Introducción a la Regresión Lineal Simple
IN2039: Visualización de Datos
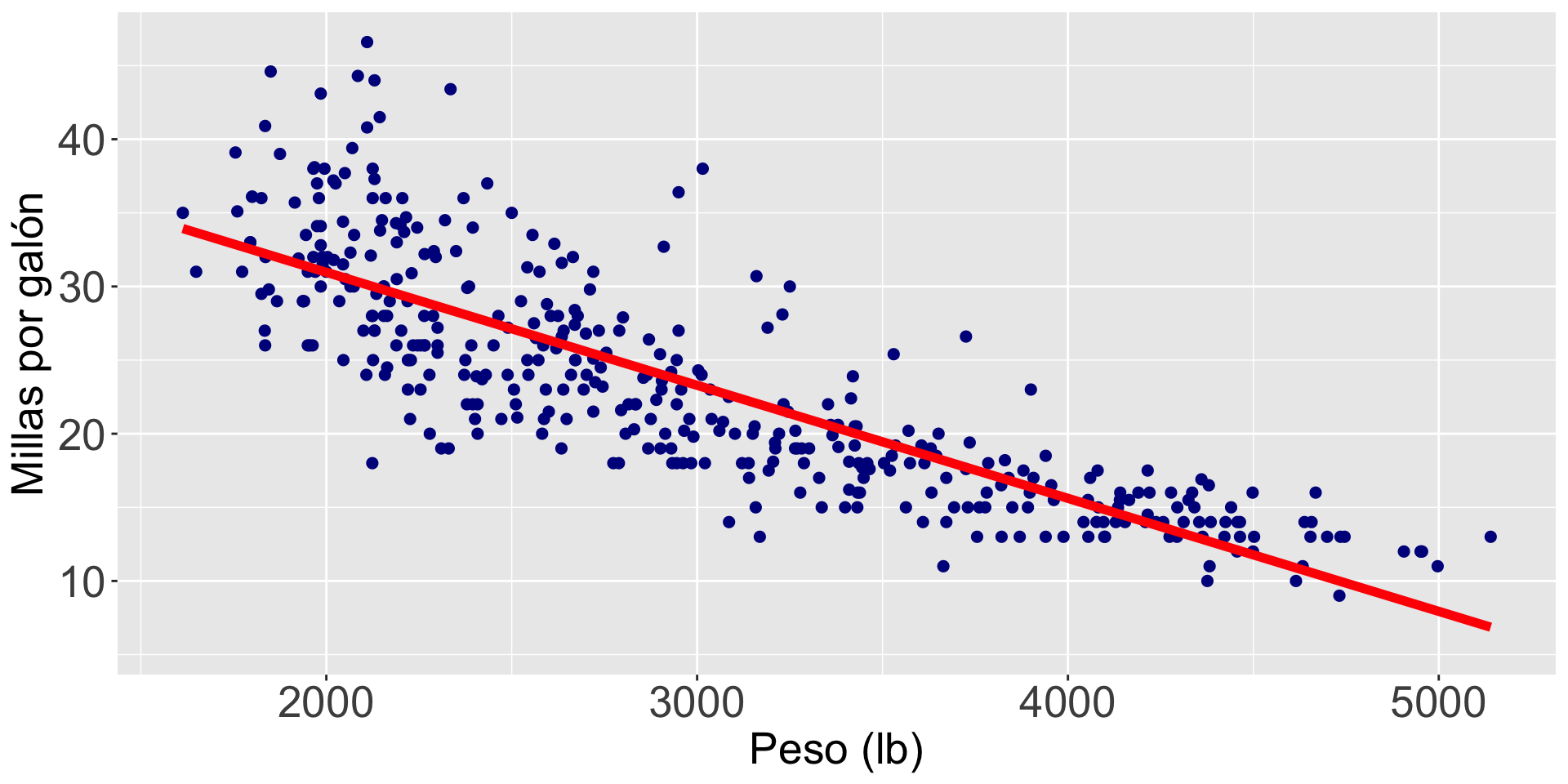
¿Hay una relación entre el peso de un auto y sus millas por galón?
