Introduction to Multivariate Data
Multivariate data
Multivariate data consists of datasets that contain observations of two or more variables.
In fact, the goal is to determine whether there is a relationship between the variables and the type of relationship.
Example 1
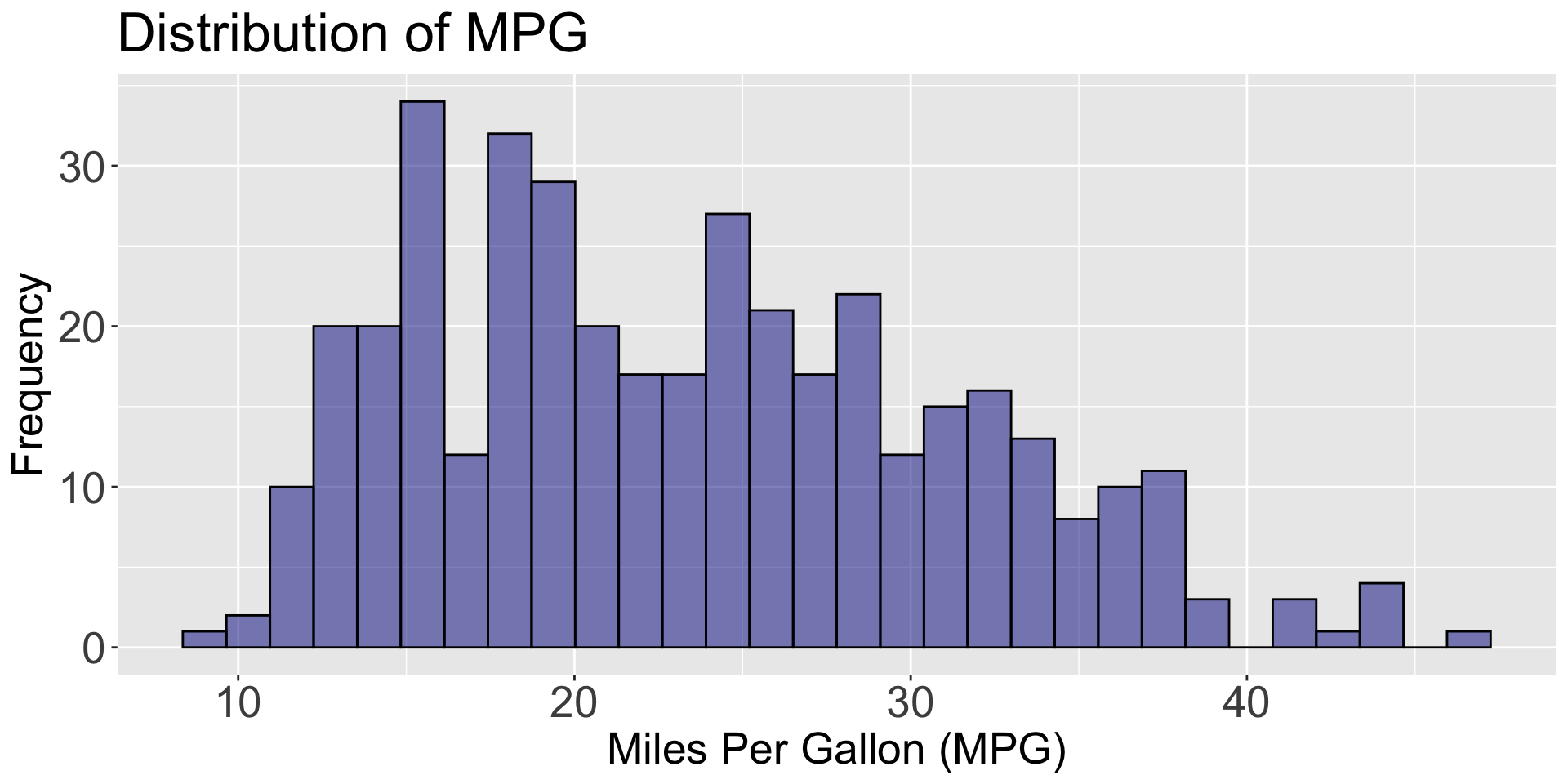
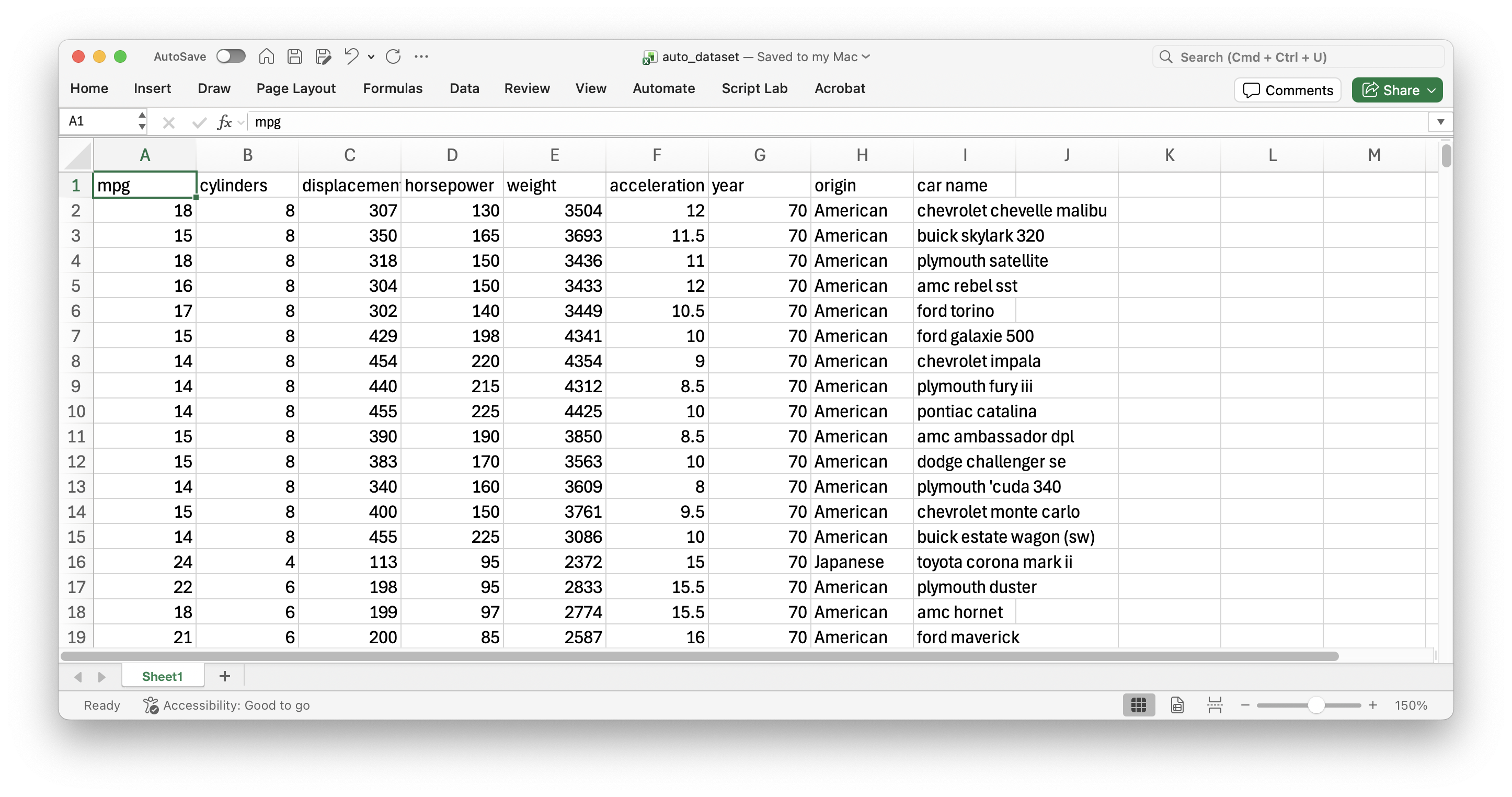
Consider data from 392 cars, including miles per gallon, number of cylinders, horsepower, weight, acceleration, year, origin, among other variables. The data is in the file “auto_dataset.xlsx”.
![]()
Principle 1: Define the question
In the context of multiple-variable data, typical questions to study include:
How are variable \(X\) and variable \(Y\) related?
Is the distribution of variable \(X\) the same across all subgroups defined by variable \(Z\)?
Are there any unusual observations in the combination of values for variables \(X\) and \(Y\)?
Are there any unusual observations in \(X\) for a subgroup of variable \(Z\)?
Independent and dependent variables
When investigating the relationship between two variables (numerical or categorical), we use specific terminology.
One variable is called the dependent or response variable, denoted by the letter \(Y\).
The other variable is called the independent or predictor variable, denoted by the letter \(X\).
Our goal is to determine whether changes in \(X\) are associated with changes in \(Y\), and the nature of this association.
Scatter plot
The most common graph for examining the relationship between two numerical variables is the scatter plot.
Variables \(X\) and \(Y\) are placed on the horizontal and vertical axes, respectively. Each point on the graph represents a pair of \(X\) and \(Y\) values.
The goal is to explore linear or non-linear relationships between variables.
Individual graphs
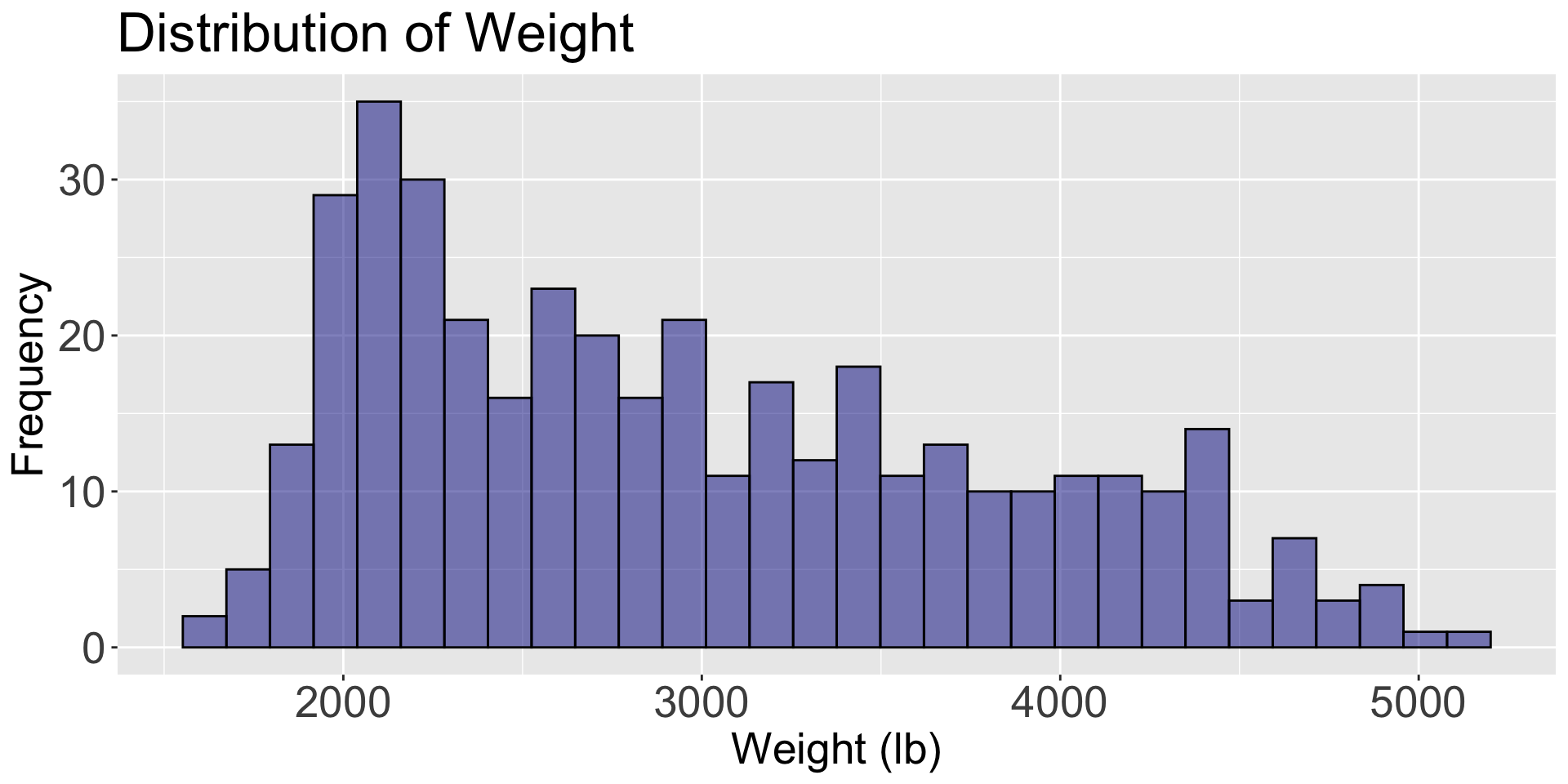
Individual variable graphs (such as histograms) do not allow us to study the relationship between two variables. They only provide information on the distribution of each variable.
