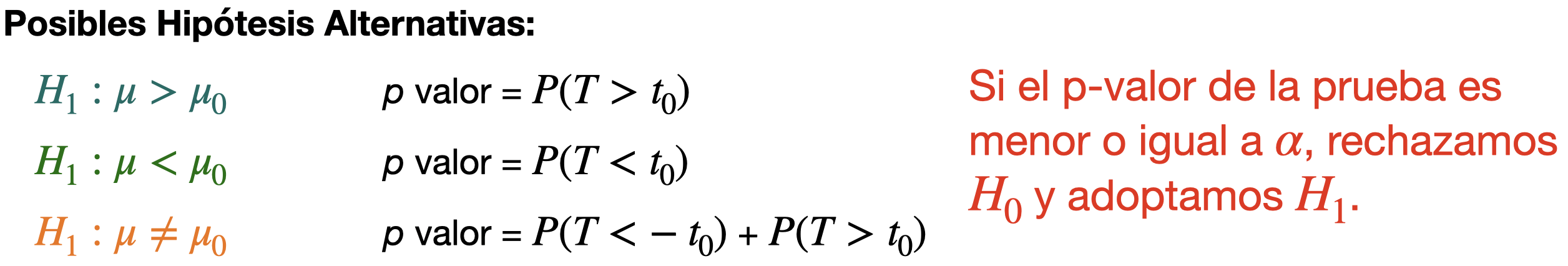Antes de empezar, carguemos las librerías que usaremos hoy.
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy.stats import ttest_ind, ttest_1samp
En el cógido de arriba, indicamos que utilizaremos las funciones ttest_ind() y ttest_1samp() de la librería scipy.stats.
Conceptos Básicos
Introducción
Recuerda que el objetivo de la estadística es hacer inferencias sobre parámetros poblacionales desconocidos basándose en la información contenida en los datos de la muestra.
Estas inferencias se expresan de dos maneras:
Intervalos de confianza de un parámetro.
Prueba de hipótesis sobre su valor.
Idea general
Consideremos una población (distribución) en estudio con un parámetro objetivo. Una prueba de hipótesis sigue los pasos generales siguientes.
Plantear una hipótesis sobre el parámetro. Por ejemplo, equivale a un valor especificado por el usuario.
Recolectar una muestra de la población y comparar los valores observados con la hipótesis.
Si las observaciones no están de acuerdo con la hipótesis, la rechazamos. De lo contrario, concluimos que la hipótesis es verdadera o que la muestra no proporcionó suficiente información para la prueba.
Paso 1. Hipótesis
Una hipótesis es una afirmación sobre un parámetro de población.
Hay dos tipos de hipótesis:
La hipótesis nula se denota con \(H_0\).
La hipótesis alternativa se denota con \(H_1\).
Para un parámetro objetivo \(\mu\) y un valor hipotético (especificado por el usuario) \(\mu_0\), nos concentraremos en hipótesis del siguiente tipo:
\(H_0: \mu = \mu_0\) contra \(H_1: \mu \neq \mu_0\)
\(H_0: \mu \leq \mu_0\) contra \(H_1: \mu > \mu_0\)
\(H_0: \mu \geq \mu_0\) contra \(H_1: \mu < \mu_0\)
La hipótesis alternativa es la hipótesis que buscamos sustentar con base en la información contenida en la muestra.
A veces, también escribimos la hipótesis nula de esta manera:
\(H_0: \mu = \mu_0\) contra \(H_1: \mu \neq \mu_0\)
\(H_0: \mu = \mu_0\) contra \(H_1: \mu > \mu_0\)
\(H_0: \mu = \mu_0\) contra \(H_1: \mu < \mu_0\)
Esto es como asumir el valor más extremo posible de \(\mu\) bajo \(H_0\).
Es decir, el valor mínimo (o máximo) para que \(H_0\) sea verdadera.
Ejemplo 1
Pregunta de investigación 1: ¿El alquiler mensual promedio de un apartamento de un dormitorio en la zona Tec es mayor a 15,000 pesos? \(H_0: \mu \leq 15,000\) contra \(H_1: \mu > 15,000\), donde \(\mu\) es el alquiler mensual promedio de todos los apartamentos de un dormitorio en la zona Tec.
Pregunta de investigación 2: ¿La mayoría de los estudiantes del campus del Tec tienen un perro? \(H_0: p = 0.5\) contra \(H_1: p > 0.5\), donde \(p\) es la proporción de todos de estudiantes que poseen un perro.
Paso 2. Muestra y Estadístico de Prueba
Normalmente, una prueba de hipótesis se especifica en términos de estadístico de prueba\(T\).
Un estadístico de prueba es una función de la muestra \(Y_1, \ldots, Y_n\), en la que se basará la decisión estadística. Por tanto, también es una variable aleatoria.
Una estadístico de prueba tiene una distribución de probabilidad asociada, que depende de la hipótesis asumida (\(H_0\) o \(H_1\)).
Ejemplo: Prueba de hipótesis sobre la media
Considera una muestra pequeña \(y_1, \ldots, y_n\)que se distribuye como \(N(\mu, \sigma^2)\).