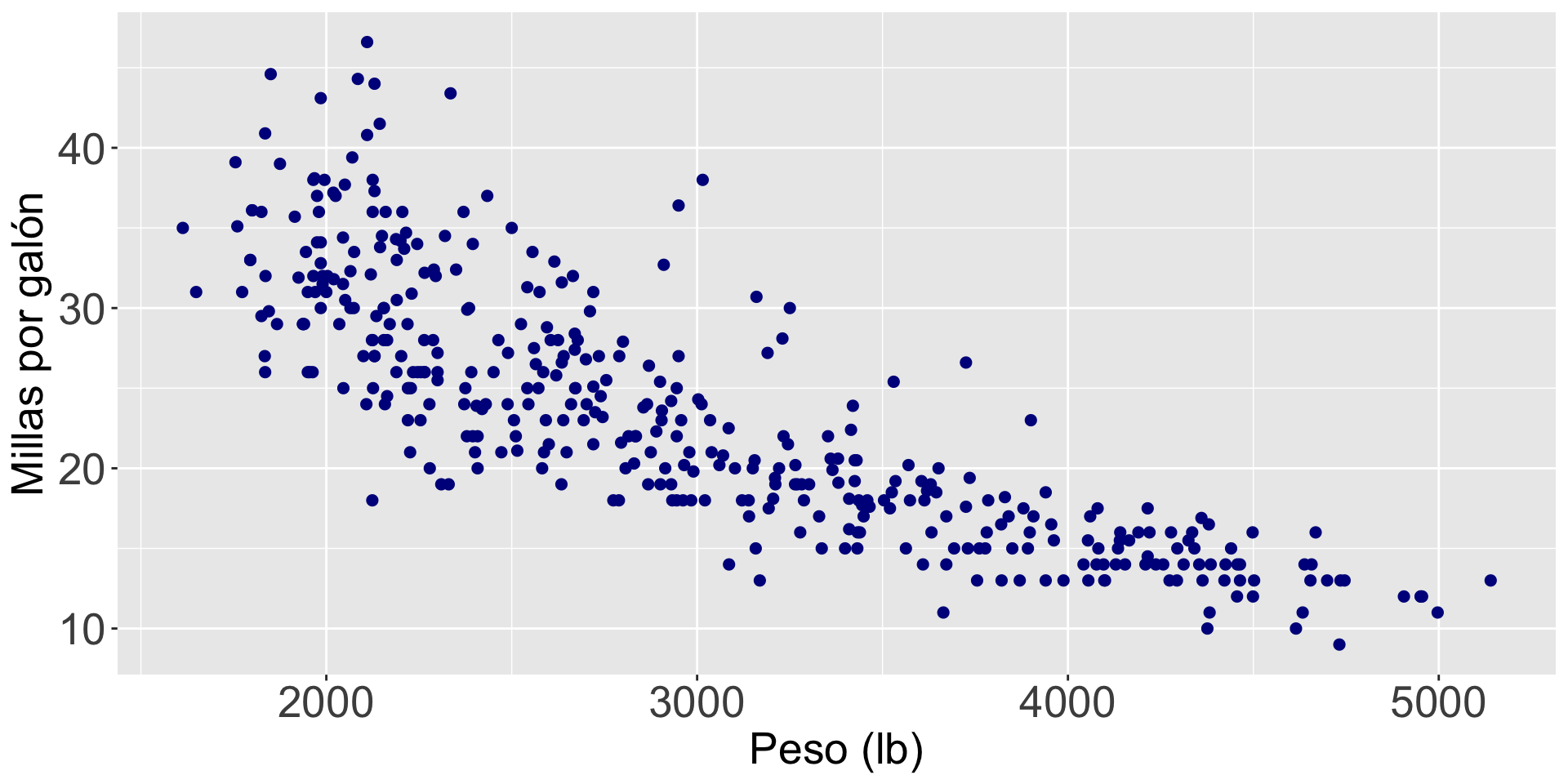
Ajustando modelos de regresión en R
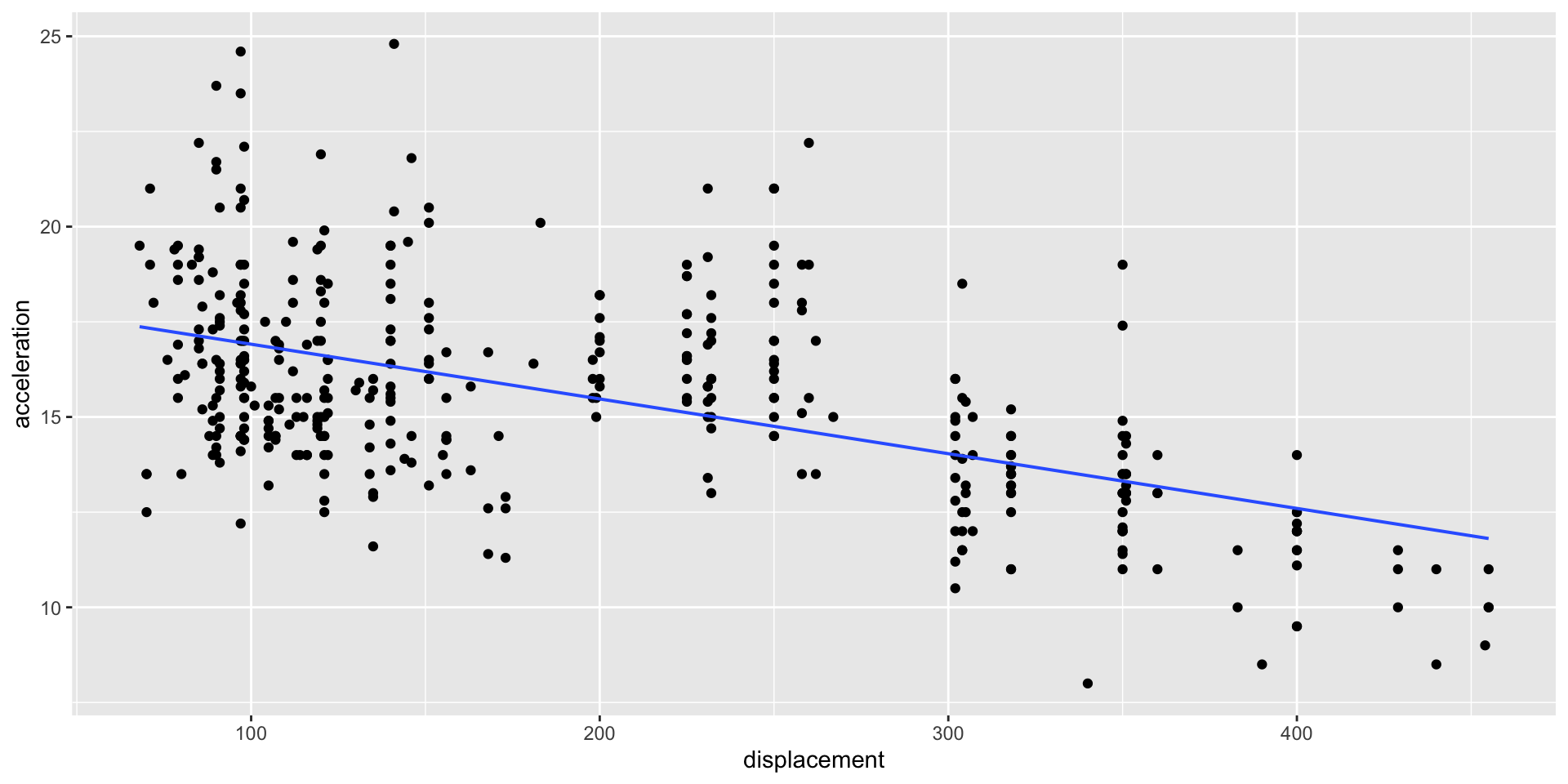
Para ajustar un modelo de regresión lineal usamos el comando pipe %>% junto con la función gf_lm().
