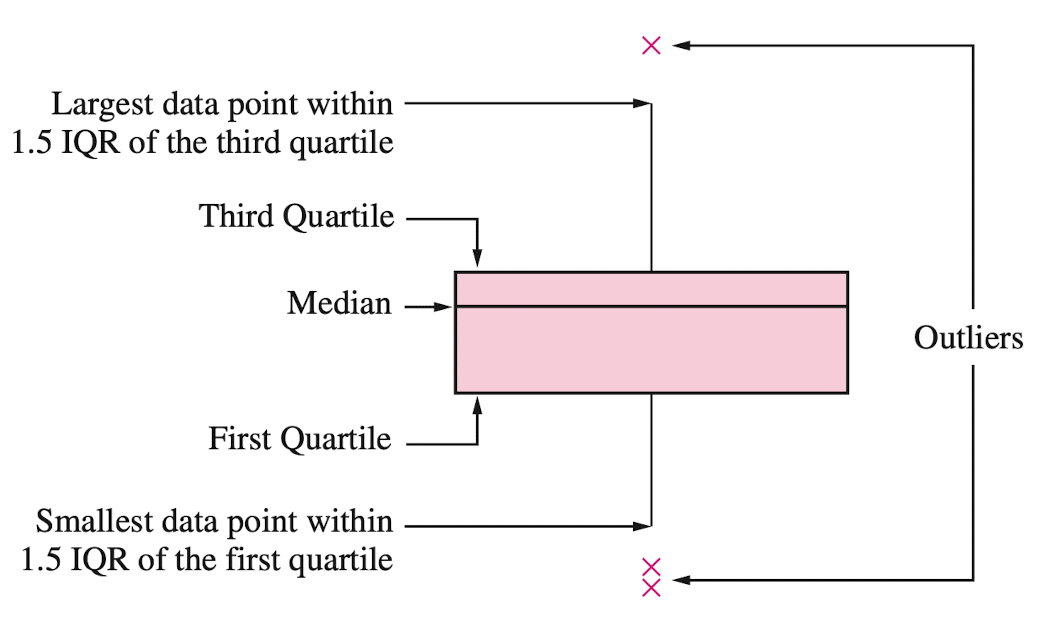
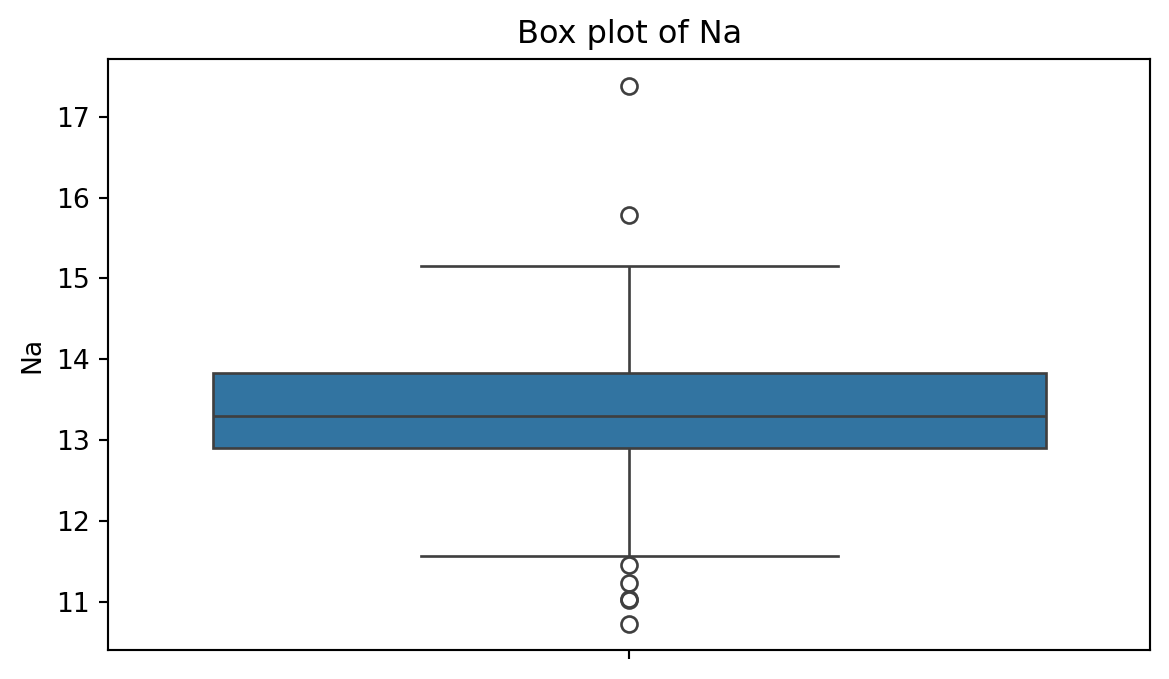
Gráfica de caja
Muestra la mediana, el primer y tercer cuartil, y cualquier valor “atípico” presente en la muestra.