Hipótesis nula: \(H_0: \mu = \mu_0\) donde \(\mu\) es un valor (constante) elegido por el usuario.
Posibles Hipótesis Alternativas:
\(H_1: \mu > \mu_0\)
\(H_1: \mu < \mu_0\)
\(H_1: \mu \neq \mu_0\)
Estadístico de Prueba:
\(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) donde \(\bar{y}\) y \(s\) son el promedio y desviación estándar de la muestra observada.
Distribución del estadístico de prueba
Si \(H_0: \mu = \mu_0\) es verdadera, \(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) sigue una distribución \(t\) con \(n-1\) grados de libertad.
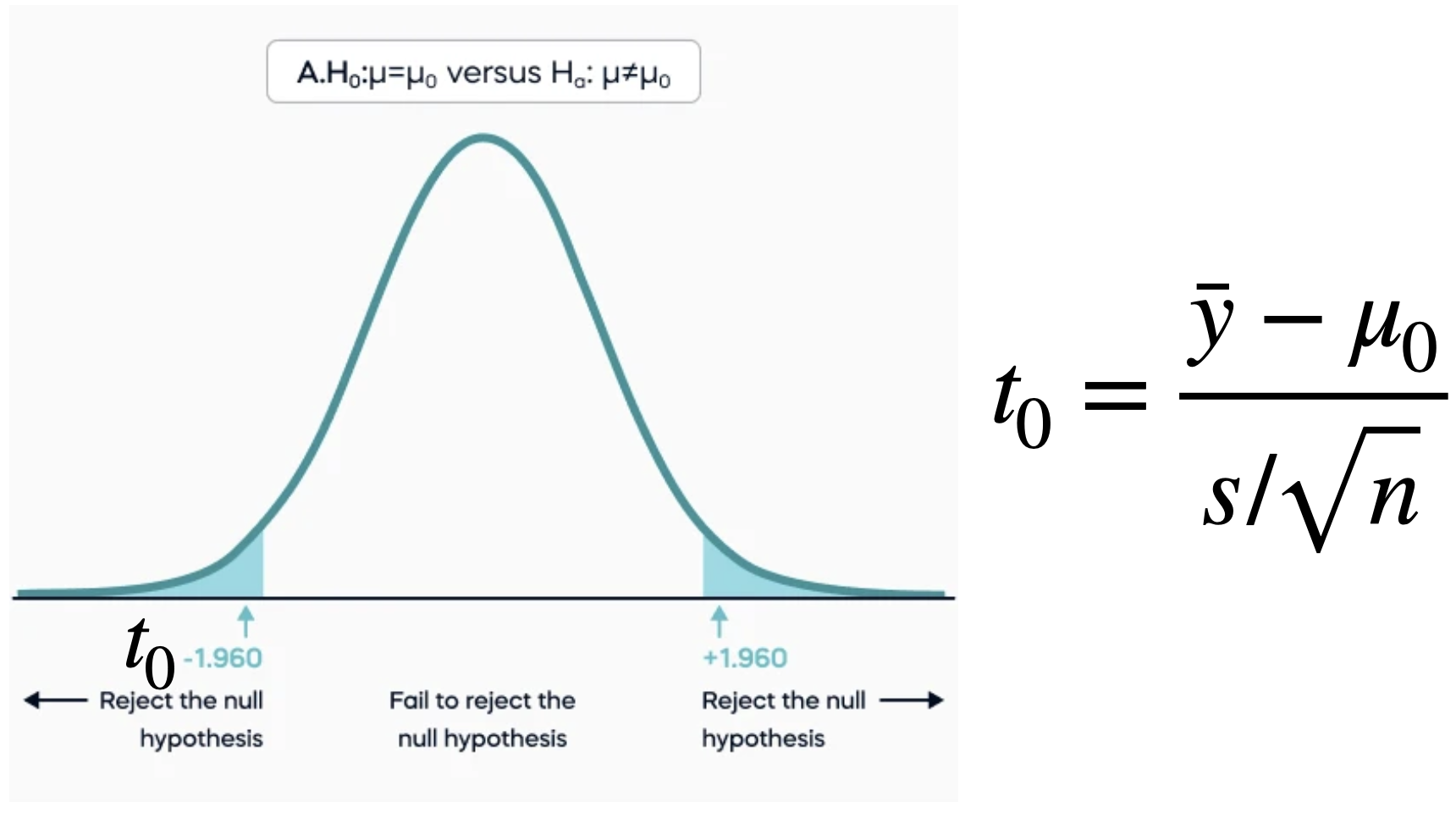
Paso 3. Rechazar o no rechazar \(H_0\)
Al realizar una prueba de hipótesis, existen dos decisiones posibles: rechazarono rechazar\(H_0\).
Para ello, comprobamos si el valor observado del estadístico de prueba es poco o muy probable asumiendo que \(H_0\) es verdadera.
Si \(H_0: \mu = \mu_0\) es verdadera, \(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) sigue una distribución \(t\) con \(n-1\) grados de libertad.
Si \(H_0\) es verdad, \(t_0\) debería de estar cerca de 0, el valor con más densidad de la distribución \(t\).
