Te permite crear gráficos y hacer computación estadística.
Se puede extender con paquetes (librerías) desarrolladas por otros usuarios.
R Studio
R Studio es una interfaz conveniente para R llamada IDE (integrated development environment). Comúnmente, decimos “Escribo código R en RStudio”
R Studio no es un requisito para programar con R, pero los programadores y científicos de datos de R lo utilizan con mucha frecuencia.
Google Colab
Plataforma de colaboración en la nube gratuita de Google para la creación de documentos de Python o R.
Ejecuta R y colabora en notebooks de Jupyter de forma gratuita.
Aprovecha el poder de la GPU de forma gratuita para acelerar tus proyectos de ciencia de datos.
Guarda y carga fácilmente tus notebooks en Google Drive.
Probemos un comando en R
¿Qué crees que suceda si ejecutamos este comando?
print("Hello world!")
Probemos un comando en R
¿Qué crees que suceda si ejecutamos este comando?
print("Hello world!")
[1] "Hello world!"
Probemos otro comando
¿Qué crees que suceda si ejecutamos este comando?
sum(1, 5, 10)
Probemos otro comando
¿Qué crees que suceda si ejecutamos este comando?
sum(1, 5, 10)
[1] 16
También puedes usar R como una calculadora básica.
5+1
[1] 6
10-3
[1] 7
2*4
[1] 8
9/3
[1] 3
Comentarios
A veces escribimos cosas en la ventana de codificación de R que queremos que R ignore. Estos se llaman comentarios y comienzan con #.
R ignorará los comentarios y simplemente ejecutará el código.
# puedes poner lo que sea despues de ## por ejemplo... blah blah blah
Introducción a funciones en R
Una de las mejores cosas de R es que hay muchos comandos integrados que puedes usar. Éstas se llaman funciones.
Las funciones tienen dos partes básicas:
La primera parte es el nombre de la función (por ejemplo, sum).
La segunda parte es la entrada a la función, que va dentro del paréntesis (sum(1, 5, 15)).
R es exigente
R, al igual que todos los lenguajes de programación, es muy exigente. Por ejemplo, si escribes
sum(1, 100)
[1] 101
te dirá la respuesta, 101.
Pero si escribes
Sum(1, 100)
Error in Sum(1, 100): could not find function "Sum"
con la “s” en mayúscula, ¡actuará como si no tuviera idea de lo que estamos hablando!
Guarda tu trabajo en objetos de R
Prácticamente cualquier cosa, incluidos los resultados de cualquier función de R, se puede guardar en un objeto.
Esto se logra mediante el uso de un operador de asignación, que puede ser un símbolo de igual (=) o uno que se parece a una flecha (<-).
Puede inventar cualquier nombre que desees para un objeto R. Sin embargo, hay dos reglas básicas para esto:
Tiene que ser diferente del nombre de una función en R.
Tiene que ser lo más específico posible.
Por ejemplo,
# Este código asignará el numero 18 al objeto llamado mi_numero_favoritomi_numero_favorito =18
Después de ejecutar este código, no sucede nada. Pero si ejecutamos el objeto por si solo, podremos ver lo que hay en el.
mi_numero_favorito =18mi_numero_favorito
[1] 18
También puedes usar print(mi_numero_favorito).
Vectores
Hasta ahora hemos utilizado objetos R para almacenar un solo número. Pero en estadística estamos tratando con variación, que por definición necesita más de un número.
Un objeto R también puede almacenar un conjunto completo de números, llamado vector.
Puedes pensar en un vector como una lista de números (o valores).
La función c() se puede utilizar para combinar una lista de valores individuales en un vector.
Podemos hacer operaciones simples con vectores. Por ejemplo, podemos multiplicar todos los elementos de un vector por 100.
mi_vector =c(1, 2, 3, 4, 5)100*mi_vector
[1] 100 200 300 400 500
A pesar de que multiplicaste el vector por un valor, este no se modifica.
mi_vector
[1] 1 2 3 4 5
Indexación
Podemos indexar una posición en el vector usando corchetes con un número como este: [1].
Entonces, si quisiéramos imprimir el contenido de la primera posición en mi_vector, podríamos escribir
mi_vector[1]
[1] 1
Mini-actividad (solo mode)
Escribe código para dividir el vector mi_vector por 2.
Guarda el resultado en un nuevo vector llamado mi_nuevo_vector.
Prueba el siguiente comando sum(mi_nuevo_vector). ¿Qué obtuviste?