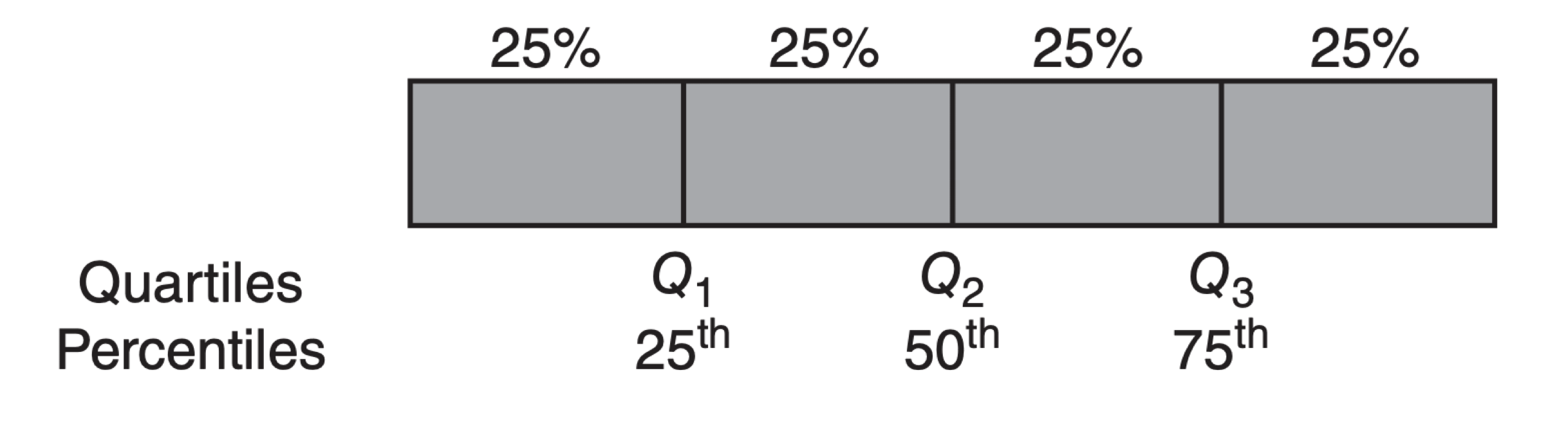
La mediana muestral es el valor central de los datos ordenados.
Los cuartiles de muestra dividen los datos en cuartiles lo más aproximado posible:
El primer cuartil (\(Q_1\)) es la mediana de la mitad inferior de los datos.
El segundo cuartil (\(Q_2\)) es la mediana o valor central de los datos.
El tercer cuartil (\(Q_3\)) es la mediana de la mitad superior de los datos.
En Python, los cuartiles se calculan utilizando la función quantile().
El rango intercuartil (RIC) es la diferencia entre el tercer cuartil y el primer cuartil (\(Q_3 - Q_1\)). Esta es la distancia necesaria para abarcar la mitad central de los datos.
Para crear una gráfica de caja, utilizamos la función boxplot() de seabron.
Code
plt.figure(figsize=(7,4)) # Create space for the figure.sns.boxplot(data = glass_data, y ='Na') # Create boxplot.plt.title("Box plot of Na") # Add title.plt.show() # Show the plot.