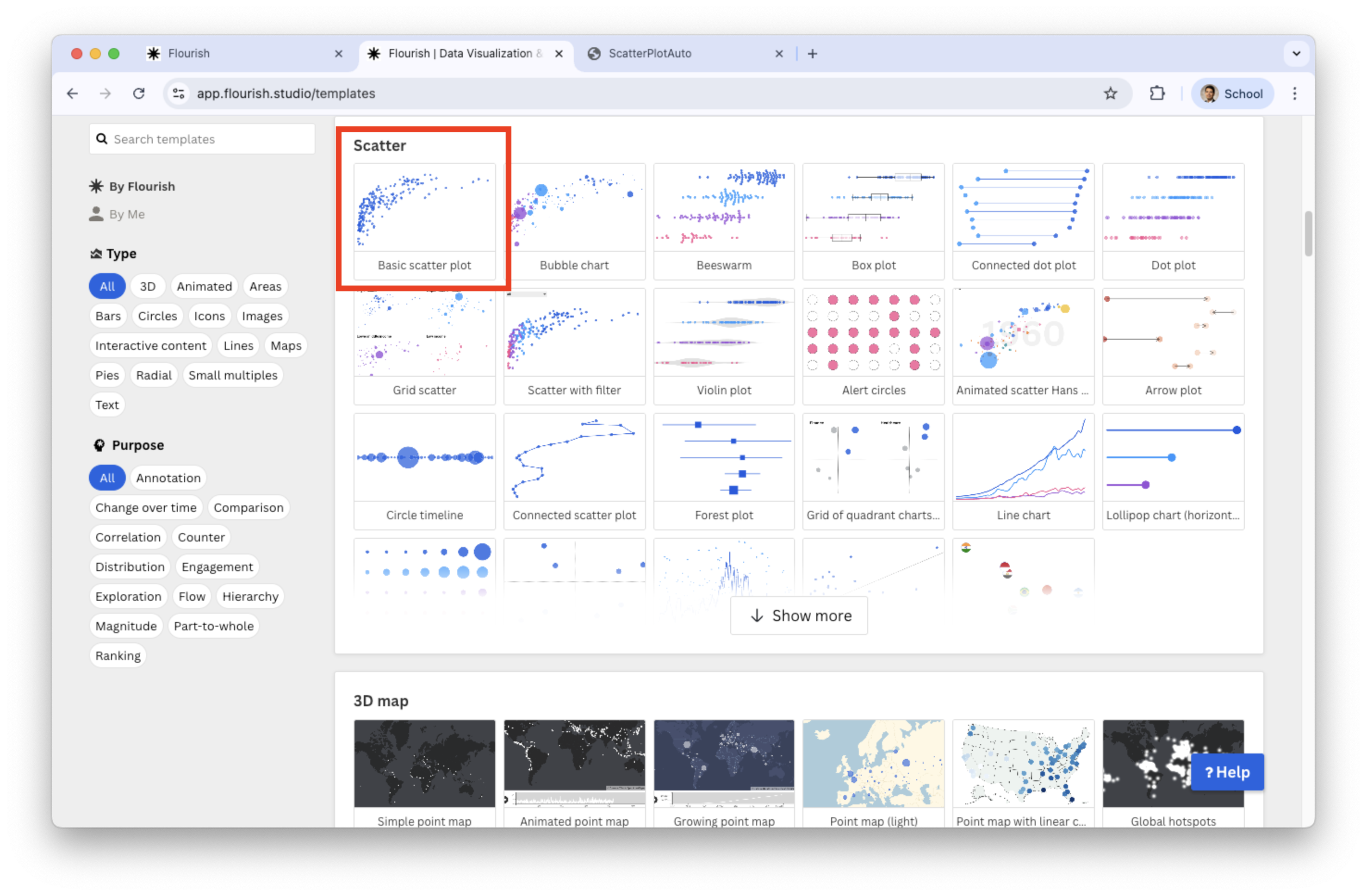
Generate scatter plot in Flourish
Select Scatter in the catalog of visualizations.
![]()
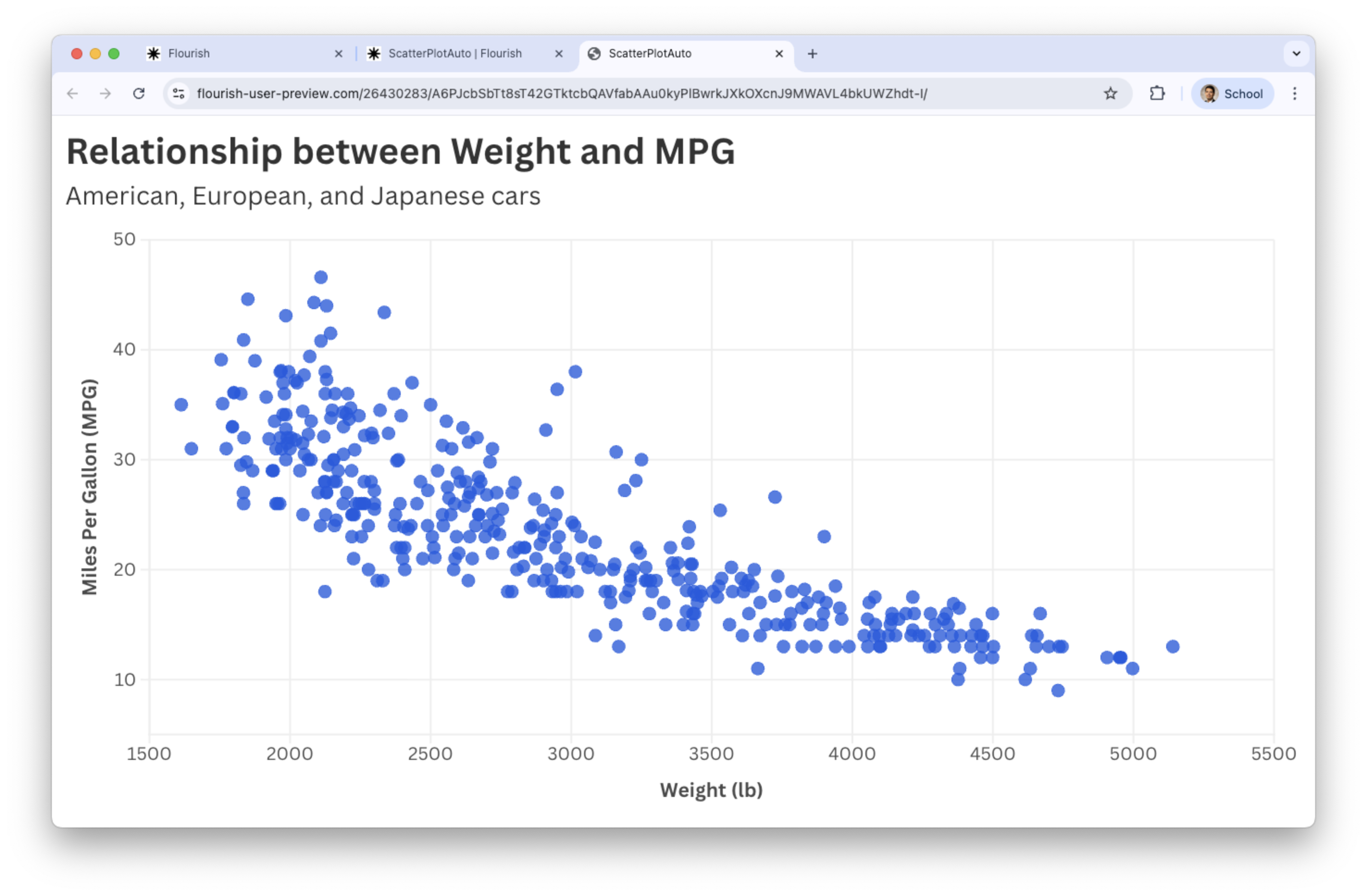
Next, load the “auto_dataset.xlsx” into Flourish. Set the variables under study mpg and weight and assign them to Y values and X values, respectively.
![]()
Go back to the Preview tab and add text to the axes and title.
![]()
Plots for three or four variables
When examining a distribution or relationship, we often want to compare it across data subgroups.
This process of conditioning on additional variables leads to visualizations involving three or more variables.
We now illustrate how to extend the scatter plot to visualize multiple variables.
Add color to the scatter plot
We a categorical variable in the Color section. For example, let’s use origin.