Si \(H_0: \mu = \mu_0\)no es verdadera, entonces \(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) deberá estar lejos de 0, el valor con más densidad de la distribución \(t\).
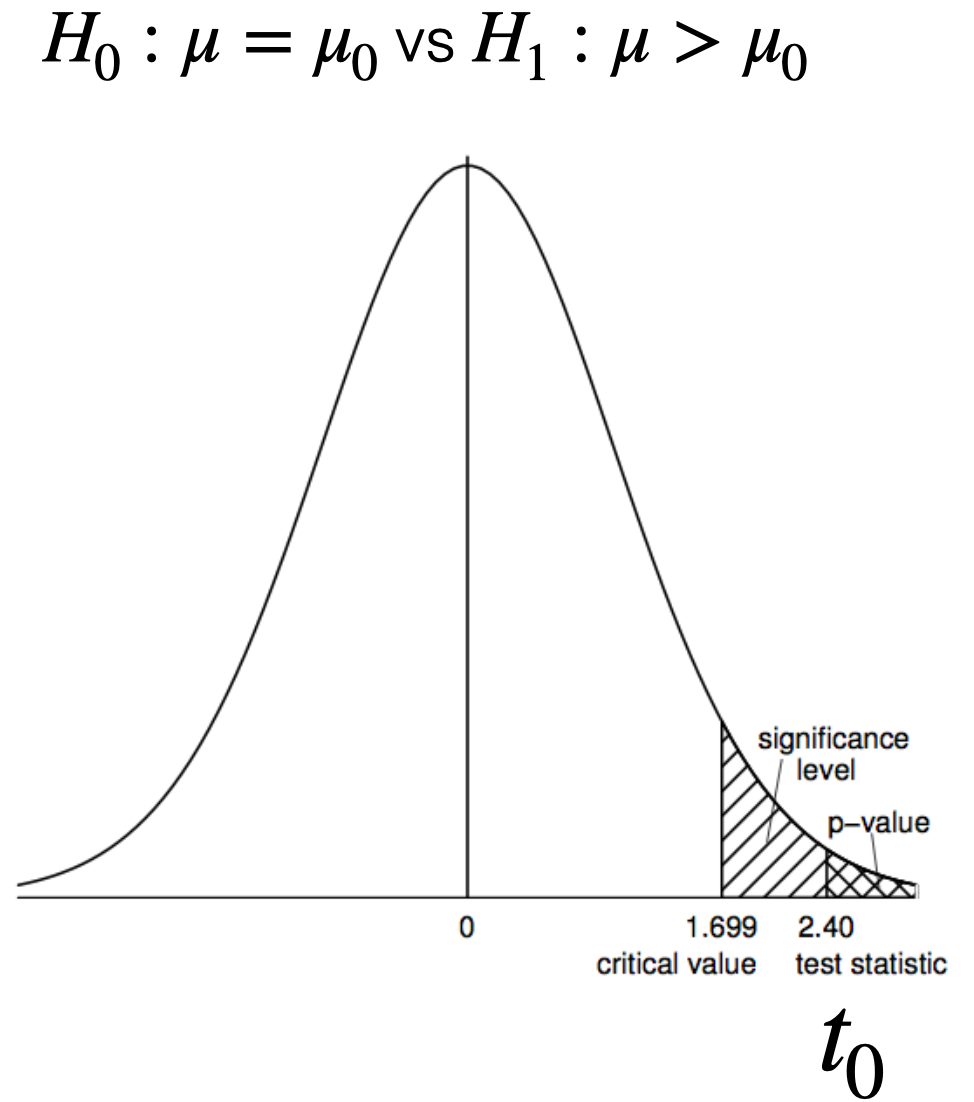
Por ejemplo, si \(H_1: \mu > \mu_0\) es verdad, entonces \(t_0\) debería de estar lejos de 0 hacia la derecha. En otras palabras, \(t_0\) es poco probable asumiendo que \(H_0\) es verdadera.