05:00
Un poco más sobre objetos en R
Puedes pensar en los objetos R como depósitos que contienen valores.
Un objeto R puede contener un solo valor o puede contener un grupo de valores (como en el caso de un vector).
Hasta ahora, sólo hemos puesto números en objetos R.
Los objetos R en realidad pueden contener tres tipos de valores: números, caracteres y valores booleanos.
Valores numéricos
Si R sabe que estás usando números, puede hacer muchas cosas con ellos. Hemos visto, por ejemplo, que R puede realizar operaciones aritméticas con números: suma, resta, multiplicación y división.
# Aquí hay dos formas de crear un vector numérico con los # números del 1 al 10.mi_num_1 =c(1,2,3,4,5,6,7,8,9,10)mi_num_2 =1:10
Obtenemos lo mismo.
mi_num_1
[1] 1 2 3 4 5 6 7 8 9 10
mi_num_2
[1] 1 2 3 4 5 6 7 8 9 10
Valores de carácter
Los caracteres se componen de texto, como palabras u oraciones. Un ejemplo de un vector con caracteres como elementos es:
La mejor manera de aprender a programar es probar cosas y ver qué sucede. Escribe un código, ejecútalo y piensa por qué no funcionó.
Hay muchas maneras de cometer pequeños errores en la programación (por ejemplo, escribir una letra mayúscula cuando se necesita una letra minúscula).
A menudo tenemos que encontrar estos errores mediante prueba y error.
Librerías en R
Los paquetes son las unidades fundamentales del código R reproducible. Incluyen funciones R re-utilizables, la documentación que describe cómo usarlas y datos de muestra.
Hasta Septiembre de 2020, había ya más de 16,000 paquetes disponibles en CRAN (la red integral de archivos R)
Trabajaremos mayormente con las librerías readxl, dplyr, ggplot2, y ggformula.
¿Cómo cargar datos en R?
Organización de datos
En estadística, organizamos los datos en filas y columnas.
Las filas son los casos muestreados. En este ejemplo, las filas son amas de llaves de diferentes hoteles. Hay seis filas, por lo que hay seis amas de llaves en este conjunto de datos.
Dependiendo del estudio, las filas podrían ser personas, estados, parejas, ratones, cualquier caso del que tomes una muestra para estudiarlo.