![]()
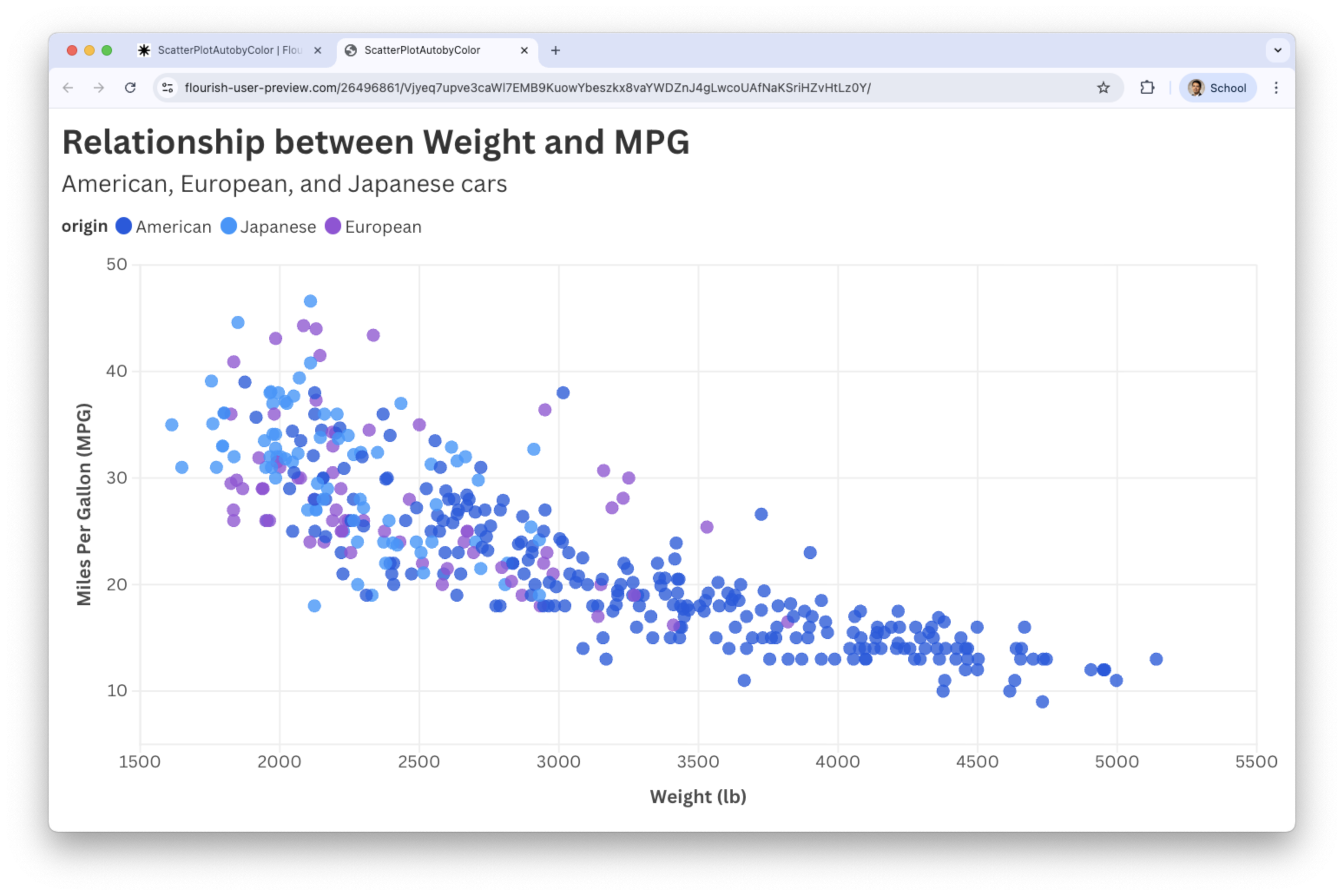
The result
Scatter plots by color work well when the additional variable \(Z\) is categorical with few categories.
![]()
Bubble Plot: Scatter for 4 variables
Add bubbles to the scatter plot
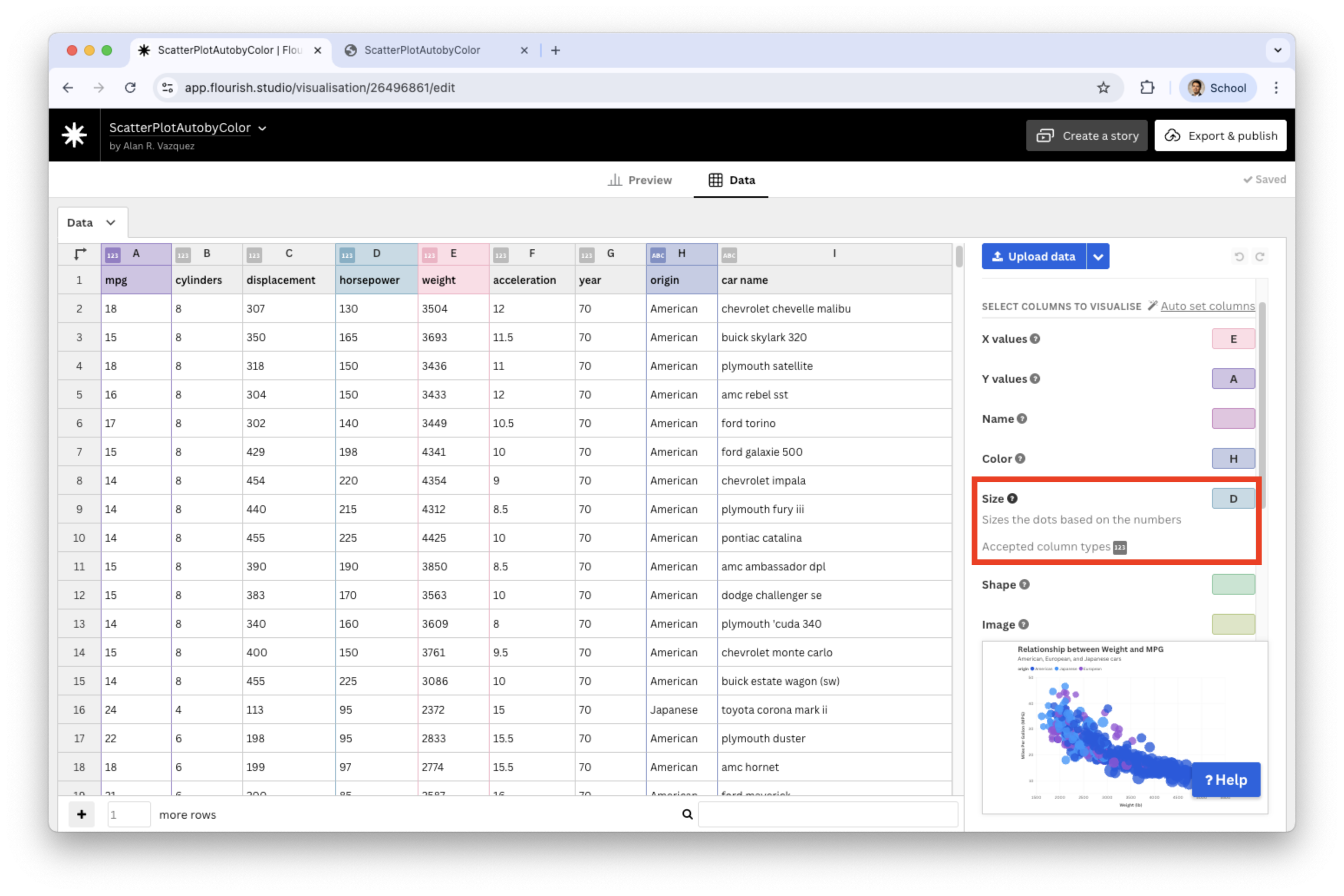
We set a variable in the Size section, say, horsepower.
![]()
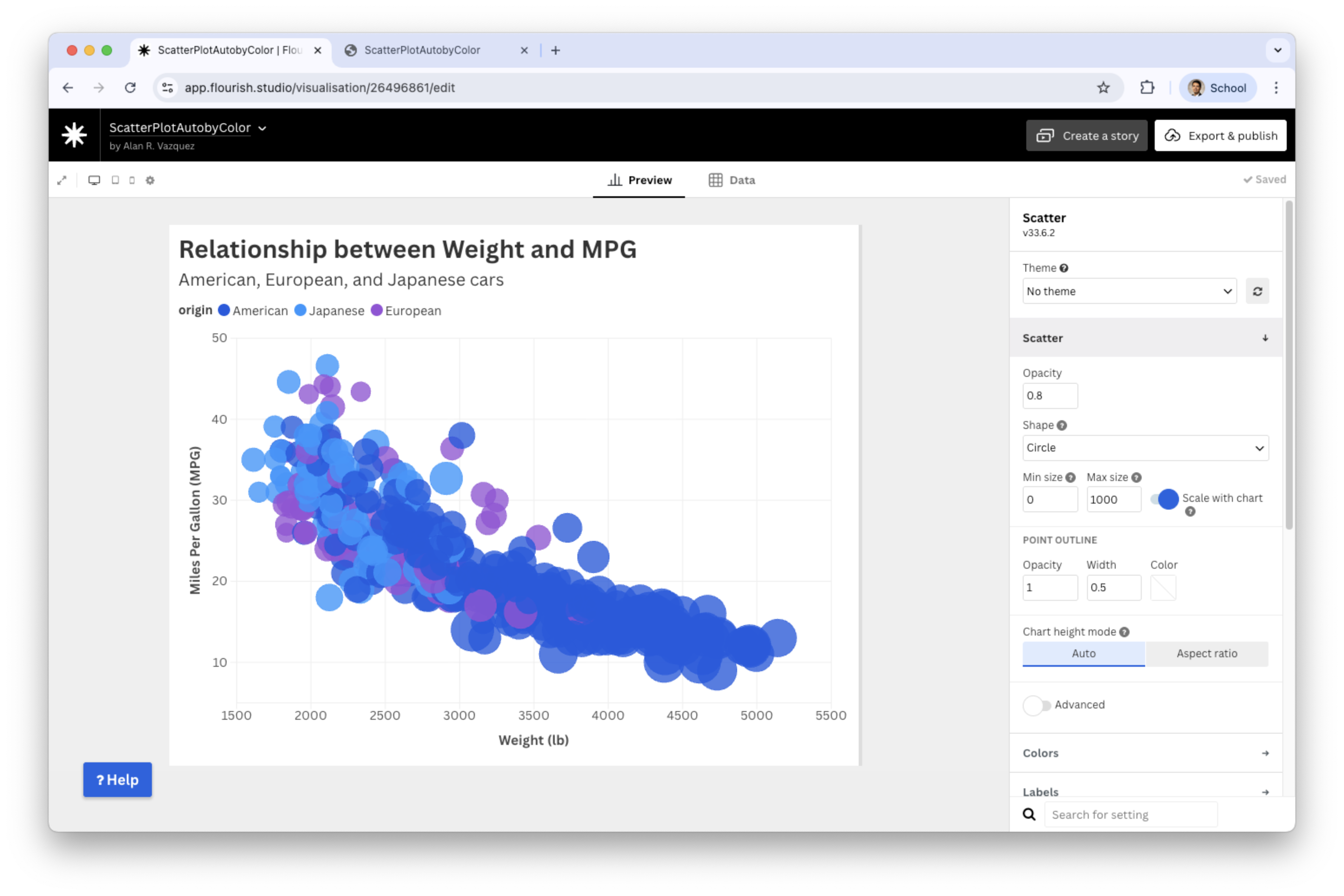
Resulting bubble plot
![]()
Improve the bubble plot
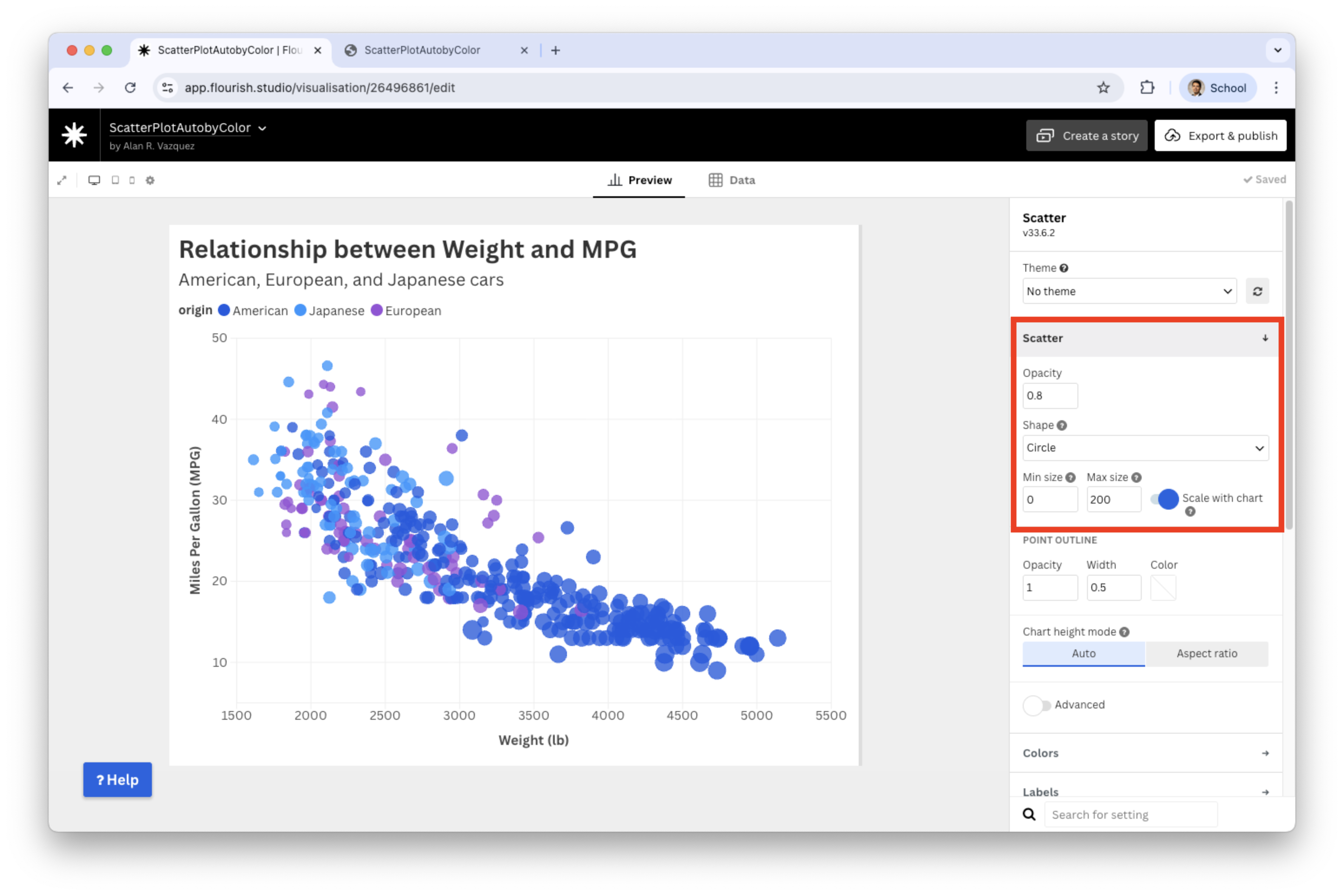
We can enhance the plot by reducing the minimum and maximum sizes for the bubbles. Let’s set the maximum size to 200.