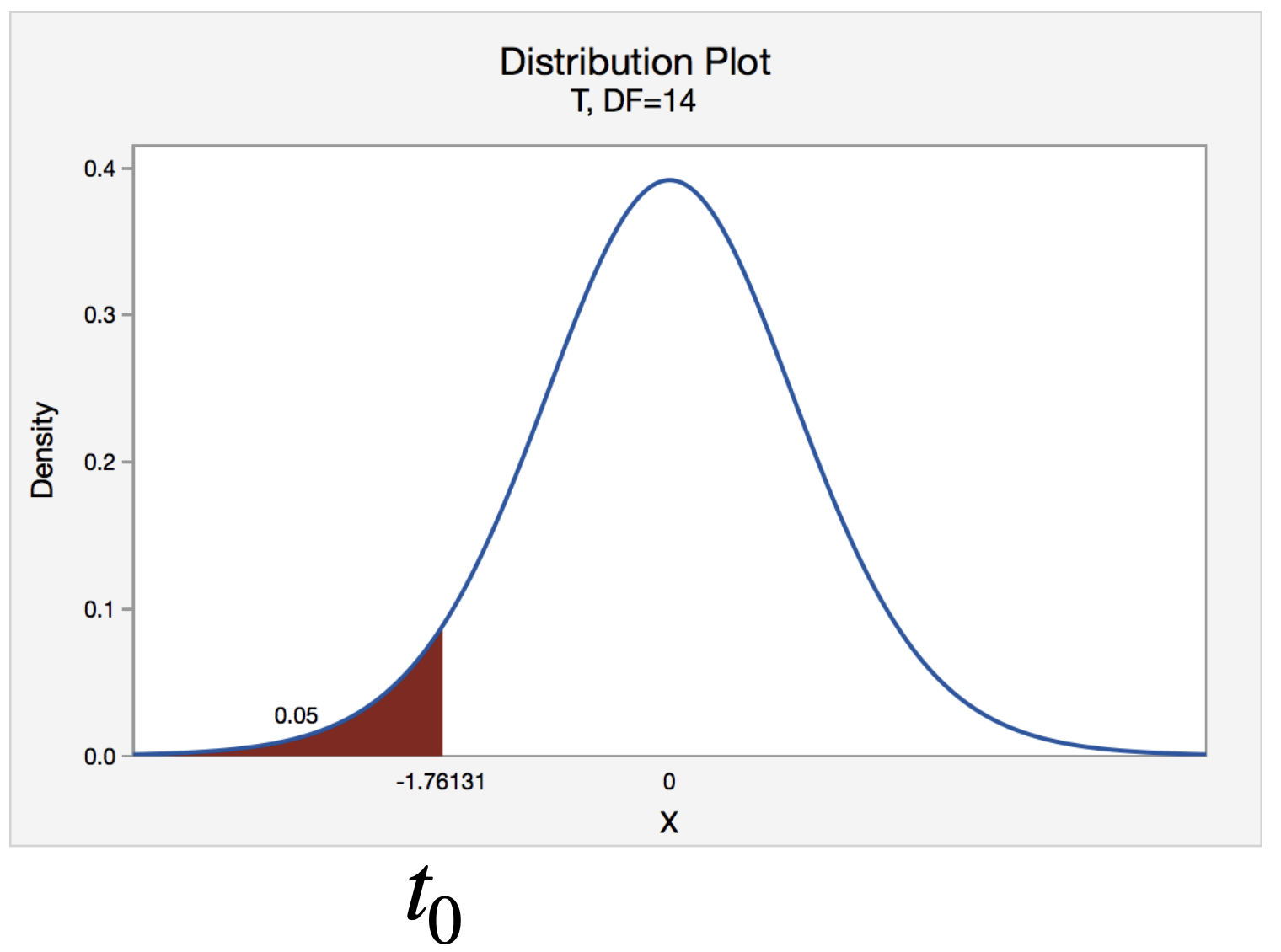
Valor p
Definición: El valor p es la probabilidad de observar un valor al menos tan extremocomo el valor observado de un estadístico\(T,\) cuando \(H_0\) es verdadera.
Un p-valor pequeño es equivalente a decir que \(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) esta “lejos” de 0.
Sugiriendo que la hipótesis nula \(H_0\) no es verdadera.
Para \(H_0: \mu = \mu_0\) vs \(H_1: \mu < \mu_0\), el p-valor se calcula usando la cola izquierda de la distribución \(t\).
De la misma manera, un p-valor pequeño es equivalente a decir que \(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) esta “lejos” de 0.
Sugiriendo que la hipótesis nula \(H_0\) no es verdadera.
Para \(H_0: \mu = \mu_0\) vs \(H_1: \mu \neq \mu_0\), el p-valor se calcula usando las dos colas de la distribución \(t\).
Usamos las dos colas porque la hipótesis alternativa se enfoca en una diferencia entre el valor real \(\mu\) y el asumido \(\mu_0\) si importar si esta diferencia es positiva o negativa.
El valor p no es la probabilidad de que \(H_0\) sea cierta
Dado que el valor p es una probabilidad, y dado que los valores p pequeños indican que es poco probable que \(H_0\) sea cierta, es tentador pensar que el valor p representa la probabilidad de que \(H_0\) sea cierta.
¡Este no es el caso!
El concepto de probabilidad que se analiza aquí sólo es útil cuando se aplica a resultados que pueden producirse de diferentes maneras cuando se repiten los experimentos.
¿Qué tan pequeño debe de ser el p valor para rechazar \(H_0\)?
Respuesta: ¡Muy pequeño!
Pero, ¿qué tan pequeño?
Respuesta: ¡Muy pequeño!
Pero, dime ¿qué tan pequeño?
Respuesta: Esta bien! Debe de ser menor que un valor llamado \(\alpha\) el cual suele ser 0.1, 0.05, o 0.01.
Siempre que el valor p es inferior al valor fijado de \(\alpha\), se dice que el resultado es “estadísticamente significativo” en ese nivel.
Es decir, si \(\alpha = 0.05\) y el p valor es menor que \(\alpha\), el resultado es estadísticamente significativo en el nivel 5%.