Las columnas representan variables o los atributos de cada caso que se midieron.
En este estudio, se informó o no a las amas de llaves que su trabajo diario de limpieza de habitaciones de hotel equivalía a hacer ejercicio adecuado para una buena salud.
Entonces una de las variables, Condition, indica si fueron informados de este hecho o no.
Existen otras variables como la edad del ama de llaves (Age), el peso antes de iniciar el estudio (Wt), y su peso al final del estudio (Wt2), medido cuatro semanas después.
Por lo tanto, los valores en cada fila representan los valores de ese caso particular en cada una de las variables medidas.
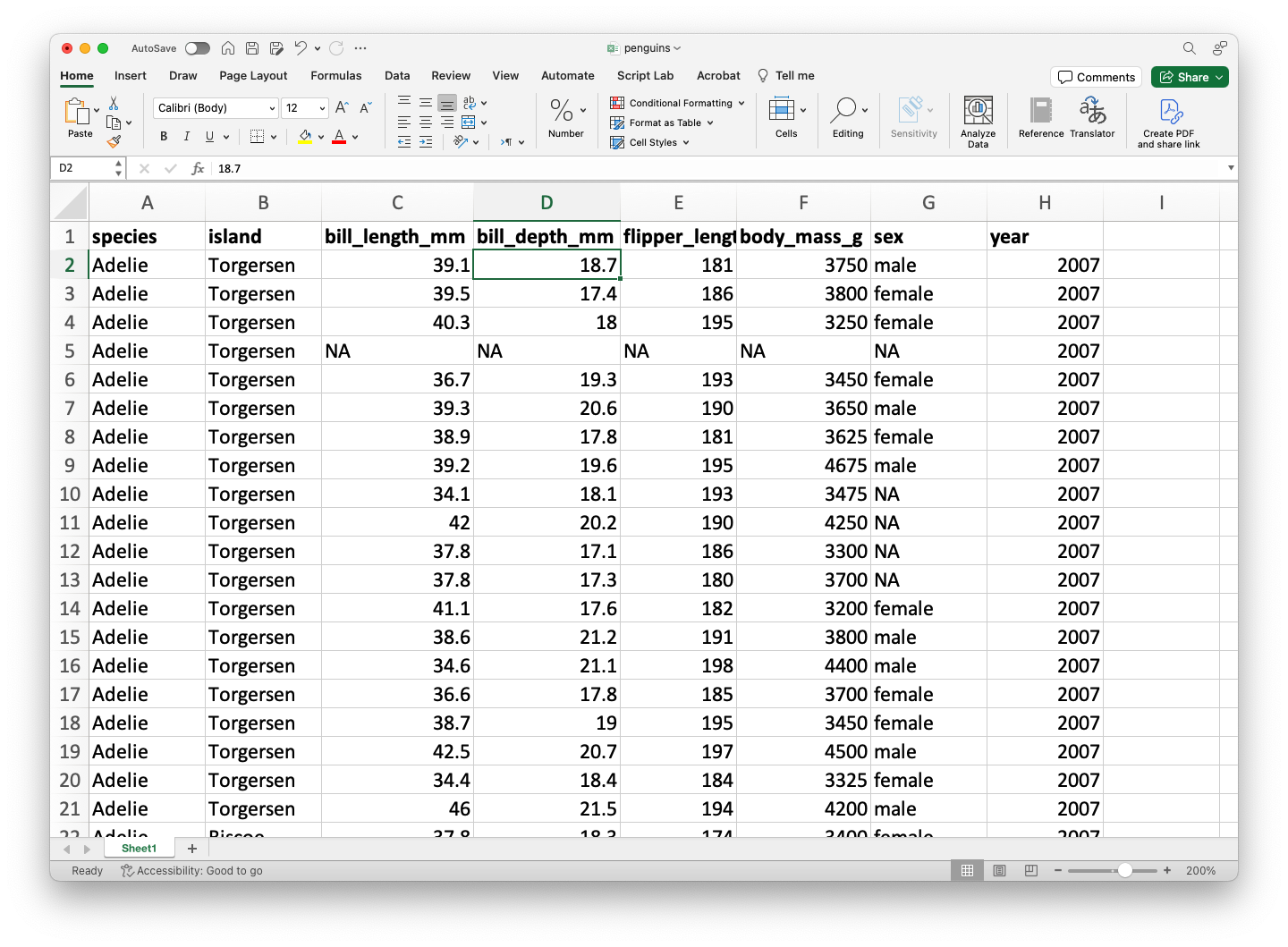
En este curso, asumiremos que los datos están almacenados en un archivo Excel con la organización anterior. Como ejemplo, usemos el archivo penguins.xlsx.
El archivo debe de ser previamente cargado en Google Colab.
Librería readxl
Para cargar datos en R, usaremos la librería llamada readxl. Por fortuna, la librería ya viene pre-instalada en Google Colab.
Sin embargo, debemos informar a Google Colab que queremos usar readxl y sus funciones. Cargarmos la librería en R usando el siguiente comando.
library(readxl)
El siguiente código muestra como leer los datos en el archivo penguins.xlsx en R.
penguins_data =read_excel("penguins.xlsx")# Imprime las primeras 6 filas de los datos.head(penguins_data)
# A tibble: 6 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
# ℹ 2 more variables: sex <chr>, year <dbl>
ggplot2
ggplot2
ggplot2 es uno de los mejores paquetes gratuitos para construir gráficas.
Es parte de una colección de paquetes de ciencia de datos llamado tidyverse.
Simplemente, la cargamos con el siguiente comando.
library(ggplot2)
Una librería auxiliar
Para hacer más simple nuestra interacción con ggplot2, usaremos una librería llamada ggformula.
Sin embargo, ggformula no está pre-instalada en Google Colab. Para instalar una librería en R, usamos el comando: install.packages("ggformula")
Una vez, hecho esto, procedemos a cargar la librería en R
library(ggformula)
La estructura de ggformula
ggformula tiene una estructura para crear gráficas por pasos.