![]()
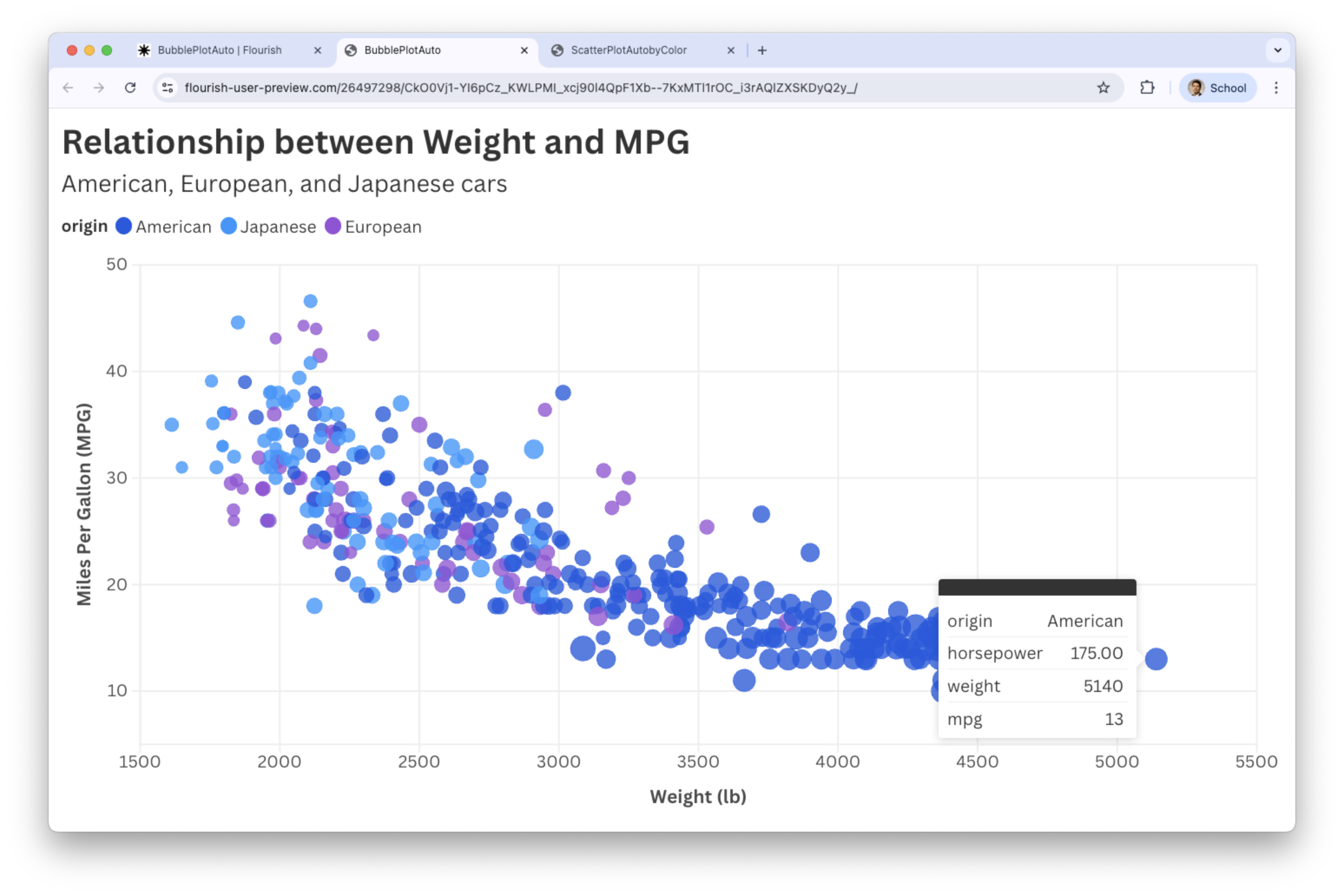
Final bubble plot
![]()
Line plot
A line plot is a visual representation of data where data points are connected by a line. Axes:
- \(X\) (horizontal): Represents time or the independent variable.
- \(Y\) (vertical): Represents the dependent variable.
Each point represents a value at a given moment.
The objective is to explore trends over time or the evolution of a continuous or discrete variable.
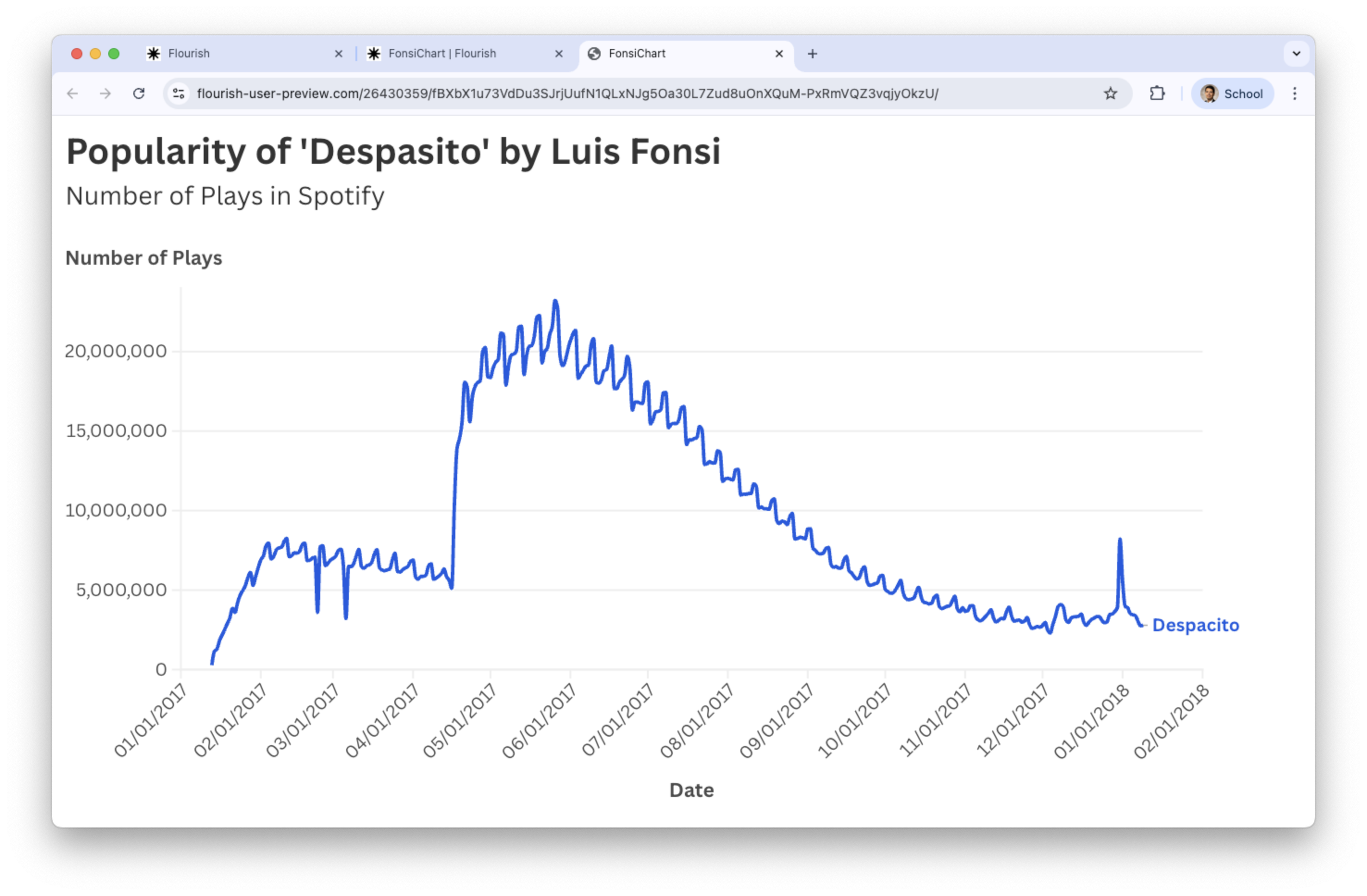
Example 2
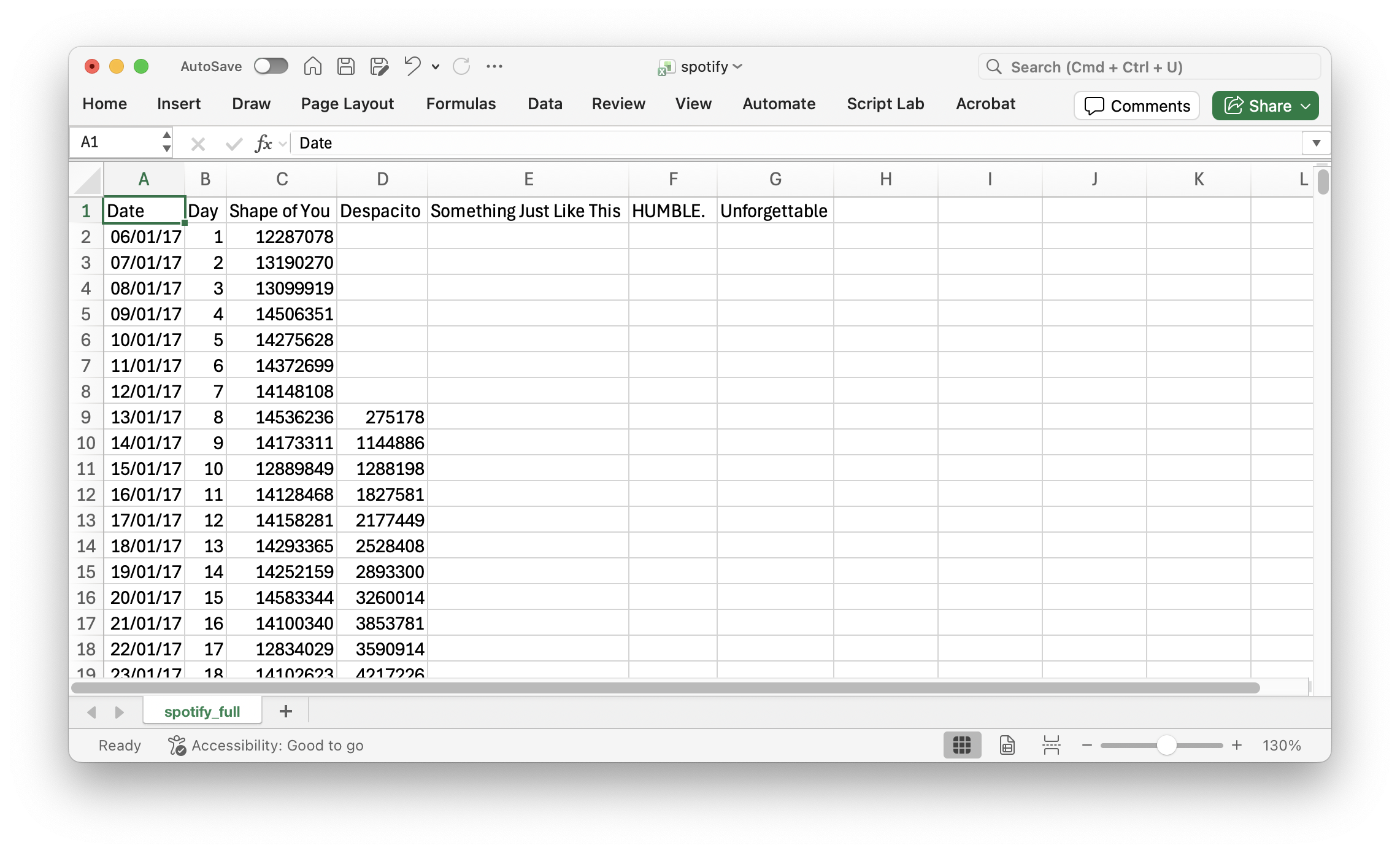
Consider the data in the file “spotify.xlsx”. This dataset contains the global daily streams of the top five most popular songs on the music streaming service Spotify in 2017.
![]()
Generate a line plot in Flourish
Select Line chart in the catalog of visualizations.
![]()
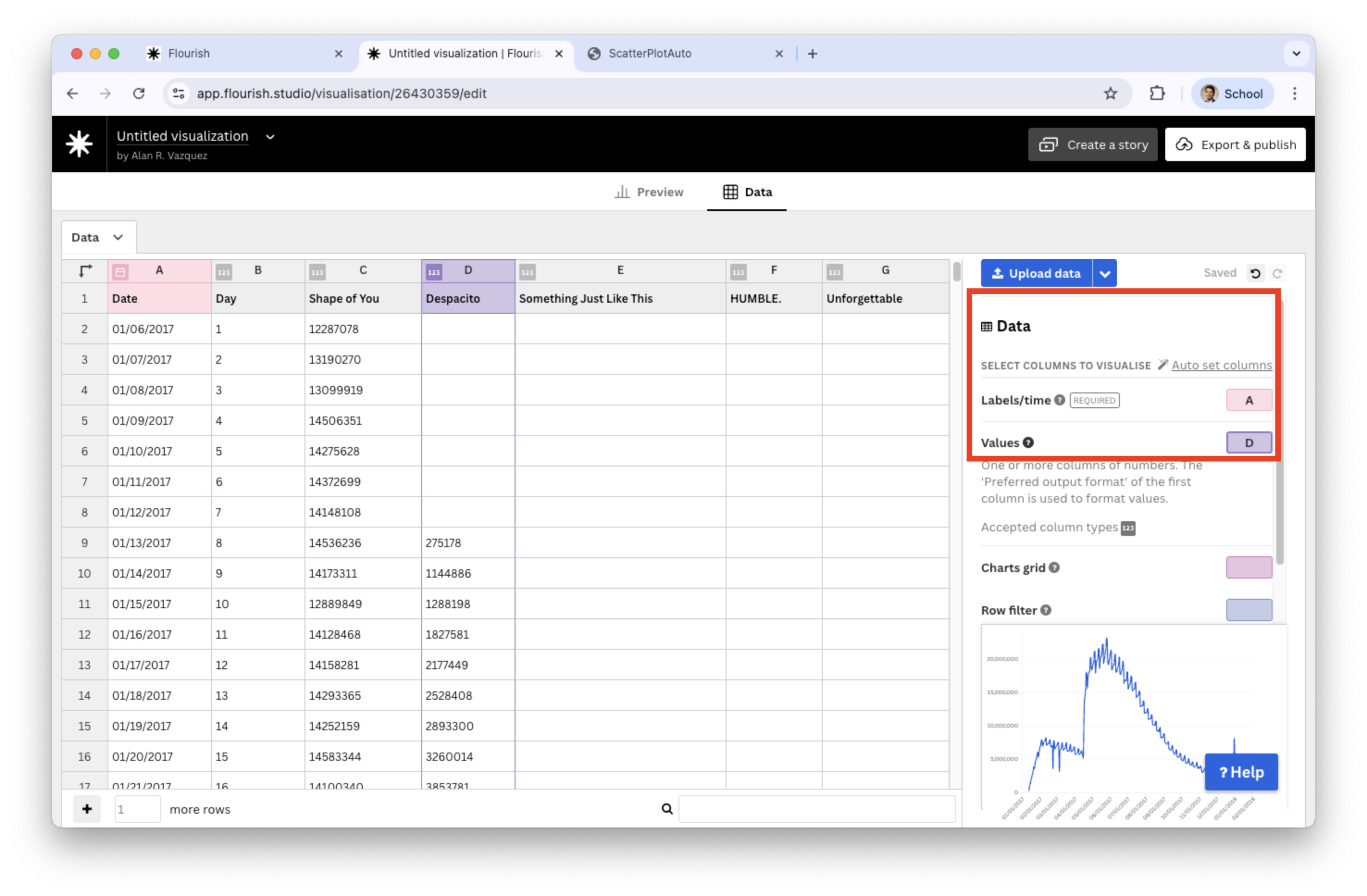
Next, load the “auto_dataset.xlsx” into Flourish. Set the variables under study Date and Despacito and assign them to Labels/time and Values, respectively.
![]()
Go back to the Preview tab and add text to the axes and title.