Y si \(\alpha = 0.01\) y el p valor es menor que \(\alpha\), el resultado es estadísticamente significativo al nivel 1%.
Resumen
Los elementos de una prueba estadística son:
Hipótesis nula, \(H_0\).
Hipótesis alternativa, \(H_1\).
Estadístico de prueba.
Región de rechazo.
Pruebas de Muestras Pequeñas
Prueba de hipótesis sobre la media
Considera una muestra pequeña \(y_1, \ldots, y_n\)que se distribuye como \(N(\mu, \sigma^2)\).
Hipótesis nula: \(H_0: \mu = \mu_0\) donde \(\mu\) es un valor (constante) elegido por el usuario.
Estadístico de Prueba: \(t_0 = \frac{\bar{y} - \mu_0}{s/\sqrt{n}}\) donde \(\bar{y}\) y \(s\) son el promedio y desviación estándar de la muestra observada.
Sea \(T\) una variable aleatoria que sigue una distribución \(t\) con \(n-1\) grados de libertad.
Ejemplo 3
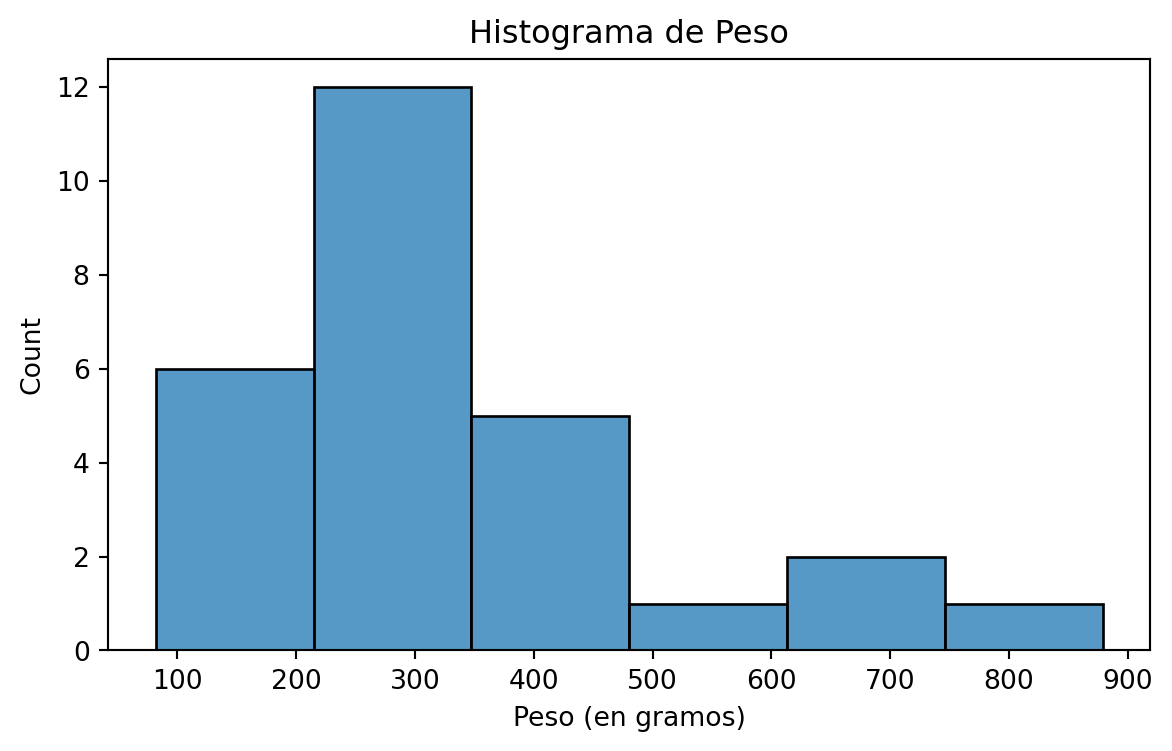
Una bióloga estudia el peso corporal (en gramos) de cobayas al nacer. Ella recolectó una muestra de pesos de 27 cobayas recien nacidas. Los datos están en el archivo “Guinea_Pigs.xlsx” en CANVAS.
La bióloga quiere probar la hipótesis de que el peso corporal medio es menor a 300 gramos. Técnicamente, quiere probar la hipótesis:
\(H_0: \mu = 300\) contra \(H_1: \mu < 300\)
Donde \(\mu\) es la media o promedio teórico de los pesos de todas las cobayas recien nacidas. Utiliza \(\alpha = 0.05\).
En Python
Primero, leamos los datos en el archivo “Guinea_Pigs.xlsx”.
plt.figure(figsize=(7,4)) sns.histplot(data = guinea_data, x ='Weight') plt.title("Histograma de Peso") plt.xlabel("Peso (en gramos)") plt.show()
Para llevar a cabo una prueba de hipótesis de una muestra, usamos la función ttest_1samp de scipy.stats. En la función, el parámetro popmean especifica e valor asumido \(\mu_0\) en \(H_0\). Además, el parámetro alternative indica el tipo de \(H_1\).
hip_test = ttest_1samp(guinea_data, popmean =300, alternative ='less')
En este caso, \(H_0: \mu = 300\) contra \(H_1: \mu < 300\). Entonces popmean = 300 y alternative = 'less'.