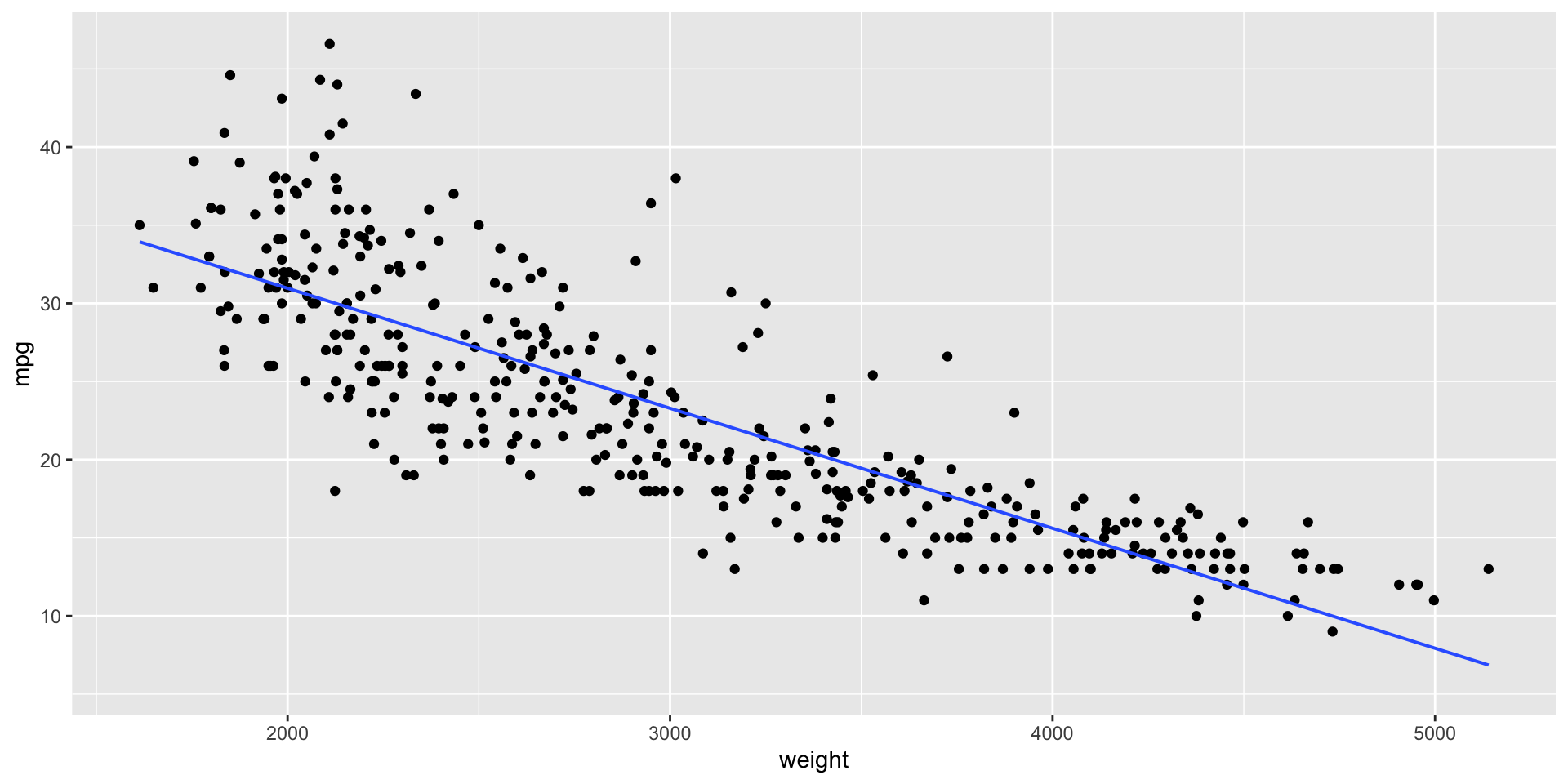
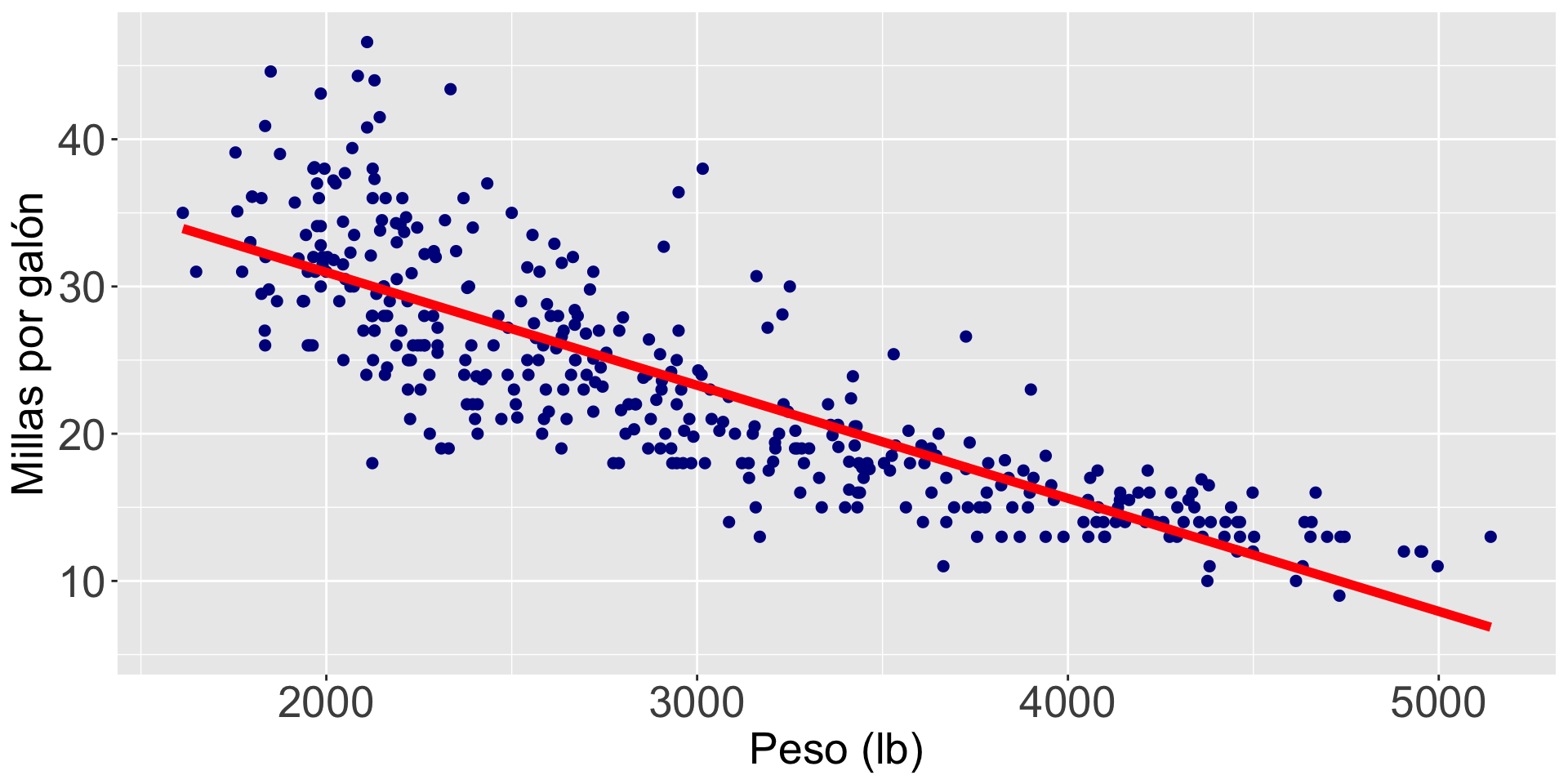
Podemos afectar el color, grosor, y tipo de linea usando los argumentos color, linewidth, y lty, respectivamente, en la función gf_lm().
