Hoy usaremos R para construir gráficas y tablas. Para esto, usaremos las librerías que ya vimos antes como readxl, ggplot2, ggformula, y dplyr.
Carguémoslas en R antes de comenzar.
# Nos se te olvide instalar la librería "ggformula" en Google Colab.# install.packages(ggformula)library(readxl)library(ggplot2)library(ggformula)library(dplyr)
Penguins Dataset
Ilustraremos los conceptos de hoy usando el conjunto de datos penguins.xlsx.
Súbelo a Google Colab y cárgalo en R usando el siguiente código.
penguins_data =read_excel("penguins.xlsx")
En Google Colab, el archivo debe de estar en la carpeta llamada “content” o “contenido.”
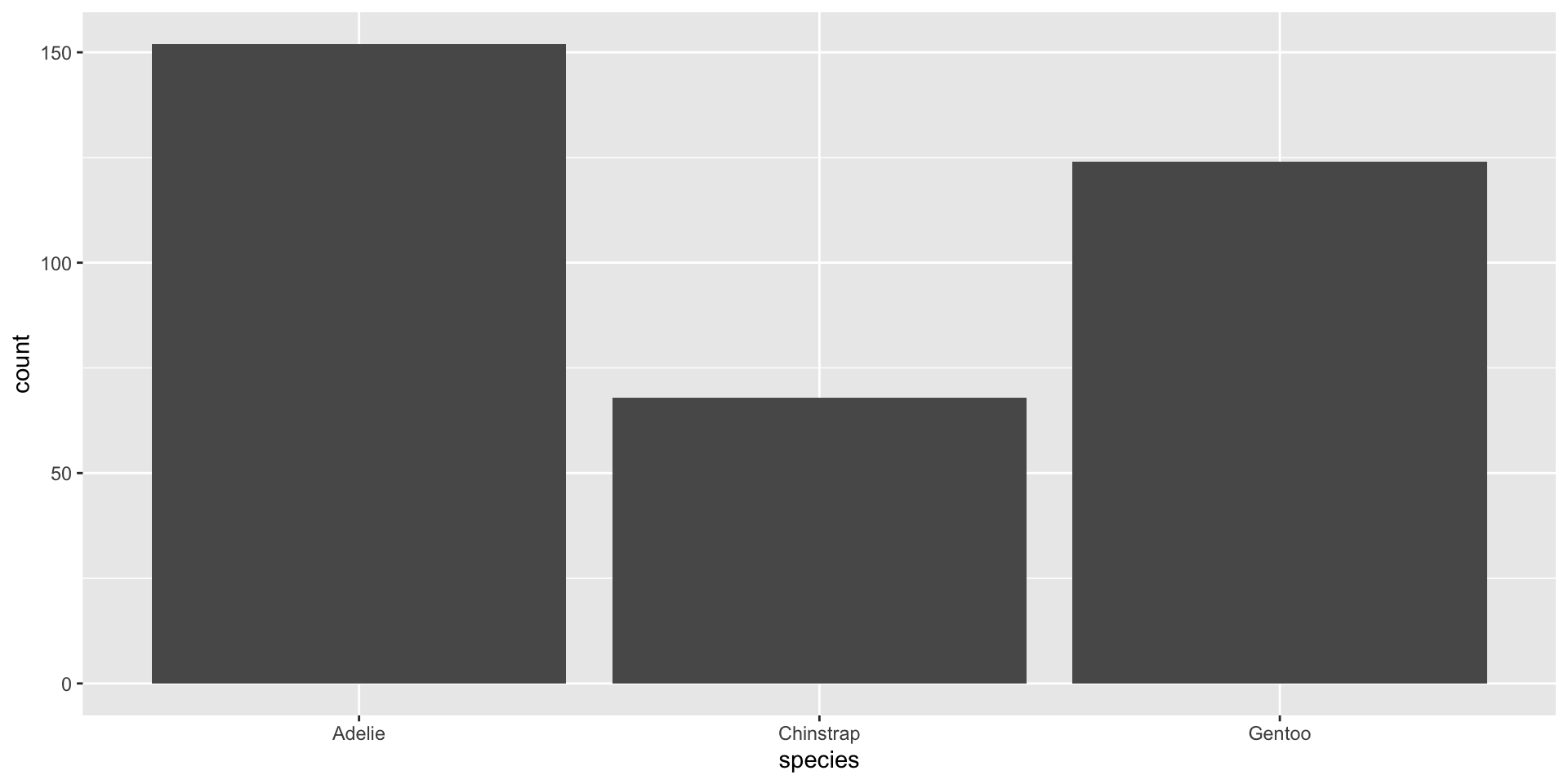
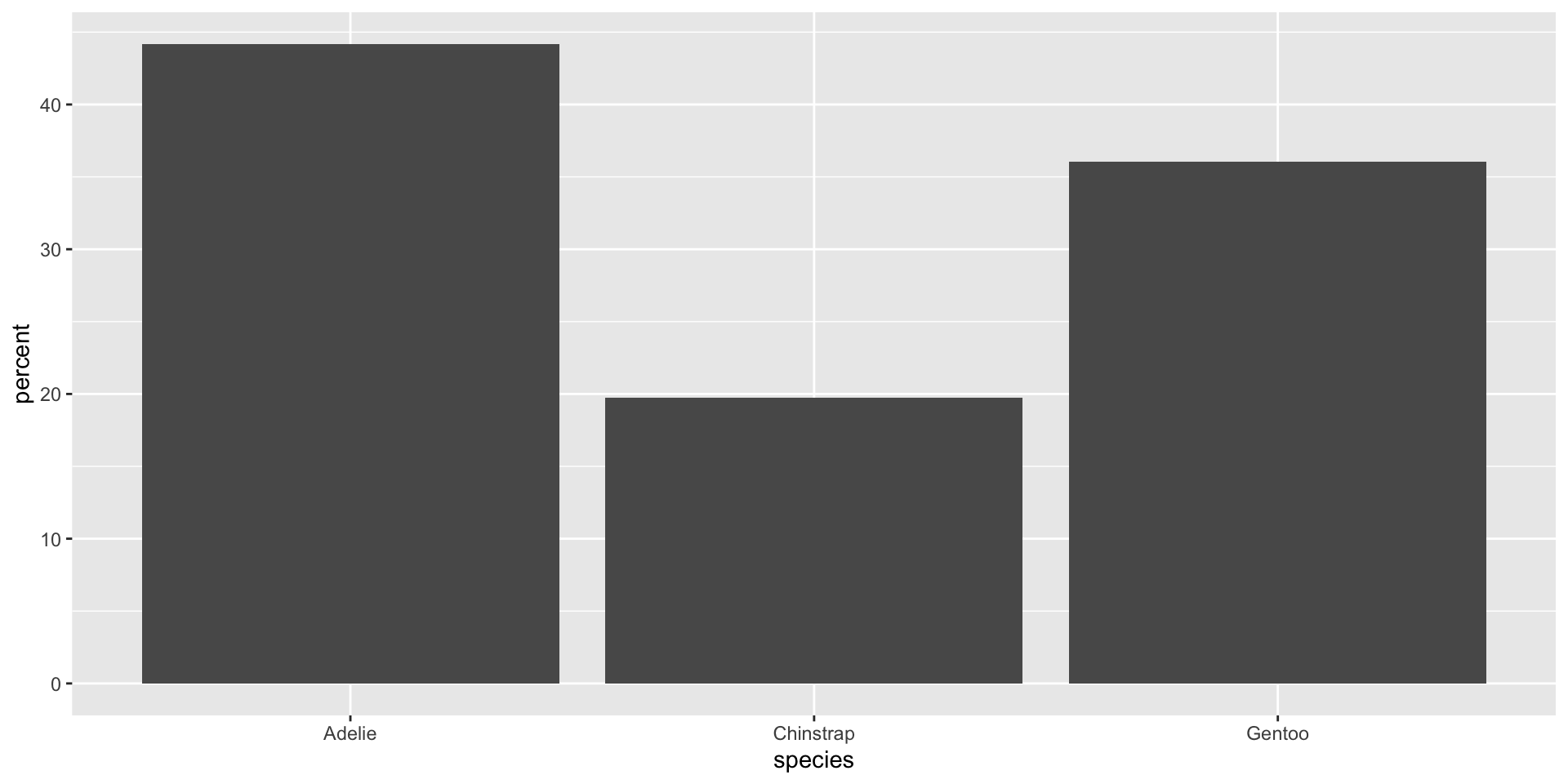
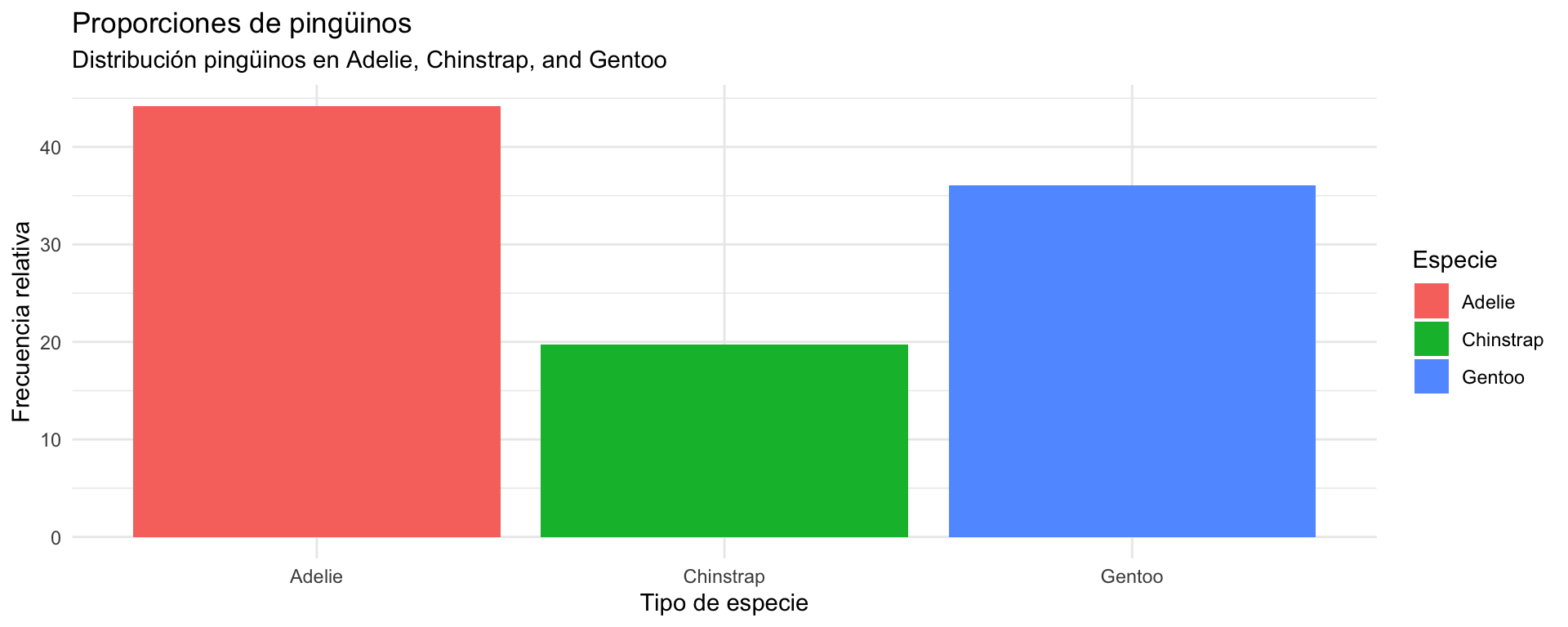
Hoy nos enfocaremos en visualizar las variables categóricas: species, island y sex.