![]()
Multiple line charts
We can visualize multiple variables simultaneously using a line plot. For example, we can show the evolution of play counts for the 5 songs in the file “spotify.xlsx” over time.
To this end, simply go back to the Data tab and set a range of variables in Values.
![]()
Plots for Categorical Variables
Plotting the average by groups
We can summarize the values of the numerical variable \(Y\) for each category of a categorical variable \(X\) using the mean or average.
For example, let’s plot the average miles per gallon of cars produced in America, Europe, and Japan.
A common visualization for plotting a numerical and a discrete variable when there is only one value per category is the bar plot.
The bar plot encodes quantitative data across different categories.
Generate bar plot in Flourish
Select Bar chart in the catalog of visualizations.
![]()
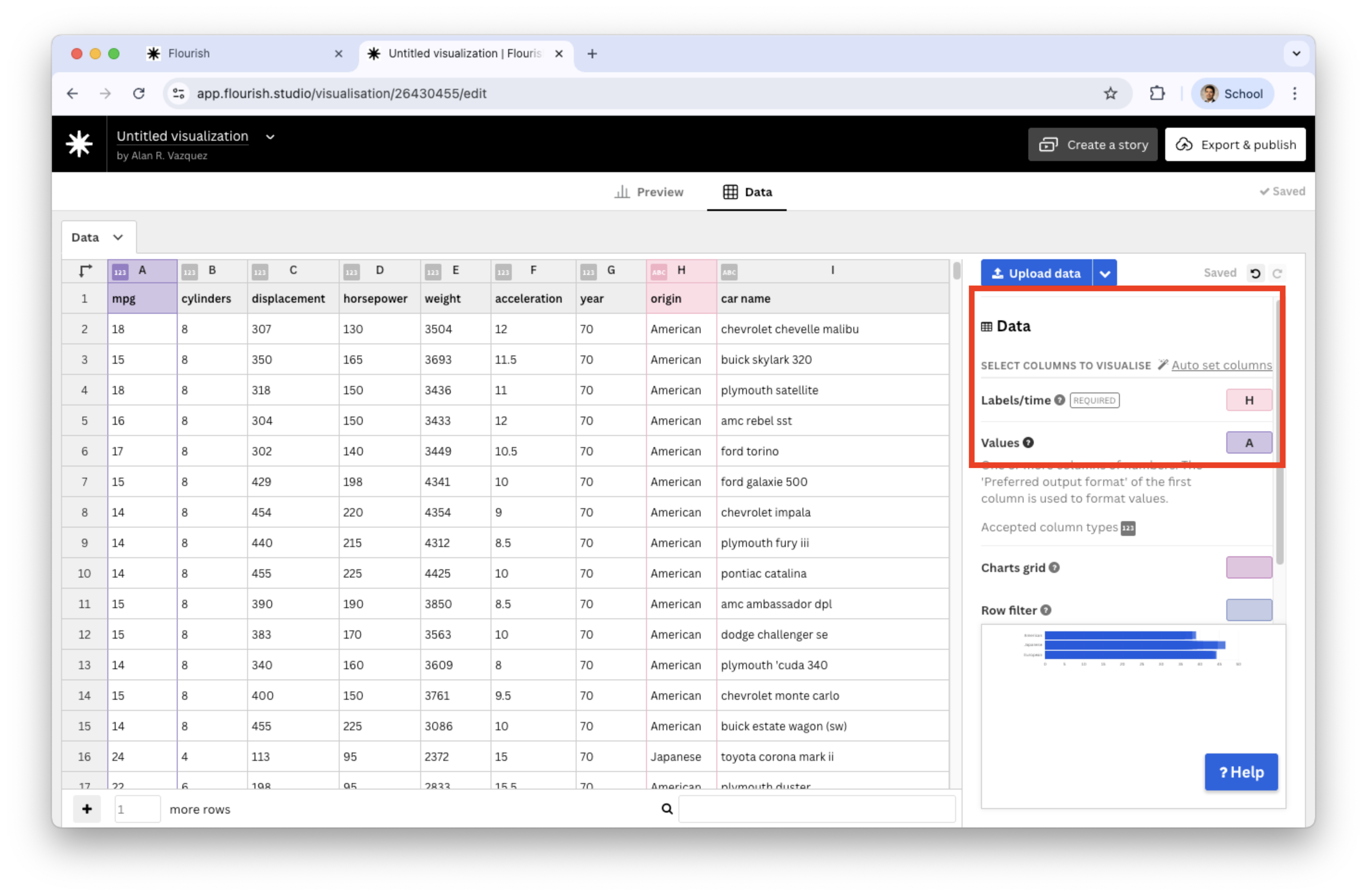
Load the “auto_dataset.xlsx” into Flourish. Set the variables under study origin and mpg and assign them to Labels/time and Values, respectively.