Valores atípicos
Los valores atípicos son puntos que son mucho mayores o menores que el resto de los puntos de la muestra.
Pueden deberse a errores de introducción de datos o a que realmente son diferentes del resto.
No se deben eliminar los valores atípicos sin una cuidadosa consideración; a veces, los cálculos y análisis se realizan con y sin valores atípicos, y luego se comparan.
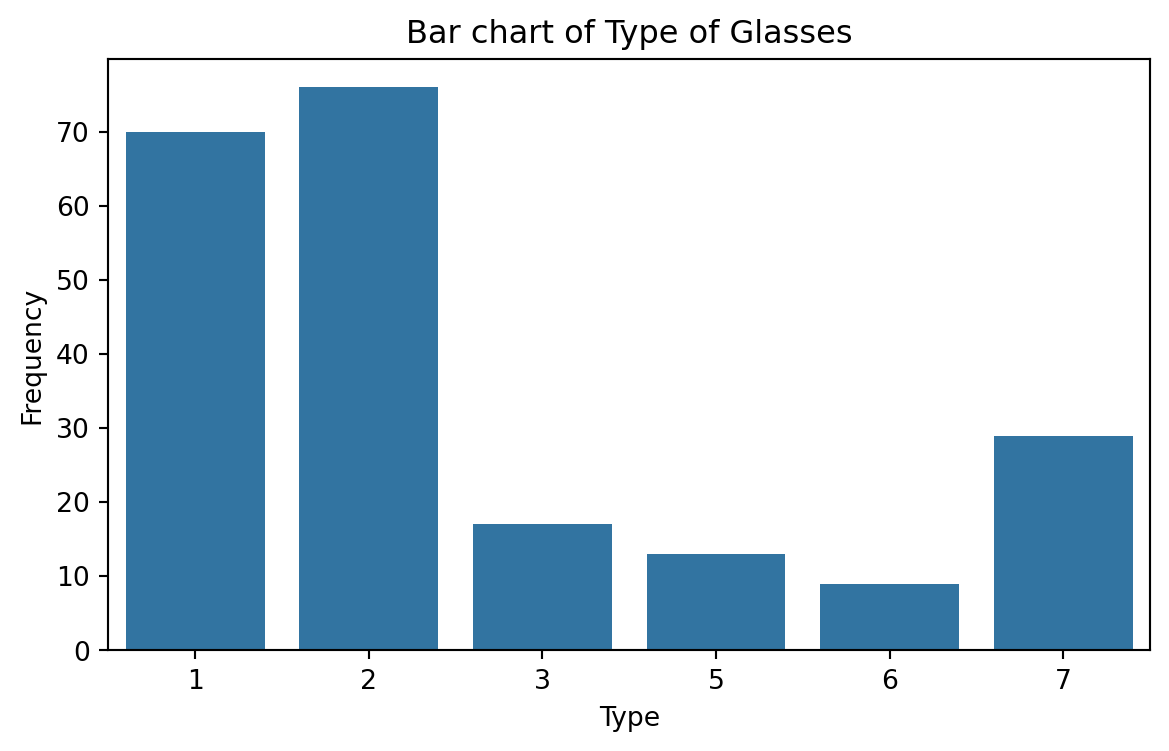
Gráfica de barras
Describe datos categóricos clasificados en diversas categorías según el sector, la región, diferentes periodos de tiempo u otros factores similares.
Los diferentes sectores, regiones o periodos de tiempo se etiquetan como categorías específicas.
Un gráfico de barras se construye creando categorías que se representan mediante etiquetas y que se representan mediante intervalos de igual longitud en un eje horizontal.
La frecuencia o el recuento dentro de la categoría correspondiente se representa mediante una barra cuya altura es proporcional a la frecuencia.
Creamos el gráfico de barras utilizando la función countplot() de seaborn.
Code
# Create plot.plt.figure(figsize=(7,4)) # Create space for the plot.sns.countplot(data = glass_data, x ='Type') # Show the plot.plt.title("Bar chart of Type of Glasses") # Set plot title.plt.ylabel("Frequency") # Set label for Y axis.plt.show() # Show plot.