penguins_data %>%select(species, island, sex) %>%head()
# A tibble: 6 × 3
species island sex
<chr> <chr> <chr>
1 Adelie Torgersen male
2 Adelie Torgersen female
3 Adelie Torgersen female
4 Adelie Torgersen <NA>
5 Adelie Torgersen female
6 Adelie Torgersen male
Asegúrate que R sabe que la variable es categórica
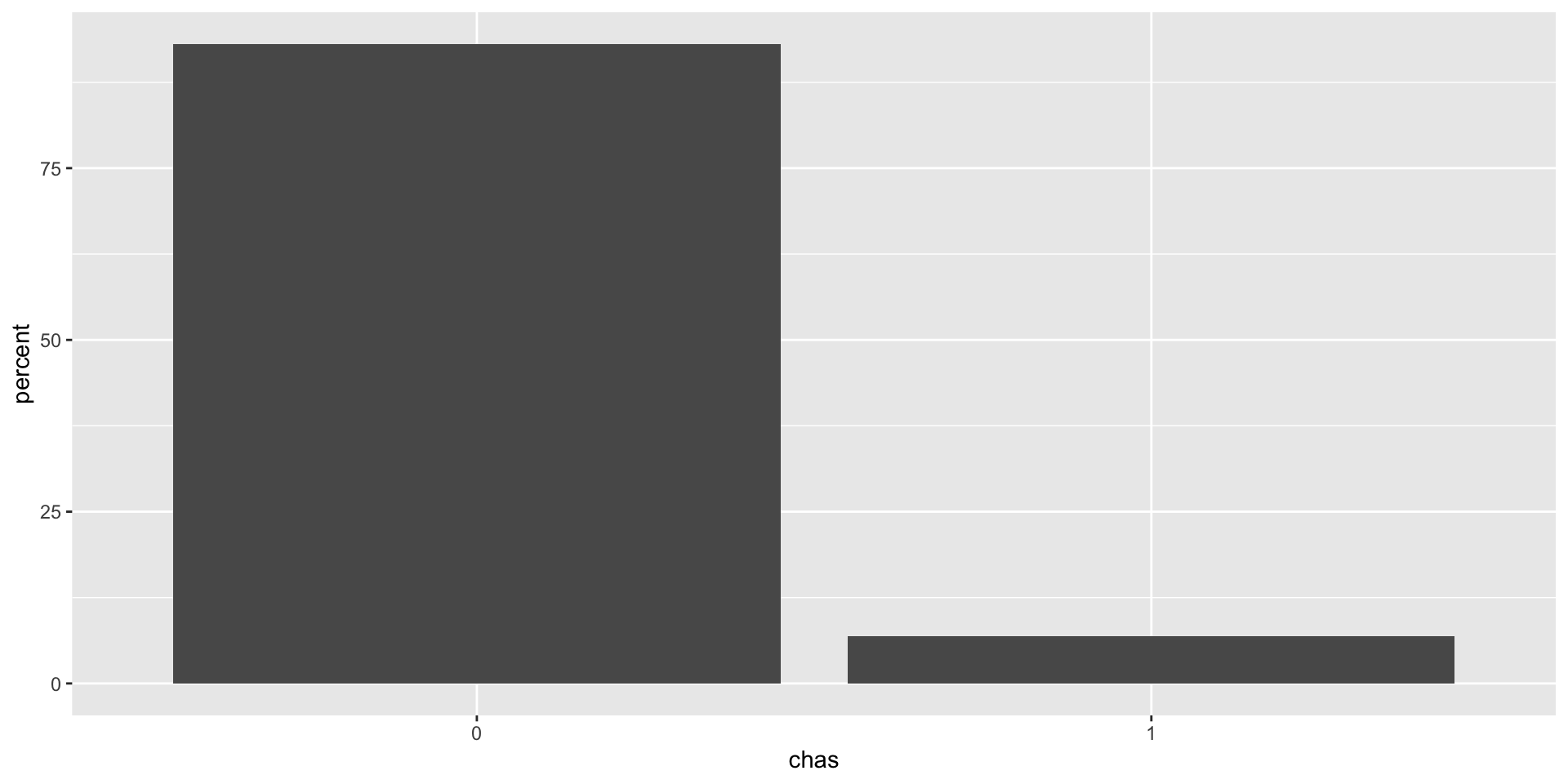
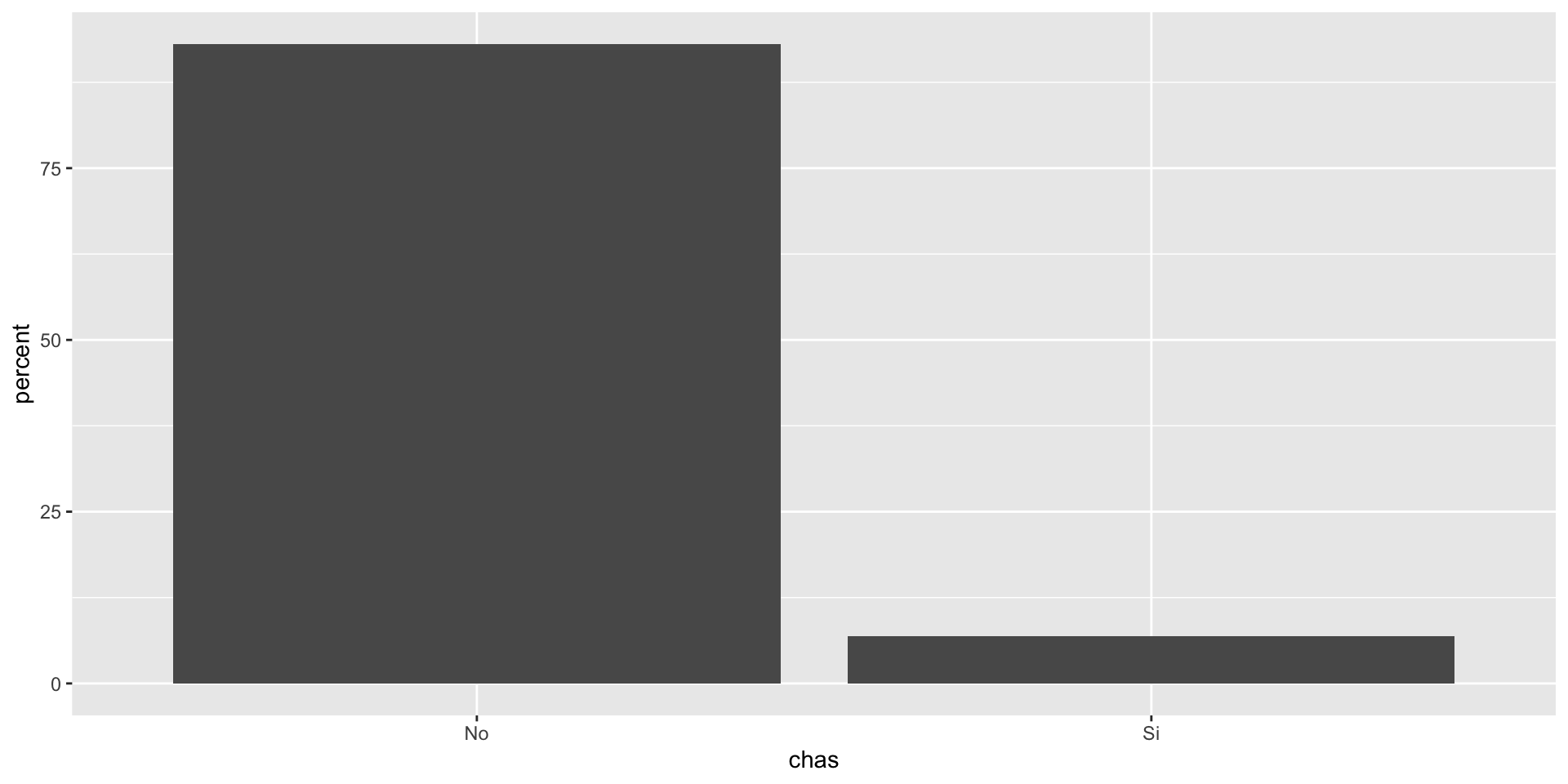
A pesar de que la variables species, island y sex son claramente categóricas, R no reconoce esto.
Por default, R determina que esas variables son carácter o chr porque están compuestas por texto.