![]()
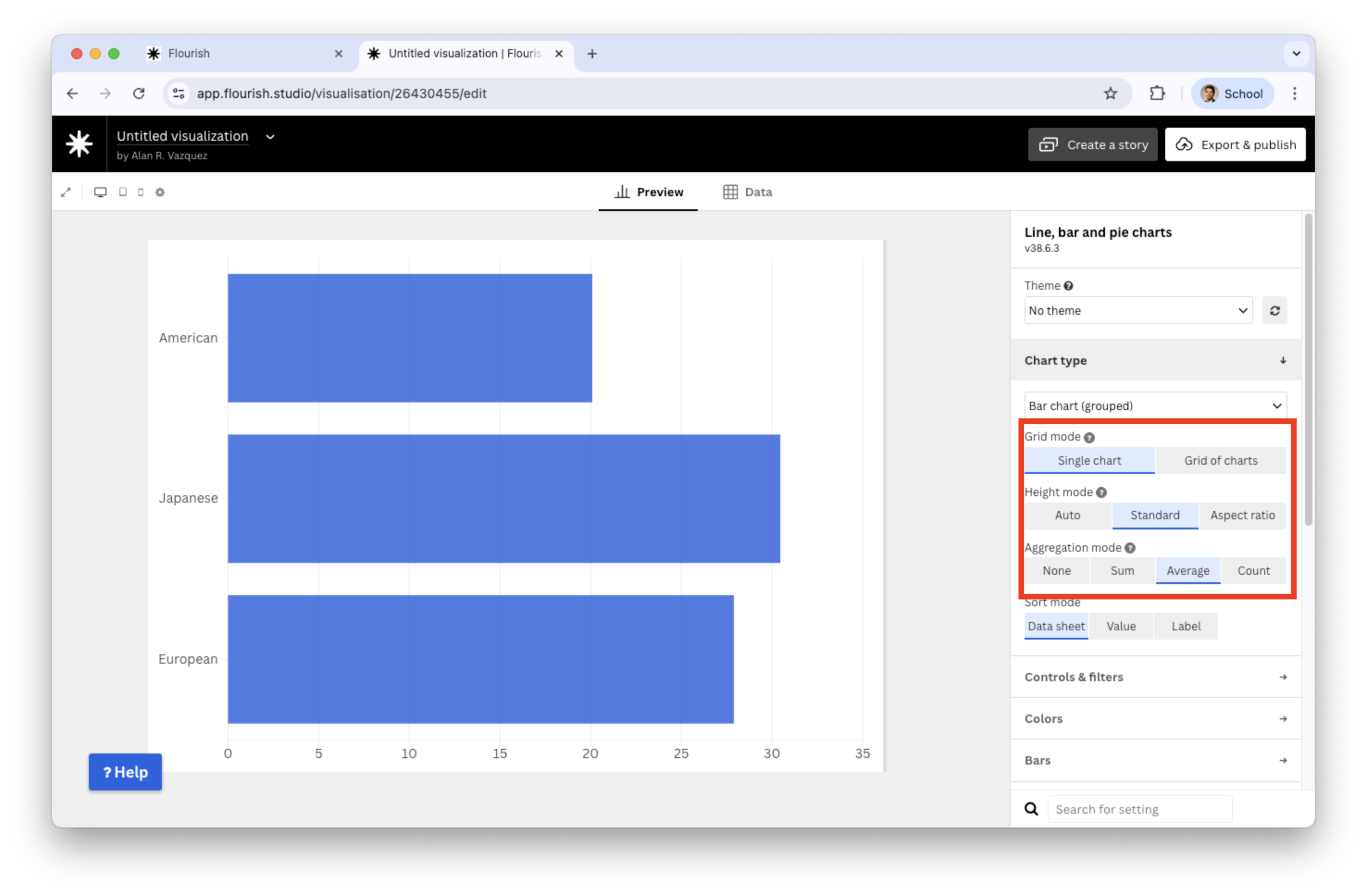
Go to the Preview tab and set Average in Aggregation mode.
![]()
Two Categorical Variables
With two categorical variables, we compare the distribution of one variable across subgroups defined by the other variable.
In fact, we keep one variable constant and plot the distribution of the other.
To do this, there are old and new plots:
- Hierarchical bar plot
- Tree map plot
- Circle packing plot
Example 3
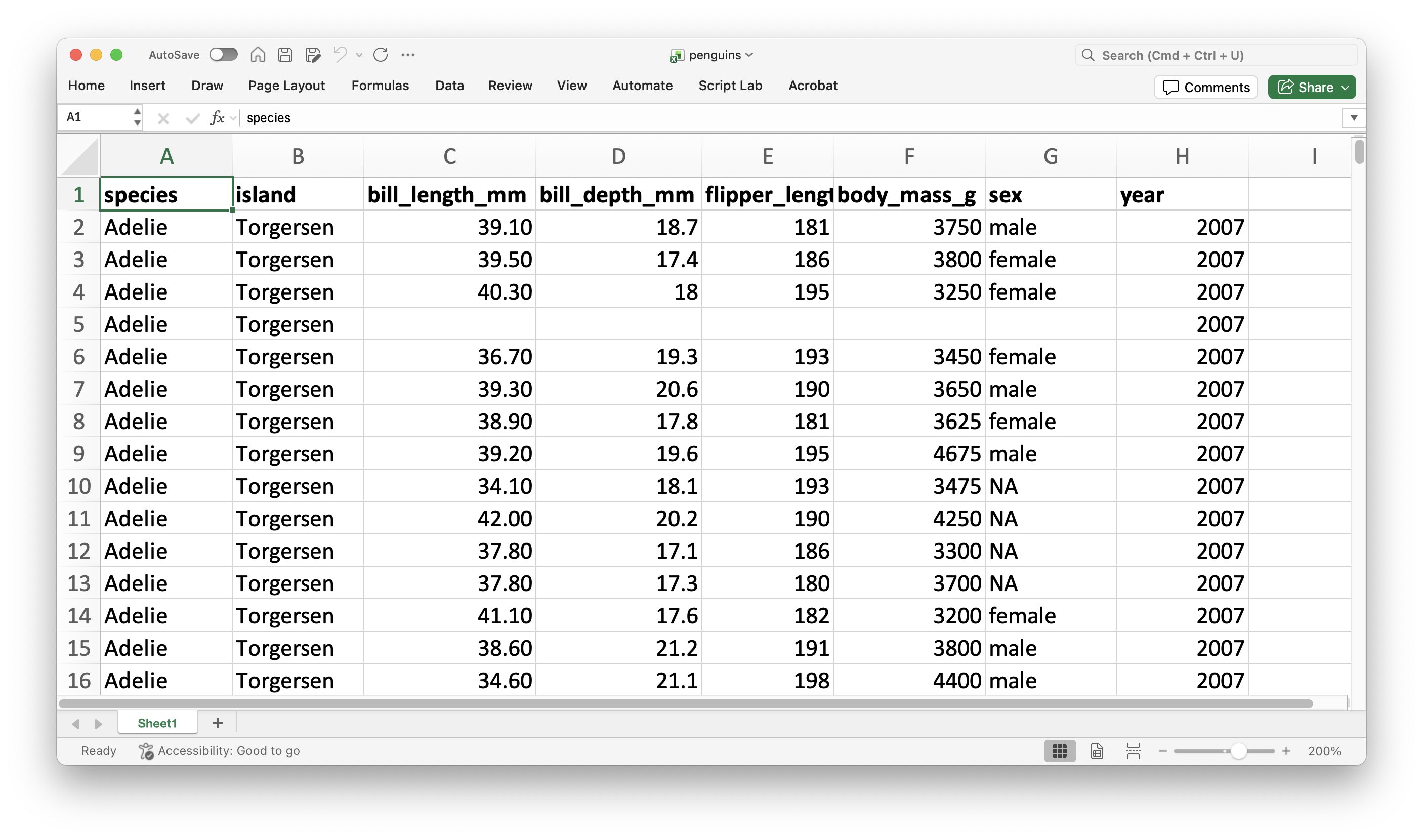
As an example, let’s consider the data in the file “penguins.xlsx” again.
![]()
For instance, let’s study the distribution of penguin species across the three different islands using an stacked bar chart.