gf_PLOTTYPE(Variable2 ~ Variable1, data = my_data, color = ~Variable3, shape = ~Variable4)
+ labs(title, subtitle, caption, x, y, color, shape)
+ more_options()
Ejemplo
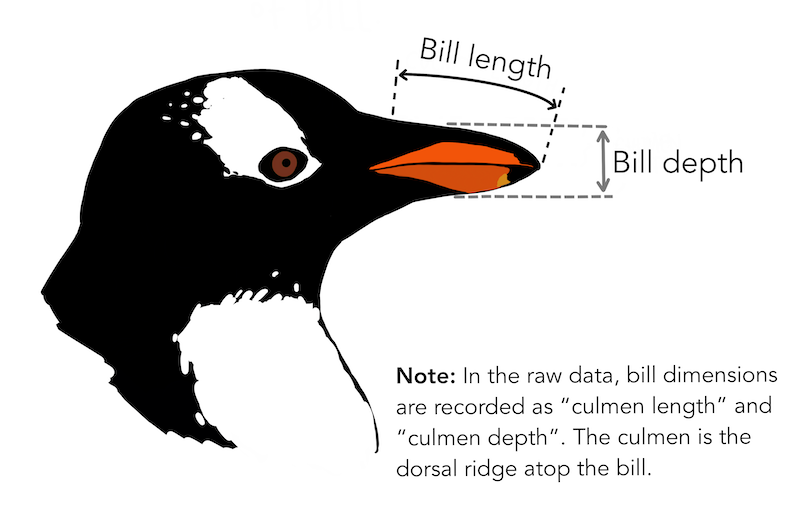
¿Existe alguna diferencia entre la longitud y profundidad del pico de las diferentes especies de pingüinos?
Ejemplo
¿Existe alguna diferencia entre la longitud y profundidad del pico de las diferentes especies de pingüinos?