En R, las variables categóricas se conocen como factor o fct.
Definiendo variables categóricas en R
Para asegurarnos que R sepa que la variable es categórica o fct, usamos la función mutate_at() de dplyr:
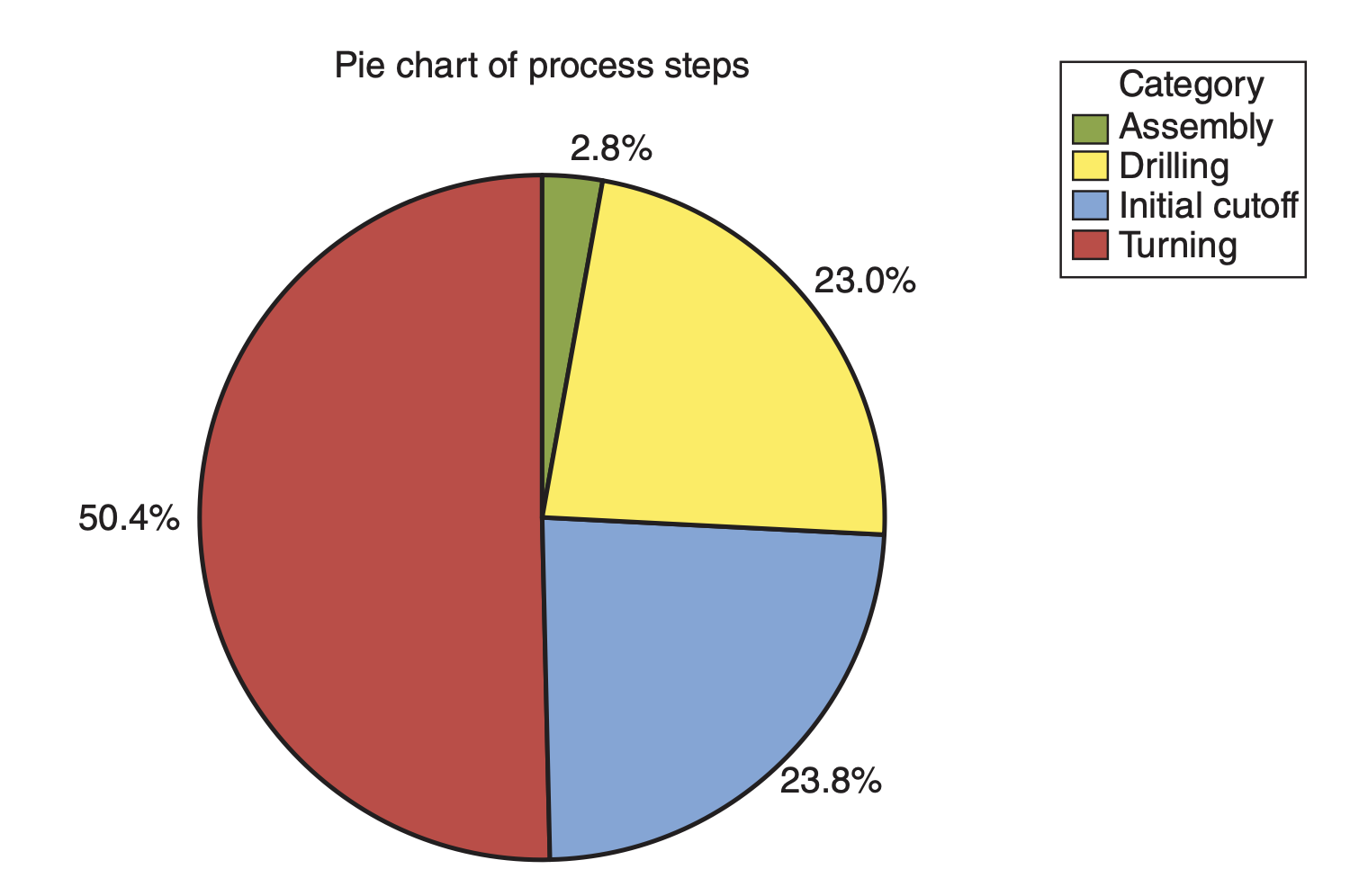