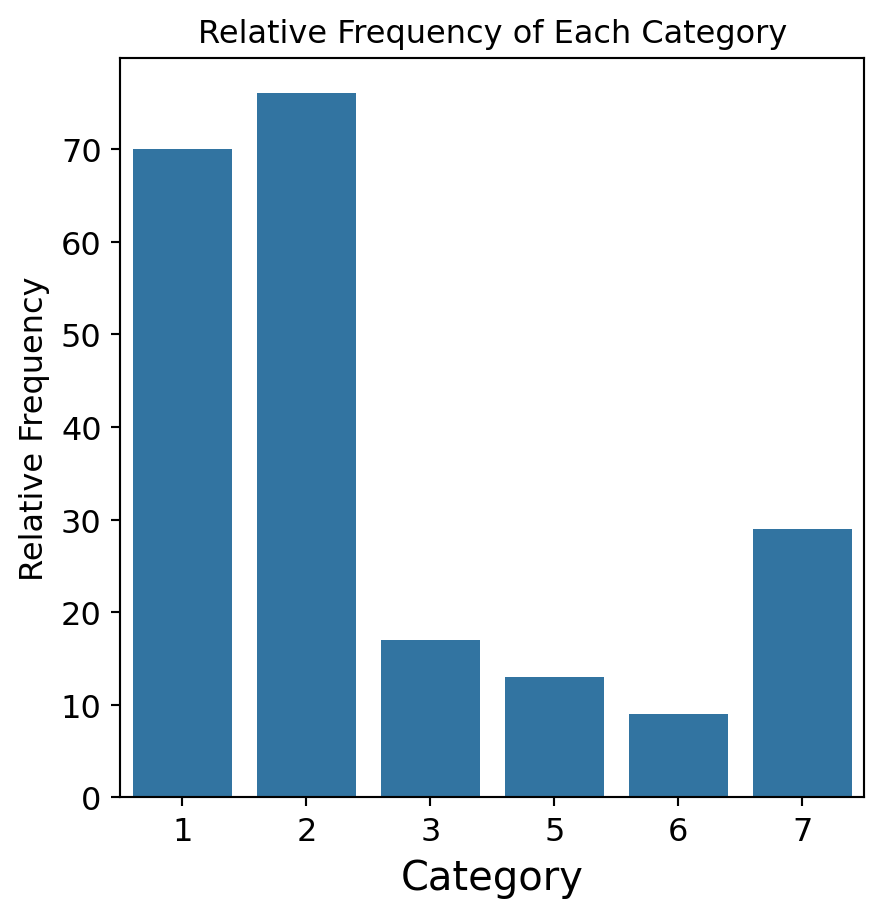
Guardar gráficos
Guardamos una figura usando la función .save.fig() de matplotlib. El argumento dpi de esta función establece la resolución de la imagen. Cuanto mayor sea el valor de dpi, mejor será la resolución.
plt.figure(figsize=(5, 7))sns.countplot(data = glass_data, x ='Type')plt.title('Frequency of Each Category')plt.ylabel('Frequency')plt.xlabel('Category')plt.savefig('bar_chart.png',dpi=300)
Mejorando la figura
También podemos usar otras funciones para mejorar el aspecto de la figura:
plt.title(fontsize): Tamaño de fuente del título.
plt.ylabel(fontsize): Tamaño de fuente del título del eje Y.
plt.xlabel(fontsize): Tamaño de fuente del título del eje X.
plt.yticks(fontsize): Tamaño de fuente de las etiquetas del eje Y.
plt.xticks(fontsize): Tamaño de fuente de las etiquetas del eje X.
plt.figure(figsize=(5, 5))sns.countplot(data = glass_data, x ='Type')plt.title('Relative Frequency of Each Category', fontsize =12)plt.ylabel('Relative Frequency', fontsize =12)plt.xlabel('Category', fontsize =15)plt.xticks(fontsize =12)plt.yticks(fontsize =12)plt.savefig('bar_chart.png',dpi=300)