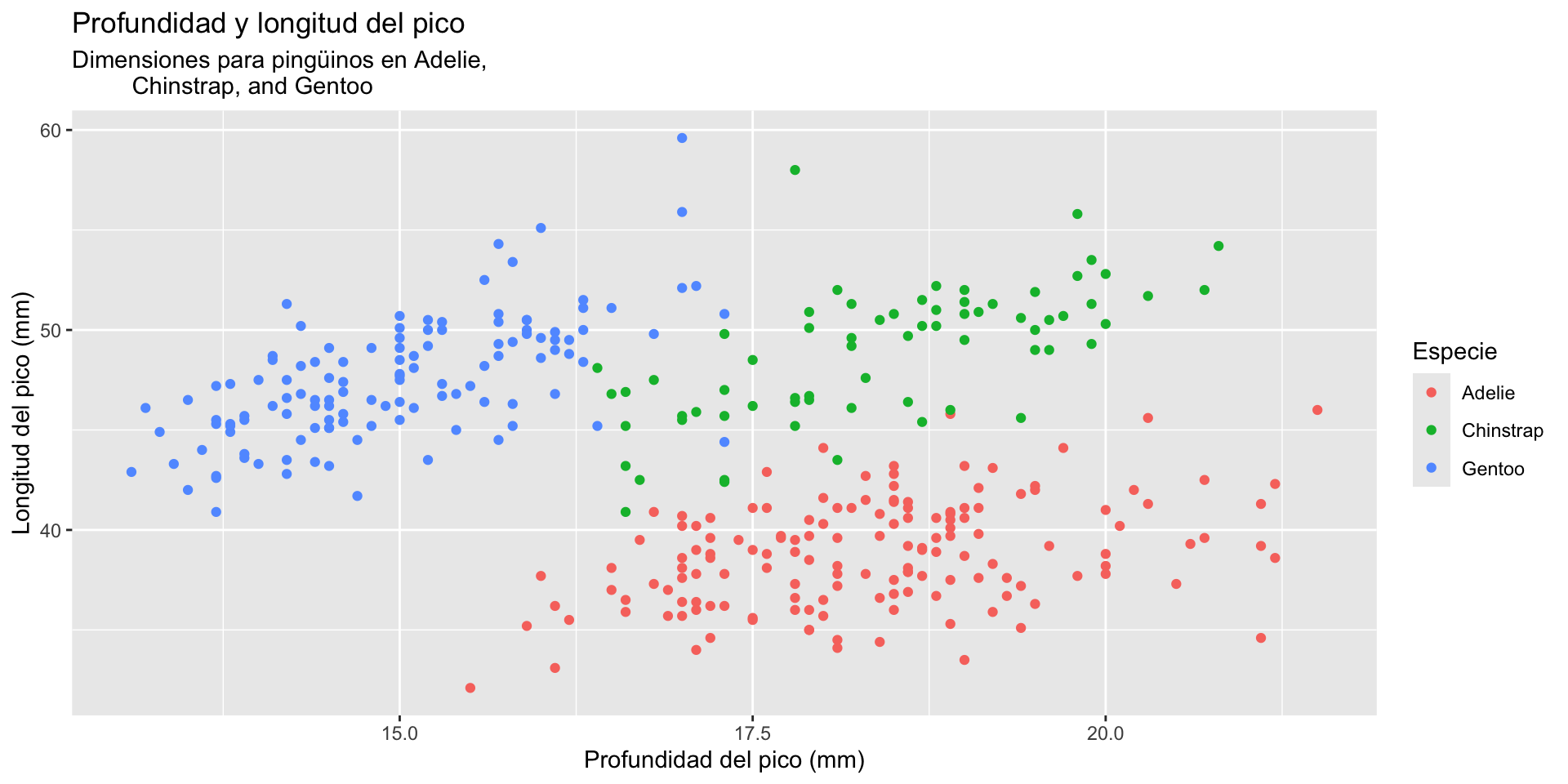
gf_point(bill_length_mm ~ bill_depth_mm, data = penguins_data,color =~species)
Ejemplo
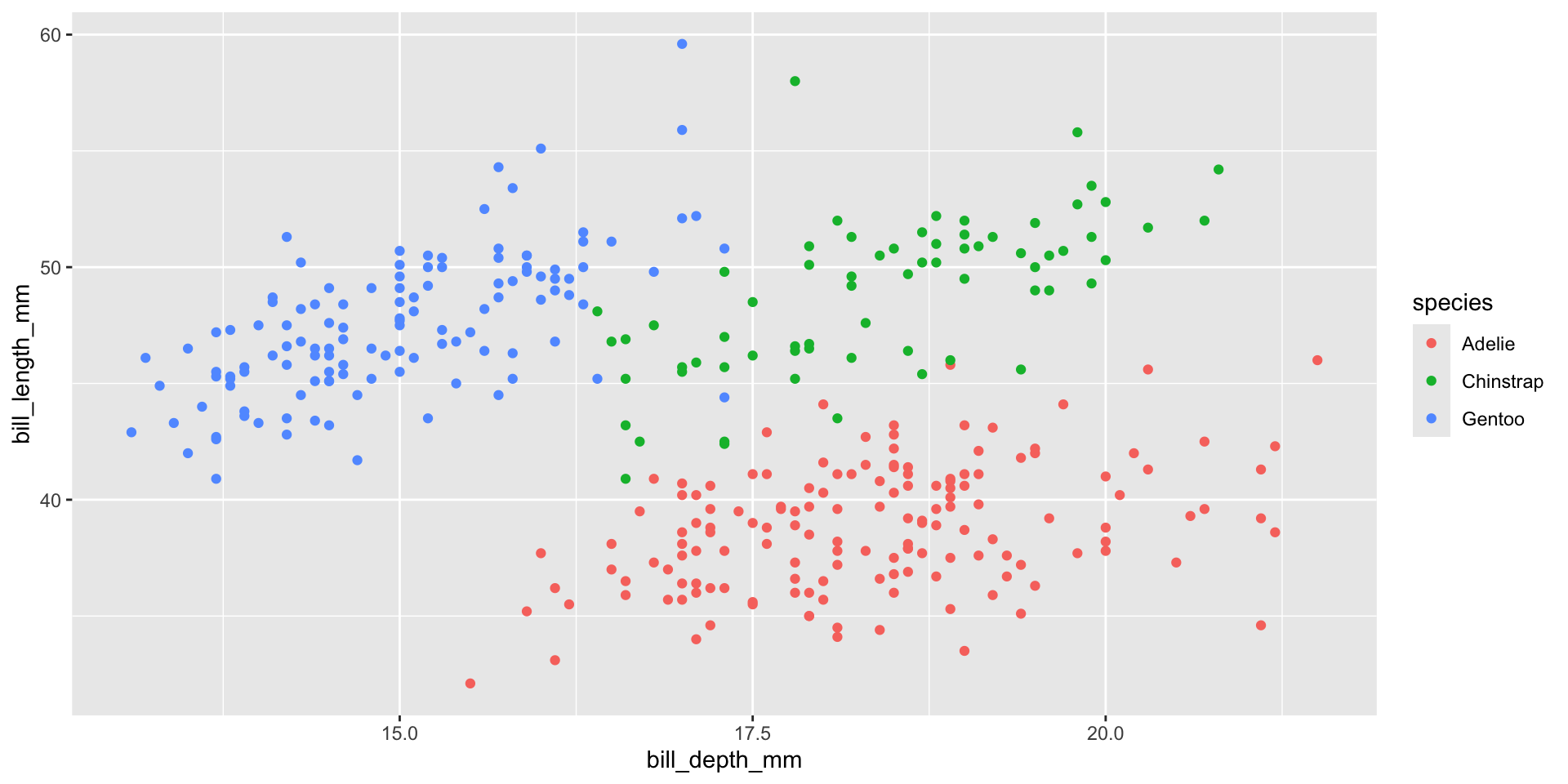
gf_point(bill_length_mm ~ bill_depth_mm, data = penguins_data, color =~species) +labs(title ="Profundidad y longitud del pico", subtitle ="Dimensiones para pingüinos en Adelie, Chinstrap, and Gentoo", x ="Profundidad del pico (mm)", y ="Longitud del pico (mm)",color ="Especie")