Usando hip_test, podemos preguntar sobre el p-valor de la prueba de hipótesis como sigue.
hip_test.pvalue
array([0.74450596])
Como el p-valor es mayor que \(\alpha=0.05\), no rechazamos\(H_0\). En otras palabras, concluimos que la muestra no nos da información suficiente para decir que el promedio teórico de las cobayas recién nacidas es menor a 300.
Intervalo de confianza
Usando el mismo objeto hip_test, también podemos obtener un intervalo de confianza usando la función .confidence_interval().
ci = hip_test.confidence_interval(confidence_level=0.95)ci
En este caso, el intervalo de confianza es de un solo lado ya que usamos \(H_1: \mu < 300\). En este caso, el intervalo de confianza del 95% es \([-\infty, 390.74]\) o \(\mu \leq 390.74\).
Mas sobre la función ttest_1samp()
Para probar diferentes hipótesis como \(H_0: \mu = 300\) contra \(H_1: \mu > 300\), fijamos el parametro alternative = 'greater'.
ttest_1samp(guinea_data, popmean =300, alternative ='greater')
Para probar \(H_0: \mu = 300\) contra \(H_1: \mu \neq 300\), fijamos el parametro alternative = 'two-sided'.
ttest_1samp(guinea_data, popmean =300, alternative ='two-sided')
Pruebas para la diferencia de dos medias
Recuerda que si la muestra aleatoria \(Y_1, \ldots, Y_{n_y}\) sigue una distribución \(N(\mu_y, \sigma_{y}^2)\), entonces \(\bar{Y} \sim N\left(\mu_y, \frac{\sigma_{y}^2}{n_y}\right)\).