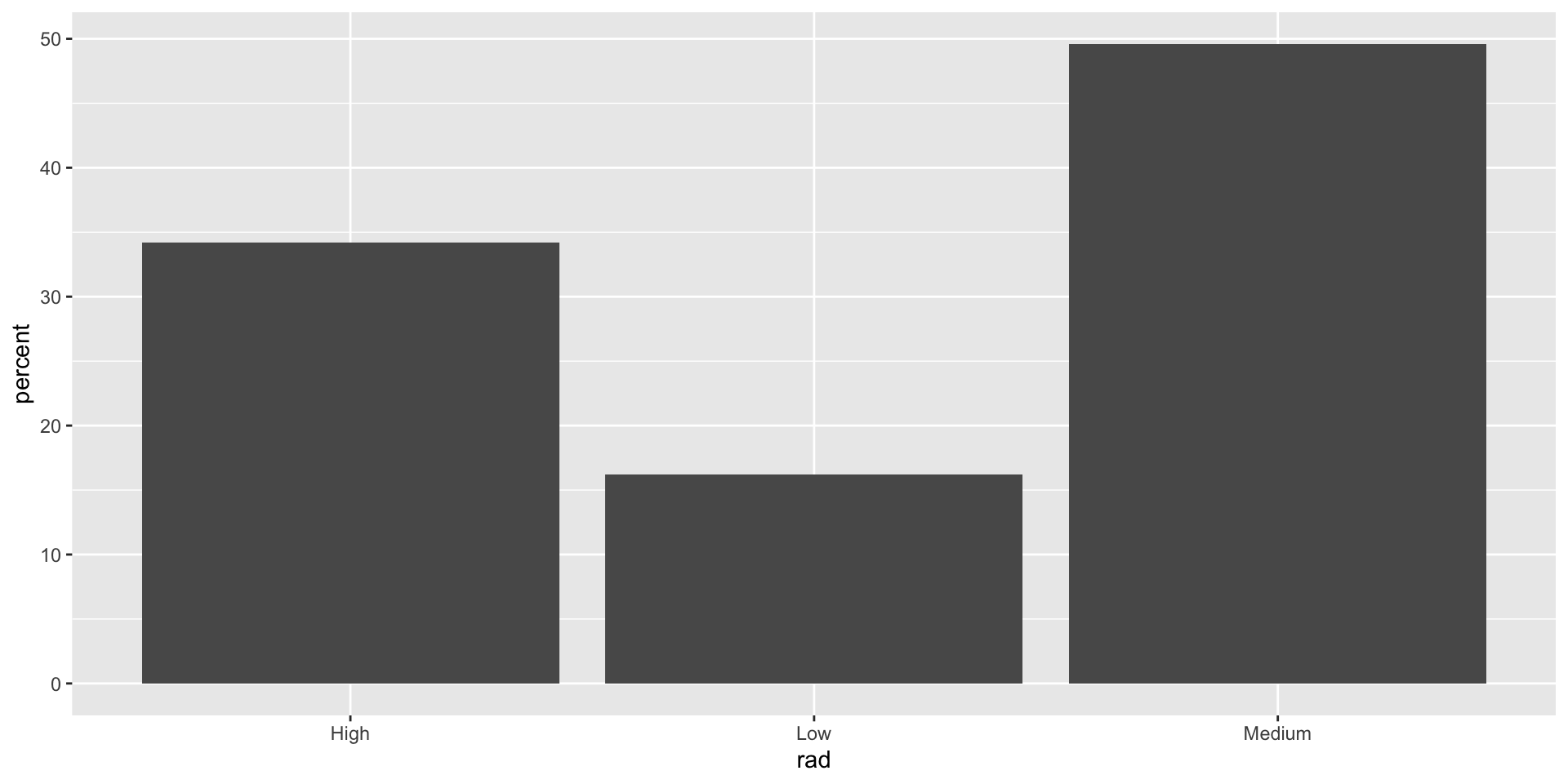
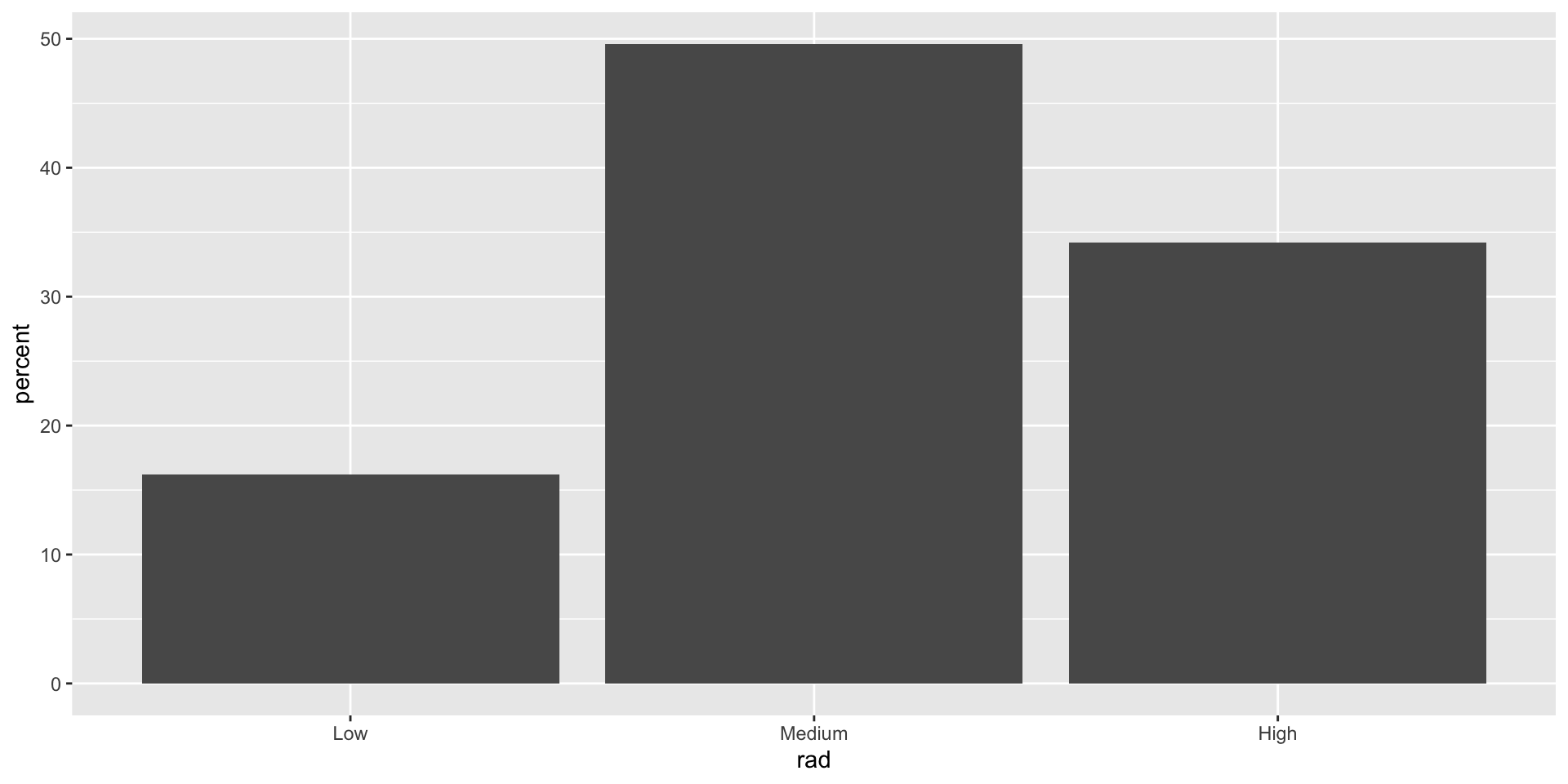
Algunas variables categóricas tienden a tener muchas categorías. Por ejemplo, los estados de un pais o códigos postales. En estos casos, puede ser difícil visualizar de todas las categórias en una sola gráfica.