Ejemplo
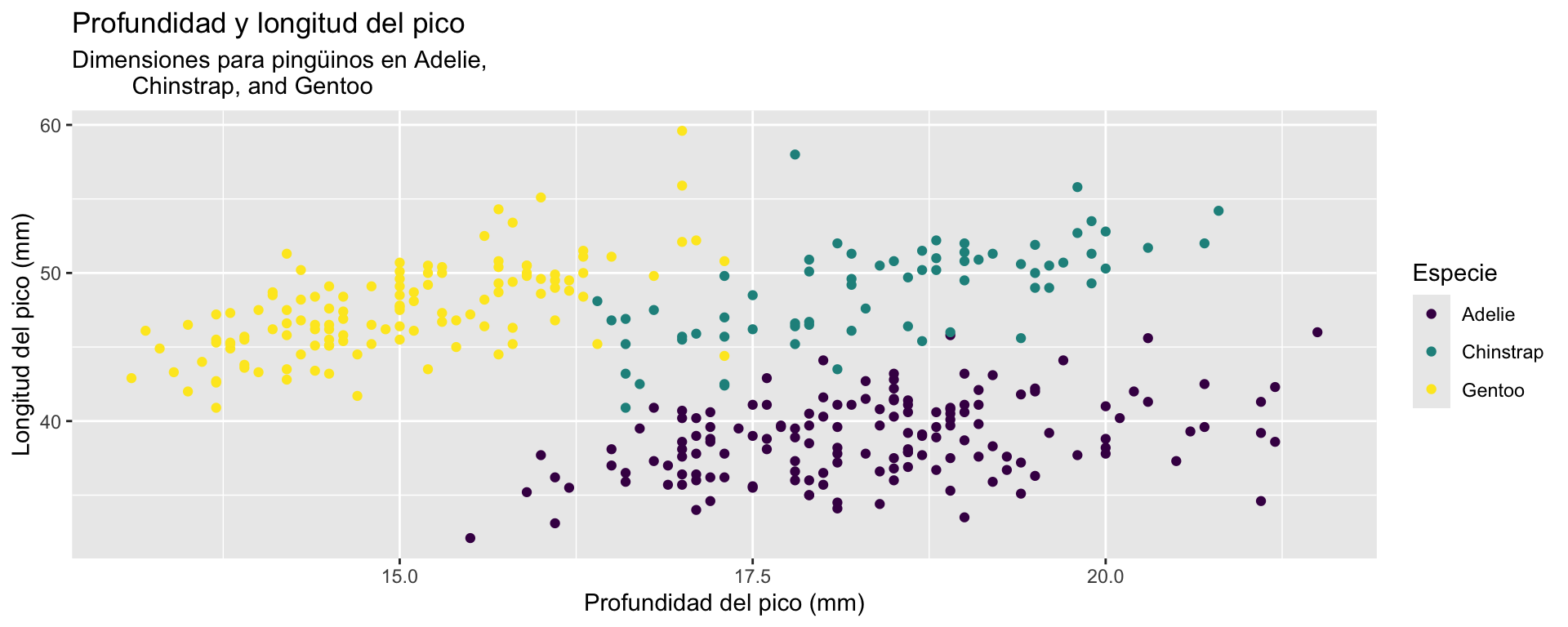
gf_point(bill_length_mm ~ bill_depth_mm, data = penguins_data, color =~species) +labs(title ="Profundidad y longitud del pico", subtitle ="Dimensiones para pingüinos en Adelie, Chinstrap, and Gentoo", x ="Profundidad del pico (mm)", y ="Longitud del pico (mm)",color ="Especie") +scale_color_viridis_d()