Además, si la muestra aleatoria \(X_1, \ldots, X_{n_x}\) sigue una distribución \(N(\mu_x, \sigma_{x}^2)\), entonces \(\bar{X} \sim N\left(\mu_x, \frac{\sigma_{x}^2}{n_x}\right)\).
El esquema
Para definir los intervalos de confianza, necesitamos definir lo siguiente:
Para la primera muestra de observaciones \(y_1, y_2, \ldots, y_{n_y}\):
\(n_y\) es el número de observaciones.
\(\bar{y} = \frac{1}{n_y}\sum_{i=1}^{n_y} y_i\) es la media muestral.
\(s^2_y =\frac{1}{n_y-1} \sum_{i=1}^{n_y} (y_i - \bar{y})^2\) es la varianza muestral.
Para la segunda muestra de observaciones \(x_1, x_2, \ldots, x_{n_x}\):
\(n_x\) es el número de observaciones.
\(\bar{x} = \frac{1}{n_x}\sum_{i=1}^{n_x} x_i\) es la media muestral.
\(s^2_{x} =\frac{1}{n_x -1} \sum_{i=1}^{n_x} (x_i - \bar{x})^2\) es la varianza muestral.
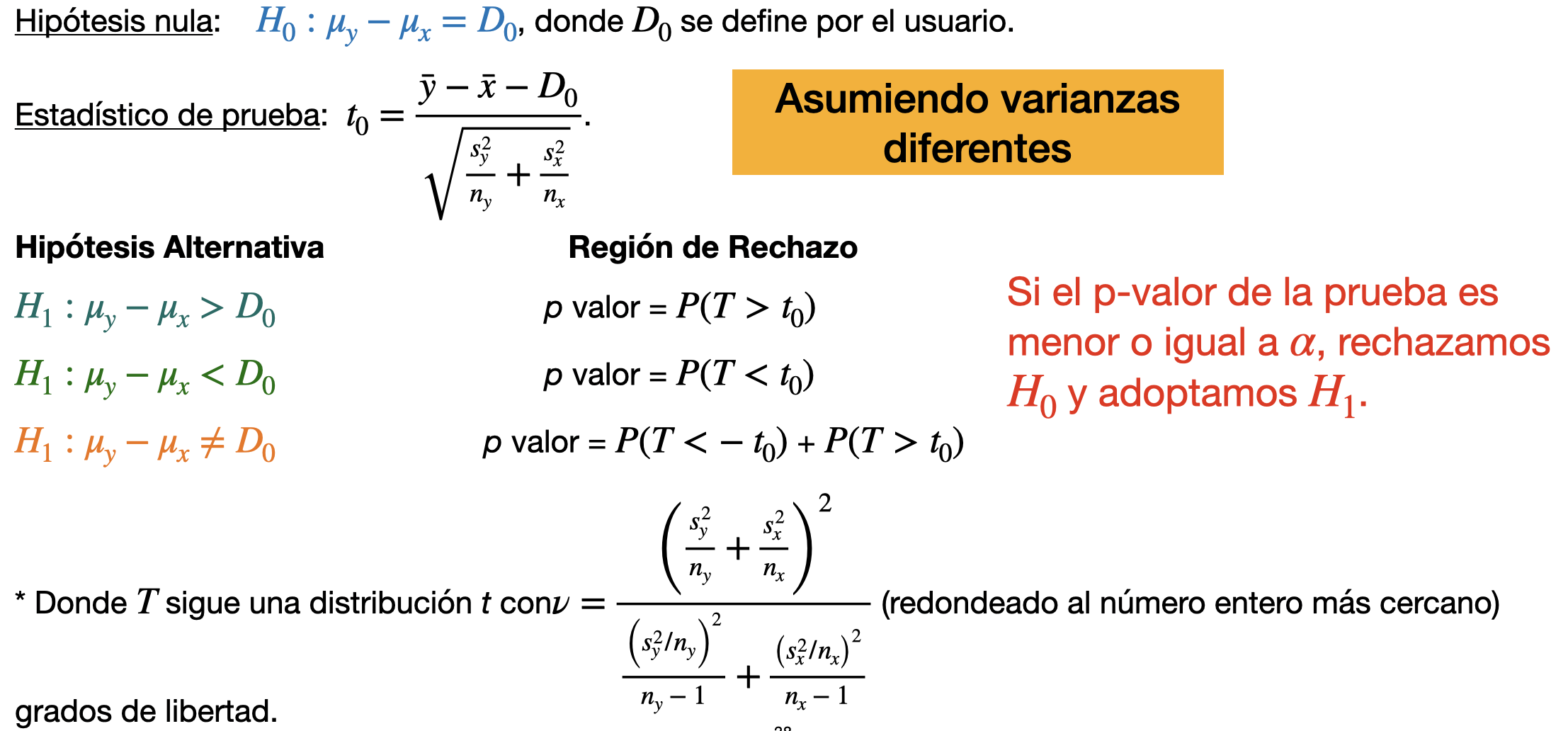
Si las dos muestras son independientes, entonces un estadístico de prueba para la hipótesis sobre \(\mu_y - \mu_x\) es
La resistencia a la rotura de los ejes de los palos de hockey fabricados con dos compuestos diferentes de grafito arroja los siguientes resultados (en newtons):
donde \(\mu_R\) y \(\mu_B\) son los promedios teóricos de rotura de los palos de hockey producidos por el compuesto R y B, respectivamente. Usa \(\alpha = 0.05\).
En Python
Antes de empezar, carguemos los datos que están en el archivo “Hockey.xlsx”
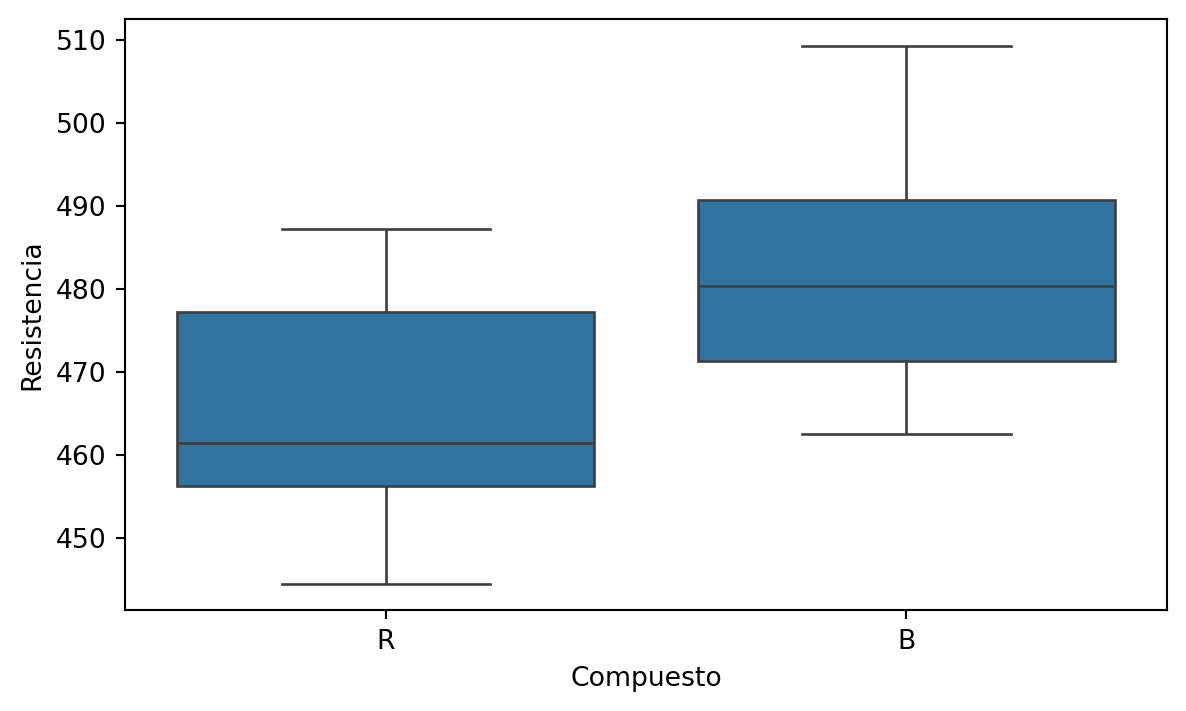
Podemos visualizar los datos de los dos grupos definidos por los compuestos R y B usando gráficas de cajas lado a lado.