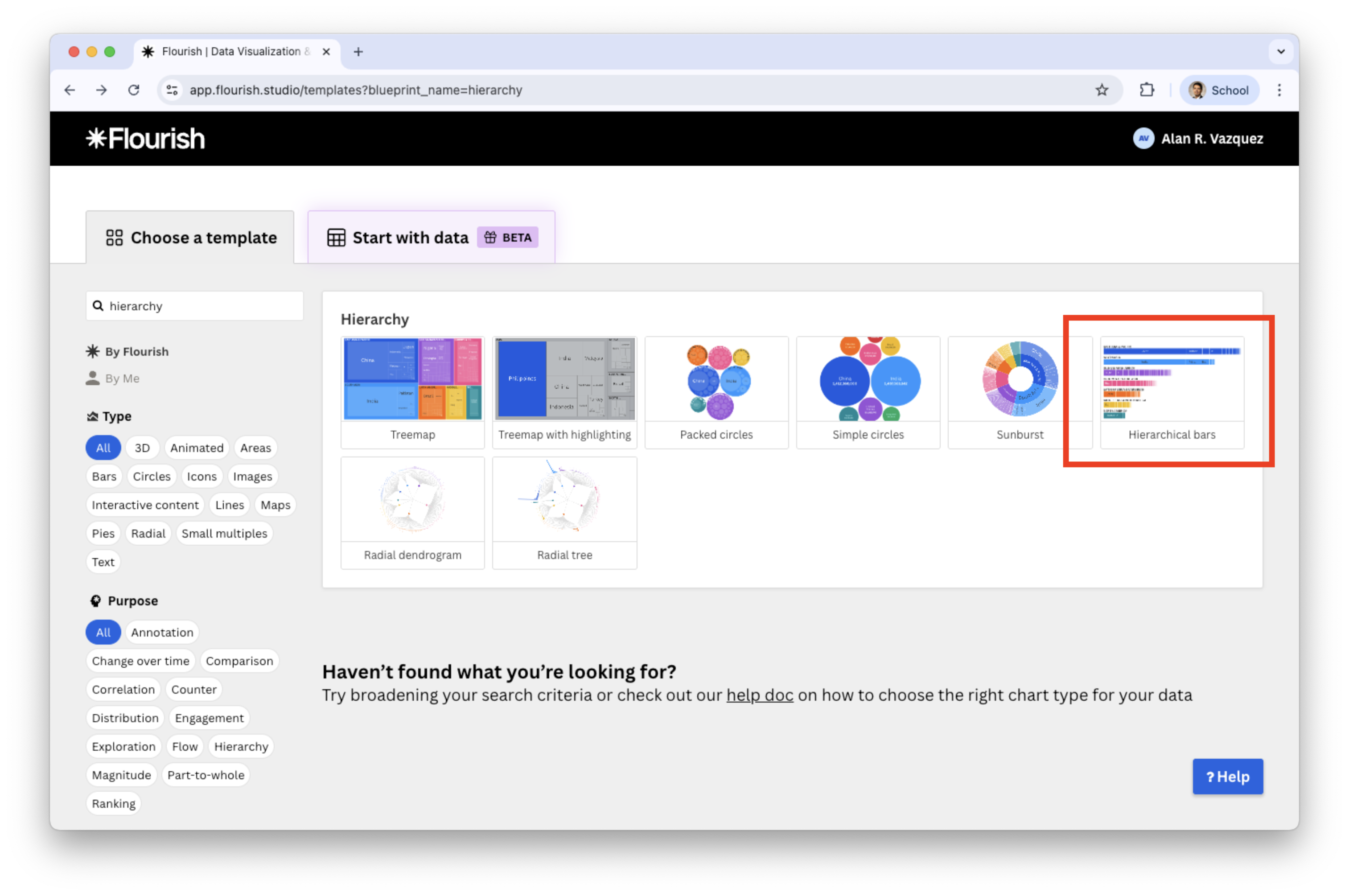
Create a hierarchical plot in Flourish
Search and select the plot in the catalog of visualizations.
![]()
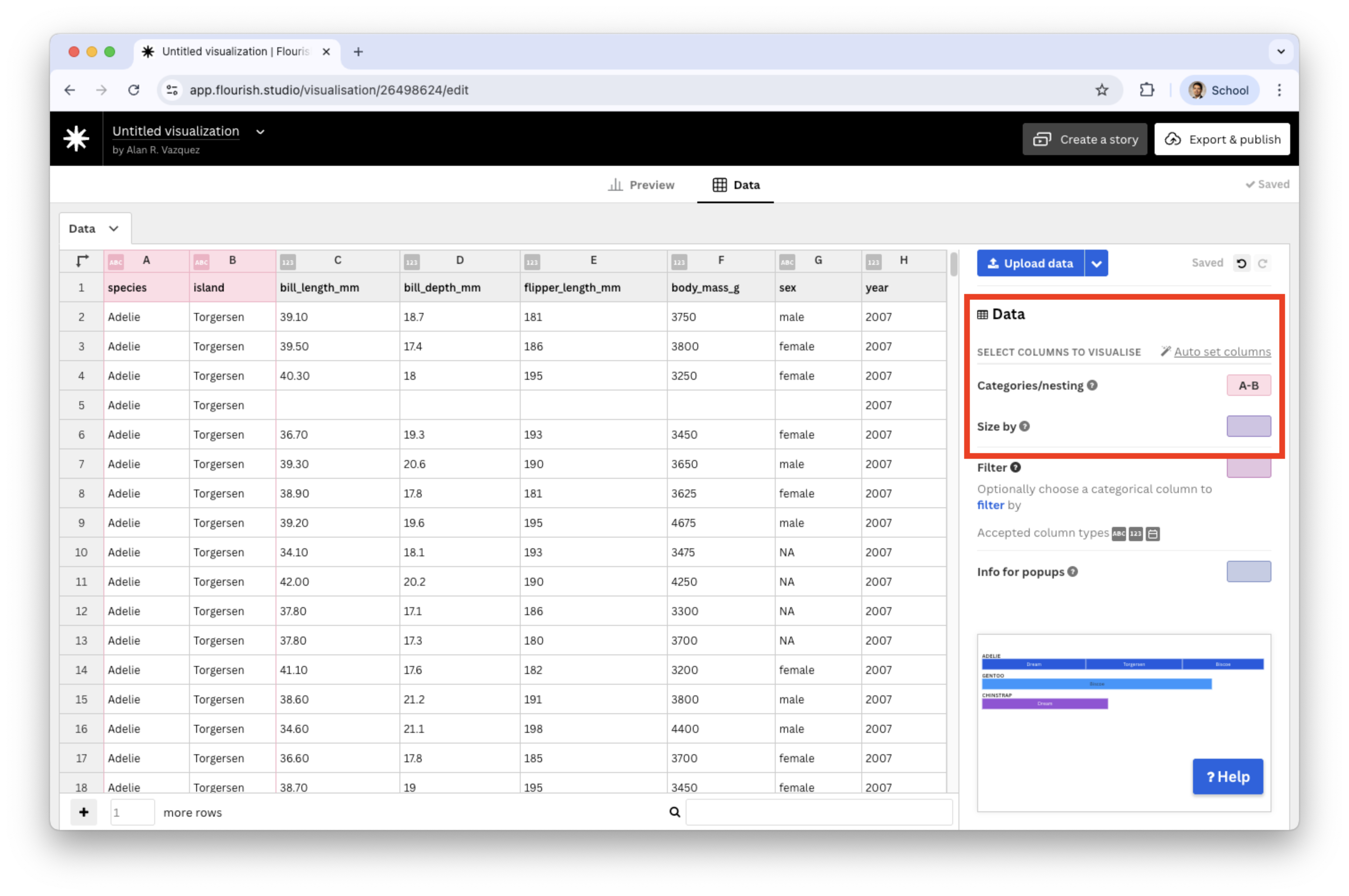
After you load the “penguins.xlsx” data, select two categorical variables in the Categories/nesting section.
![]()
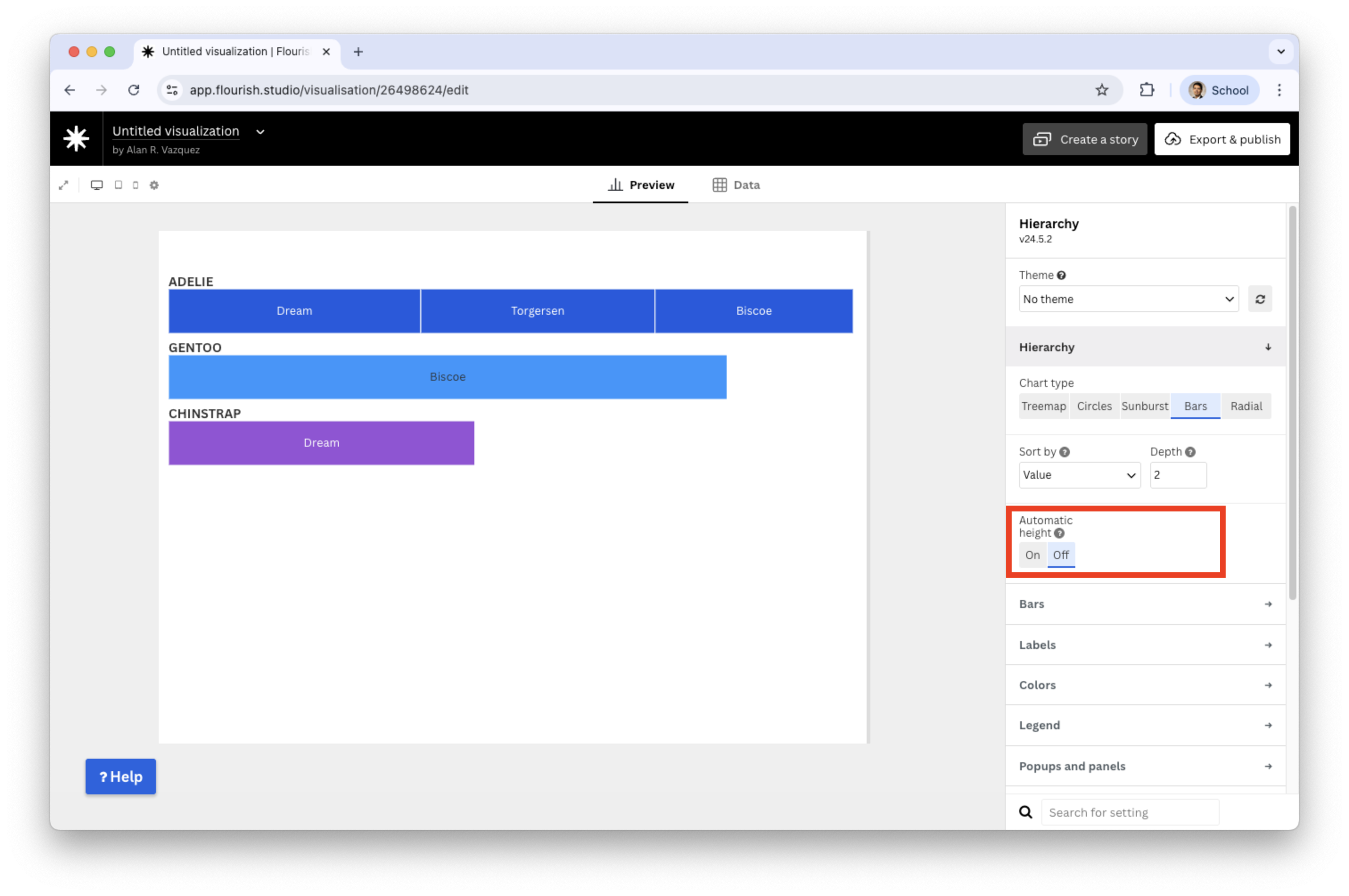
To enhance the plot, switch off the automatic height
![]()
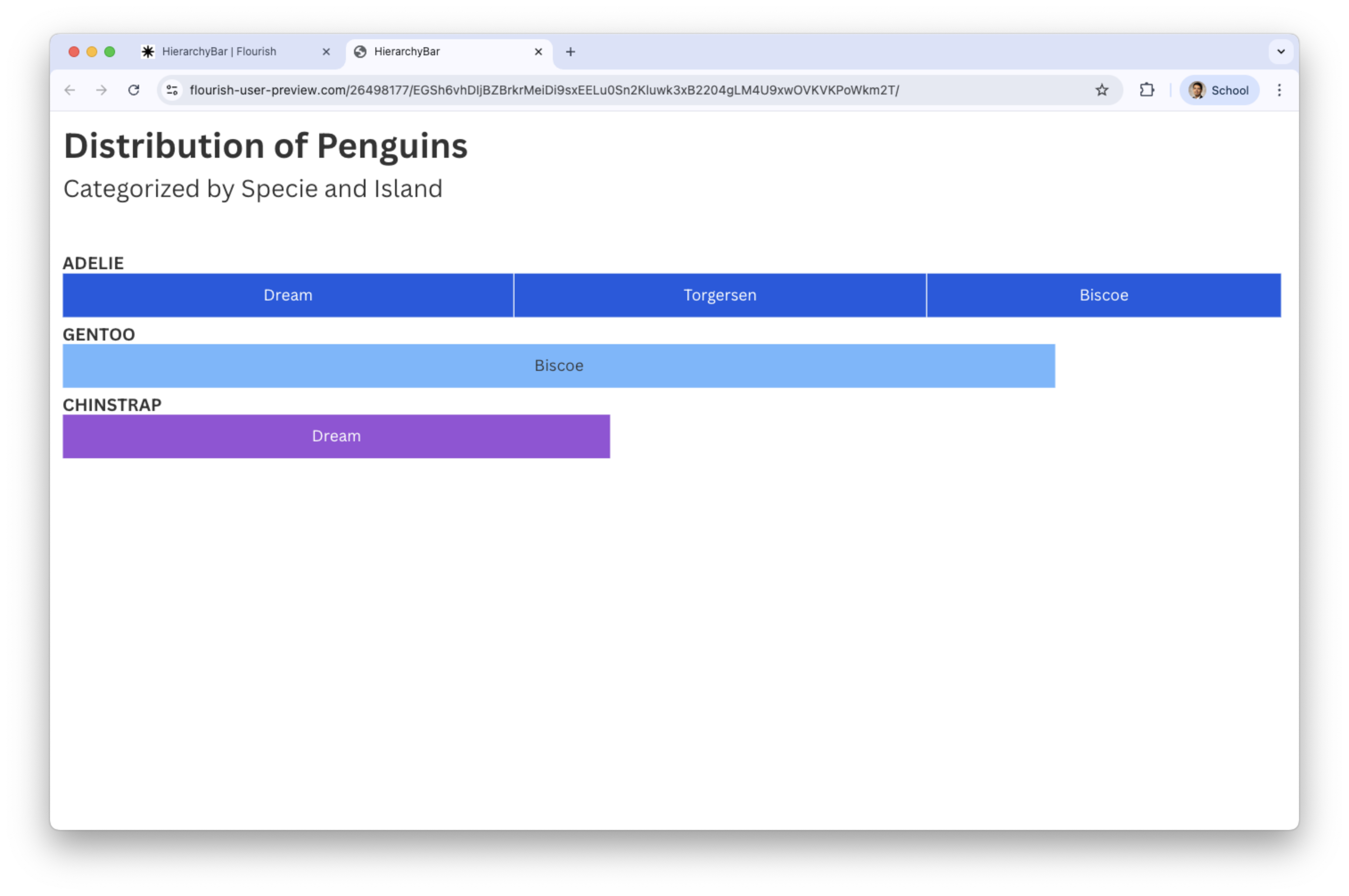
Final hierarchical bar plot with titles
The chart shows the frequency of species and island name.