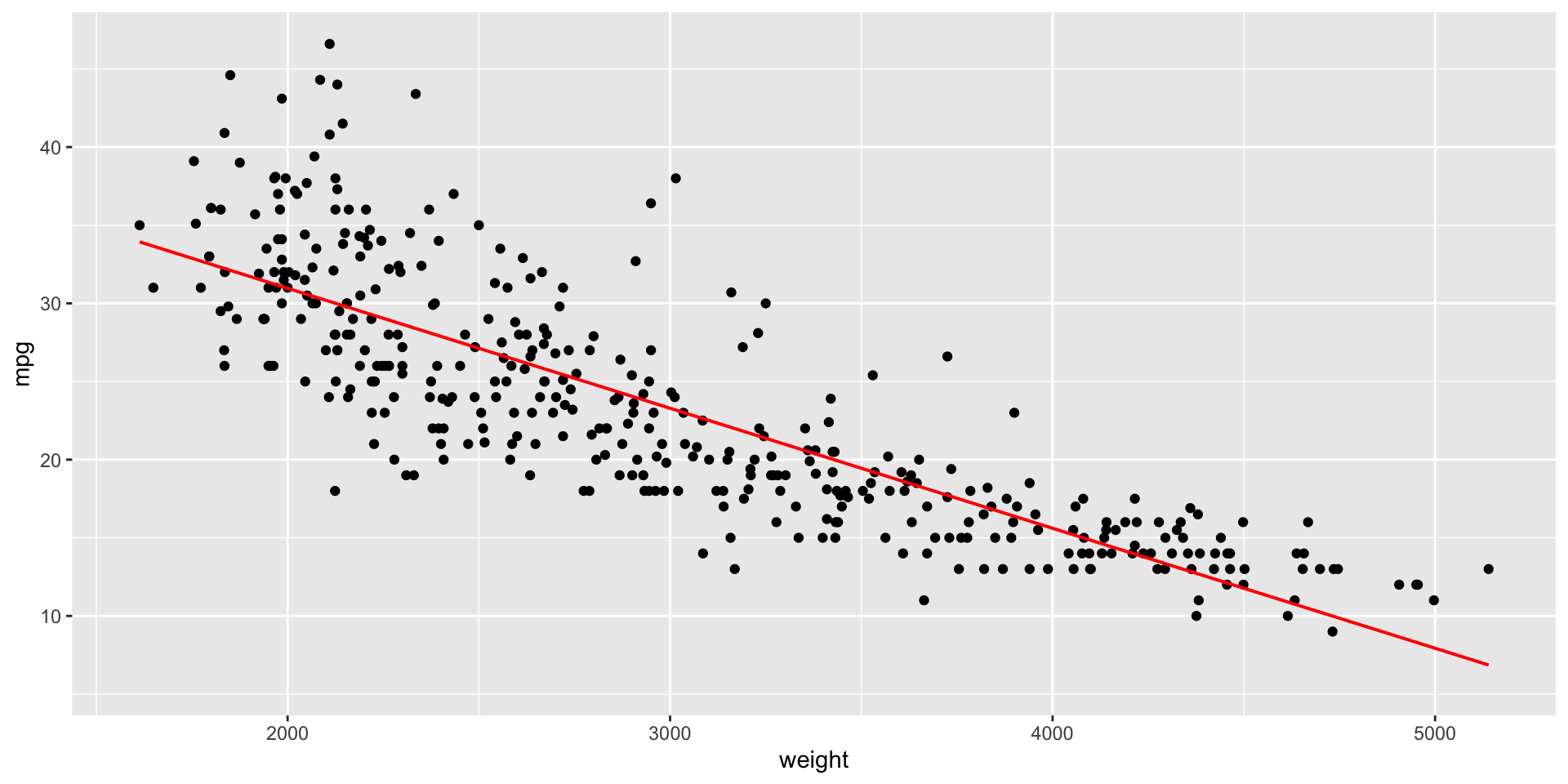
Para nuestro ejemplo
\(\hat{Y}_i = 46.32 -0.0076 X_i\)
La fórmula
\(\text{mpg}_i = 46.32 - 0.0076 \times \text{peso}_i\)
Interpretación de los coefficientes
¿Qué significa \(\hat{\beta}_0 = 46.32\)?
\(\hat{\beta}_0\) es el valor promedio de la respuesta cuando \(X_i = 0\).