Code
plt.figure(figsize=(7,4)) sns.boxplot(data = hockey_data, x ='Compuesto', y ='Resistencia') plt.ylabel("Resistencia") plt.xlabel("Compuesto") plt.show()
Configuración
Un problema con los datos actuales es que no están en el formato requerido para la función de Python que construye intervalos de confianza. Está función necesita que los datos de los dos grupos estén en dos columnas separadas.
Sin embargo, podemos crear las dos columnas con nuestras funciones de pandas.
Para llevar a cabo una prueba de hipótesis de dos muestras, usamos la función ttest_ind de scipy.stats. En la función, el parámetro alternative indica el tipo de \(H_1\). En este caso, alternative = 'two-sided' ya que \(H_1: \mu_R \neq \mu_B\).
prueba_hip = ttest_ind(Res_CompR, Res_CompB, alternative ='two-sided', equal_var =False)
Recuerda que el parámetro equal_var indica si asumimos que las varianzas son iguales o diferentes. Asumamos que son diferentes.
Usando prueba_hip, podemos preguntar sobre el p-valor de la prueba de hipótesis como sigue.
prueba_hip.pvalue
array([0.00812422])
Como el p-valor es menor que \(\alpha=0.05\), rechazamos\(H_0\).
En otras palabras, concluimos que la muestra nos da información suficiente para decir que los promedios de resistencia de los palos de hockey bajo los dos compuestos es diferente.
Intervalo de confianza
Recuerda que podemos obtener un intervalo de confianza usando .confidence_interval().
ci = prueba_hip.confidence_interval(confidence_level =0.95)ci
El intervalo es \([-30.82, -5.35]\) o \(-30.82 \leq \mu_R - \mu_B \leq -5.35\).
Esto lo sabemos por el orden en que especificamos las muestras en
ttest_ind(Res_CompR, Res_CompB, alternative = 'two-sided', equal_var = False)
p-valores para otros pares de hipótesis
Para probar las hipótesis \(H_0: \mu_R = \mu_B \text{ contra } H_1: \mu_R < \mu_B\), usamos:
prueba_hip = ttest_ind(Res_CompR, Res_CompB, alternative ='less', equal_var =False)
Para probar las hipótesis \(H_0: \mu_R = \mu_B \text{ contra } H_1: \mu_R > \mu_B\), usamos:
prueba_hip = ttest_ind(Res_CompR, Res_CompB, alternative ='greater', equal_var =False)
No asumas que las varianzas son iguales
El supuesto de que las varianzas teóricas de las distribuciones son iguales es muy estricto.
El método puede resultar poco fiable si se utiliza cuando las varianzas teóricas no son iguales.
Como normalmente no conocemos las varianzas, suele ser imposible estar seguro de que sean iguales.
Solución: La mejor práctica es asumir que las varianzas son desiguales a menos que esté bastante seguro de que son iguales.
Comentarios Finales
Significativo no implica importante
En el uso común, la palabra significativo significa “importante”.
Por tanto, resulta tentador pensar que los resultados estadísticamente significativos siempre deben ser importantes. Este no es el caso.
A veces, los resultados estadísticamente significativos no tienen ninguna importancia científica o práctica. En otras palabras, no son prácticamente significativos.
Conclusión de los resultados
Las únicas dos conclusiones a las que se puede llegar en una prueba de hipótesis son:
Rechazamos\(H_0\). En otras palabras, concluimos que \(H_0\) es falsa.
No rechazamos\(H_0\). En otras palabras, \(H_0\) es plausible. Nunca podemos concluir que \(H_0\) sea cierto. Podemos simplemente concluir que \(H_0\) podría ser plausible.
Debemos decidir si el nivel de desacuerdo, medido con el valor p, es lo suficientemente grande como para hacer que la hipótesis nula sea inverosímil.
Elije \(H_1\) para responder la pregunta
Al realizar una prueba de hipótesis, es importante elegir \(H_0\) y \(H_1\) apropiadamente para que el resultado de la prueba pueda ser útil para llegar a una conclusión.
Recordemos que lo que nos importa es la hipótesis alternativa\(H_1\).
Por ejemplo, en aplicaciones médicas, las pruebas de hipótesis se utilizan para comprobar el efecto de un nuevo tratamiento. Esto se afirma en \(H_1\), mientras que \(H_0\) afirma que el tratamiento no tiene ningún efecto.
Preguntas de práctica para examen
Se realizó un experimento para determinar la viscosidad del aceite de auto de dos diferentes marcas, A y B. Los resultados de las mediciones de viscosidad se muestran abajo:
Marca A
10.28
10.27
10.30
10.32
10.27
10.27
10.28
10.29
Marca B
10.31
10.31
10.26
10.30
10.27
10.31
10.29
10.26
Prueba la hipótesis \(H_0: \mu_A = \mu_B\) contra \(H_0: \mu_A \neq \mu_B\) usando \(\alpha = 0.05\). Asume que las observaciones siguen una distribución normal para cada grupo, y que las varianzas de estas distribuciones son diferentes.