![]()
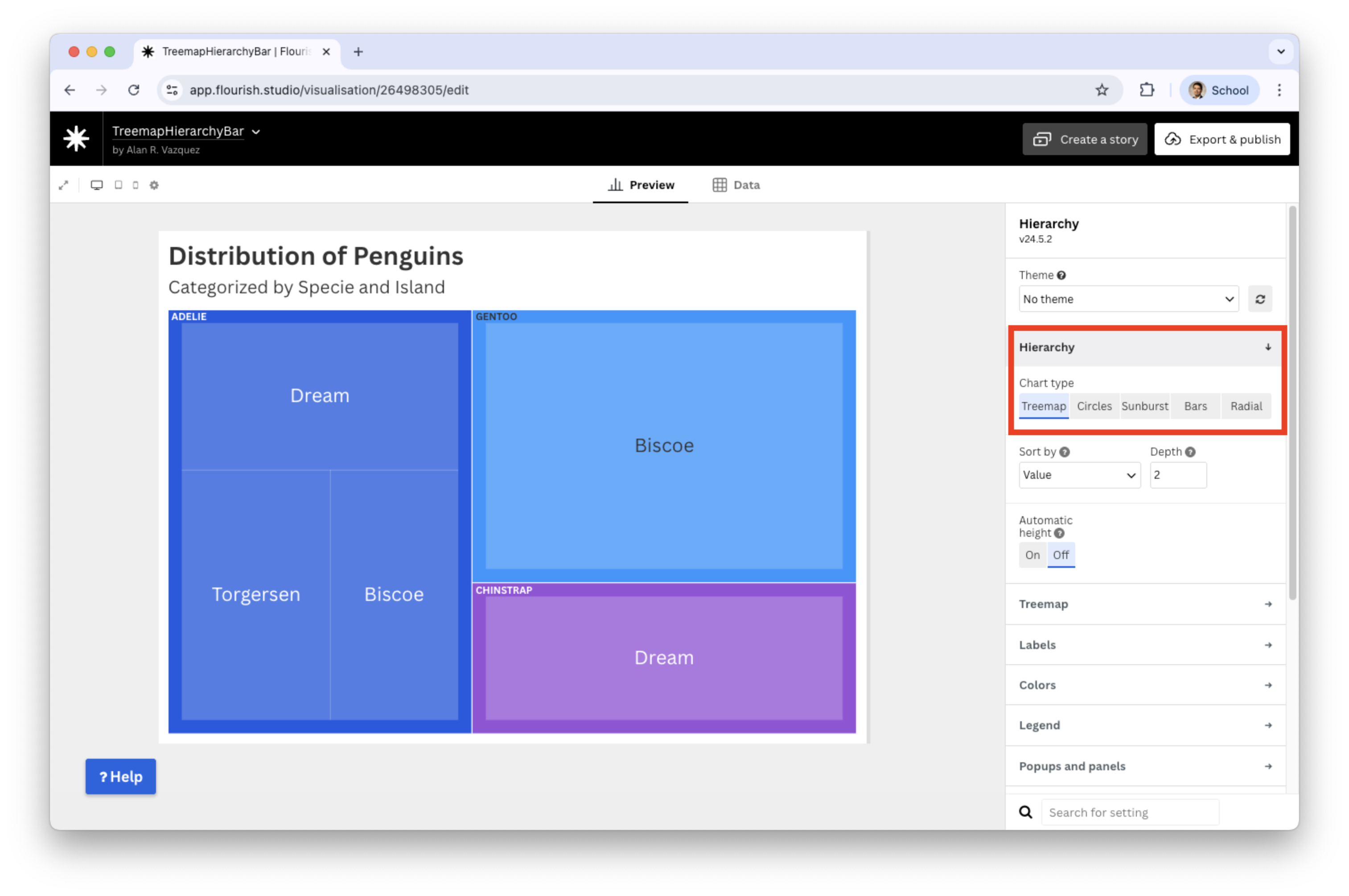
If you change hierarchy to tree
![]()
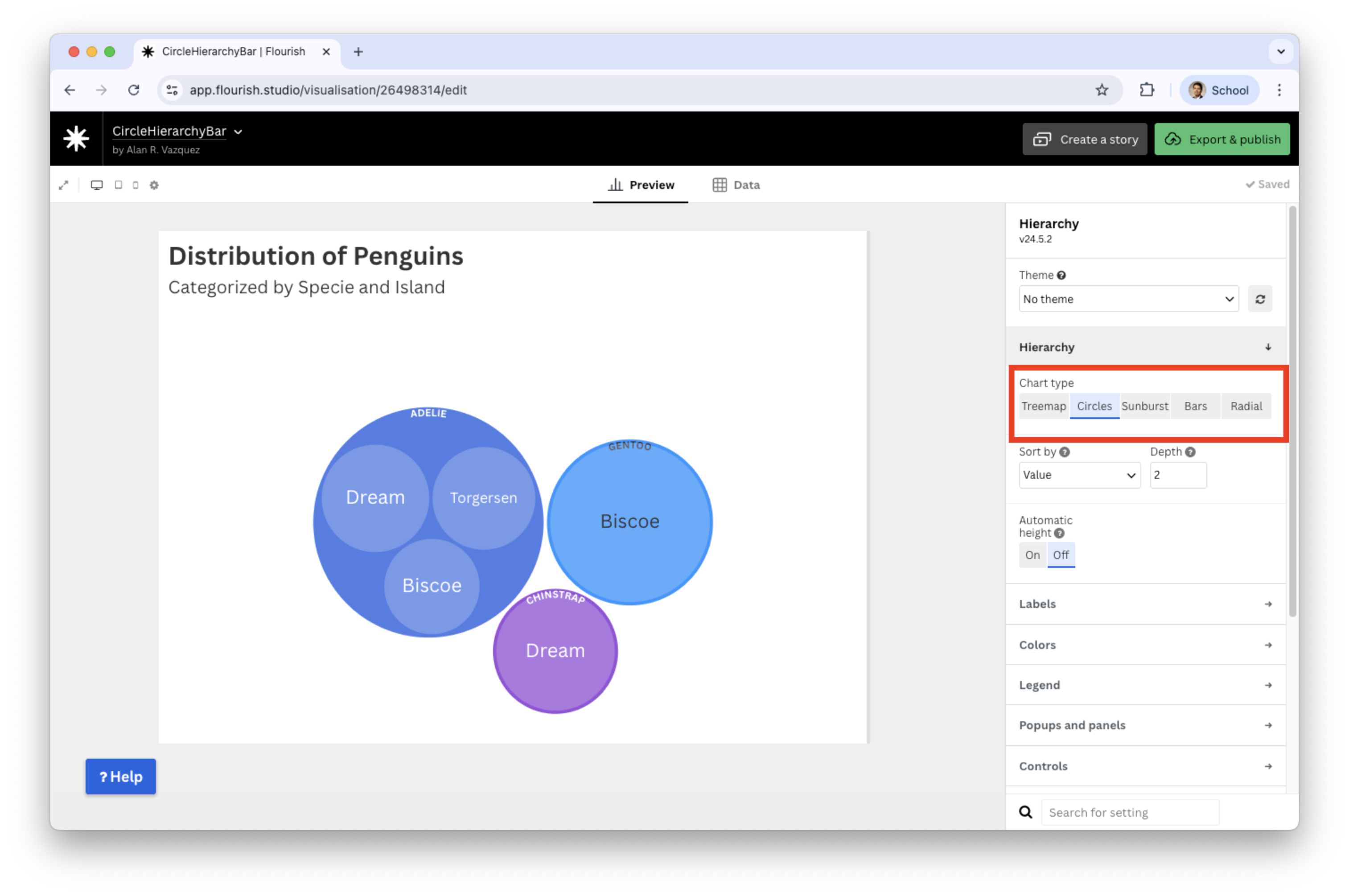
If you change hierarchy to circles
![]()
Discussion
Visualizations such as hierarchy bars, tree maps, and circle packing plots help us explore how two categorical variables relate through nested structure.
Hierarchy bar charts are easy to read when one category has only a few levels. The show a clear sense of order from parent → child categories.
Tree maps are excellent use of space when there are many subcategories. The area encodes quantity, helping highlight dominant groups.
- Circle packing plots are more visually appealing and intuitive for showing nested groups. They are helpful when emphasizing clusters rather than exact magnitudes.