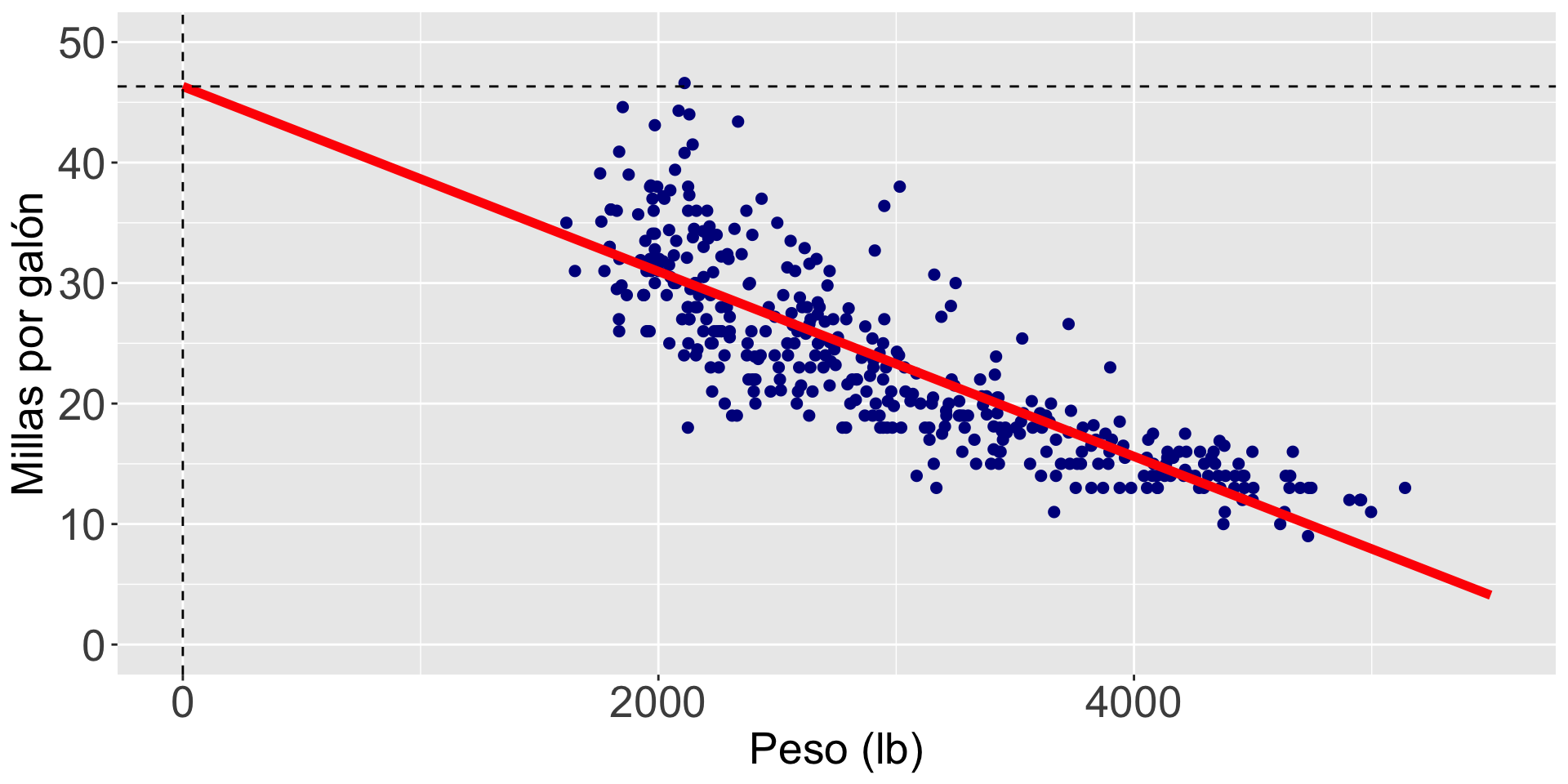
¿Tiene sentido \(\hat{\beta}_0 = 46.32\)?