Una estrategia para desarrollar una visualización efectiva es colapsar categorías.
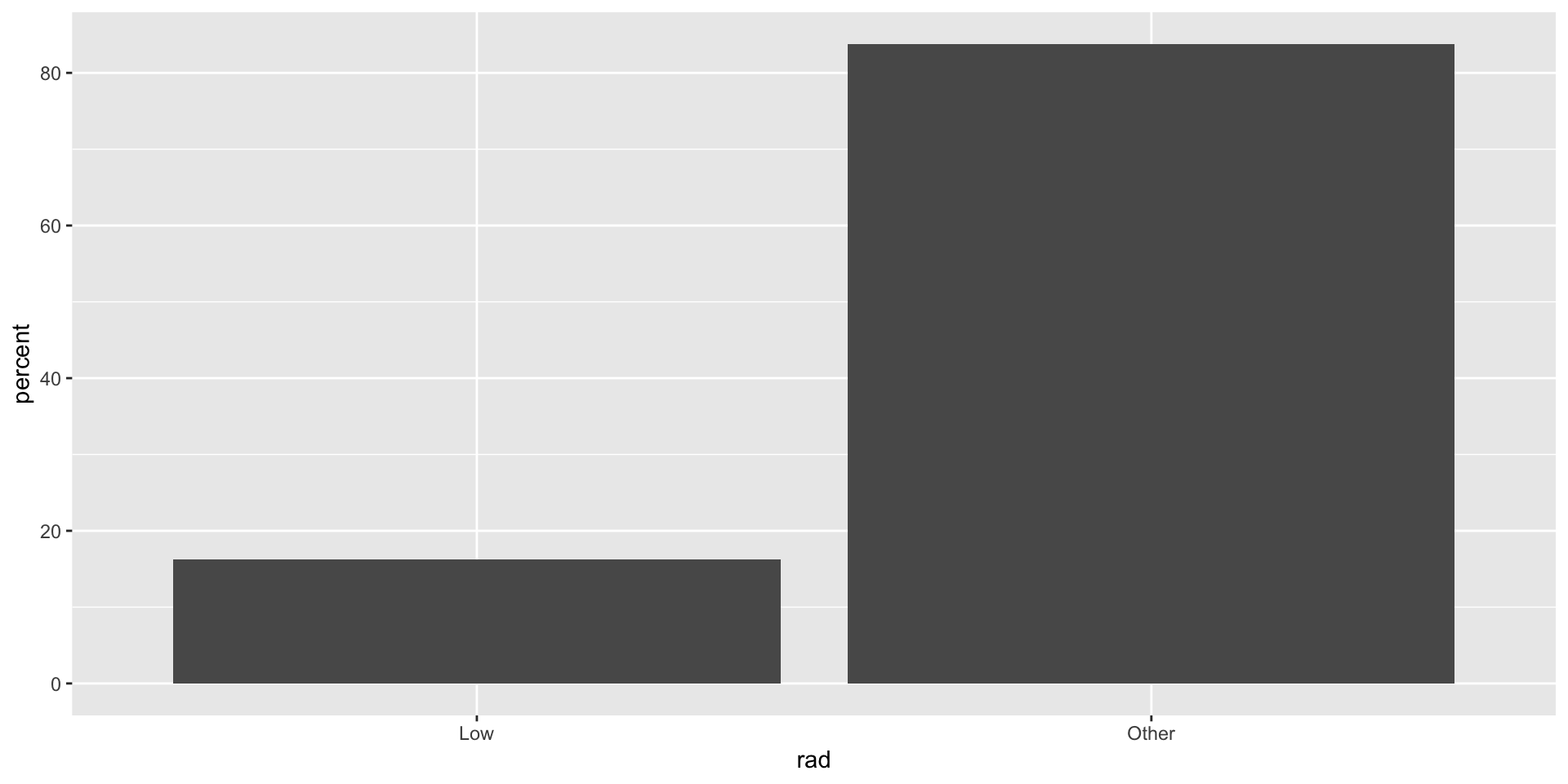
Por ejemplo, en la variable rad, podemos collapsar las categorías Medium y High en una sola categoría llamada Other.
Para colapsar categorías en dplyr, usamos la función case_when() junto con mutate(). La función case_when() permite remplazar categorías usando expreciones lógicas en variables específicas.
Boston_dataset %>%mutate(rad =case_when(rad !="Low"~"Other", rad =="Low"~"Low")) %>%head()