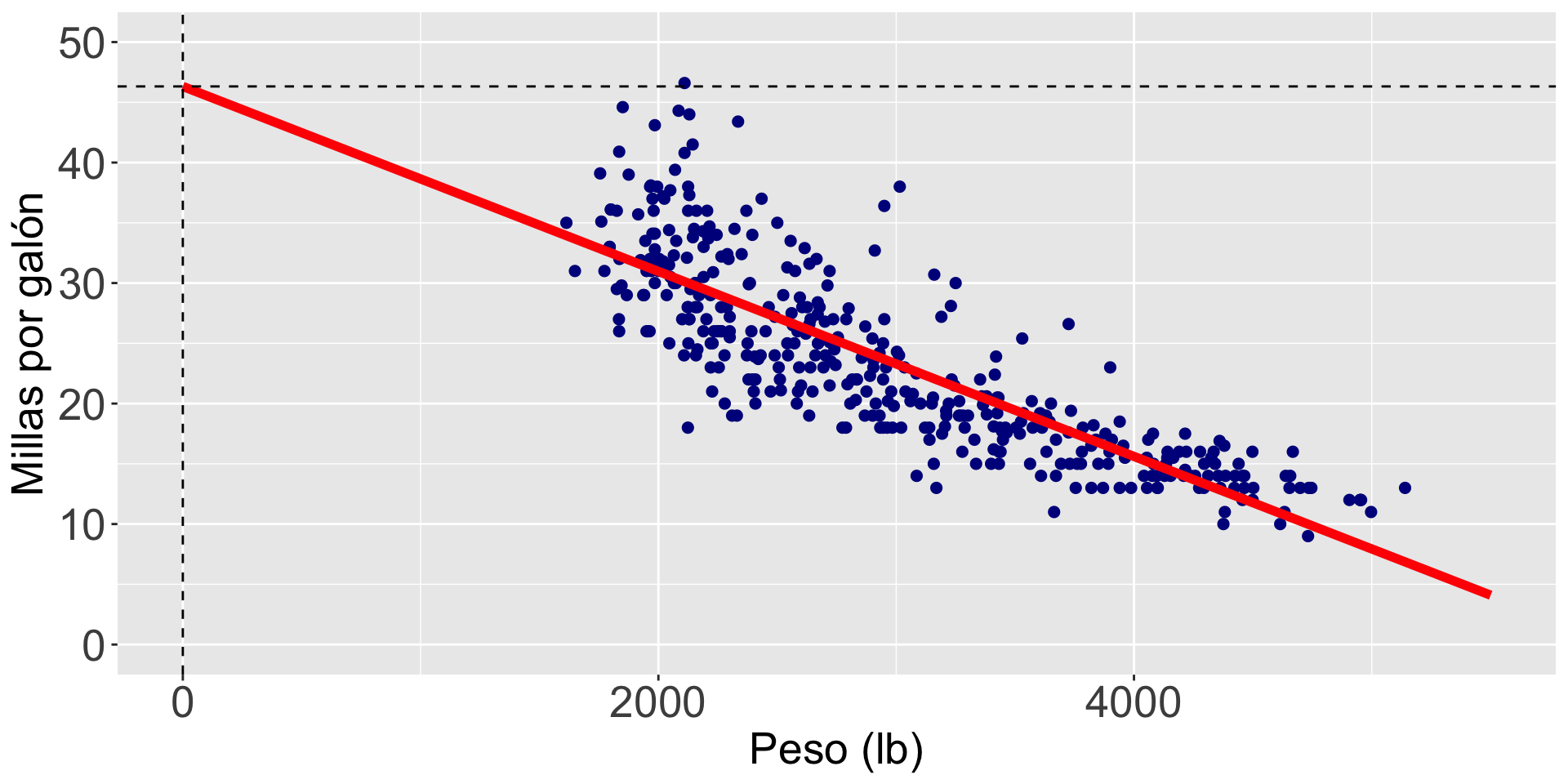
No! Porque no hay autos con un peso igual a 0.
¿Qué significa \(\hat{\beta}_1 = - 0.0076\)?
\(\hat{\beta}_1\) es el cambio promedio en la respuesta al aumentar \(X_i\) en una unidad.
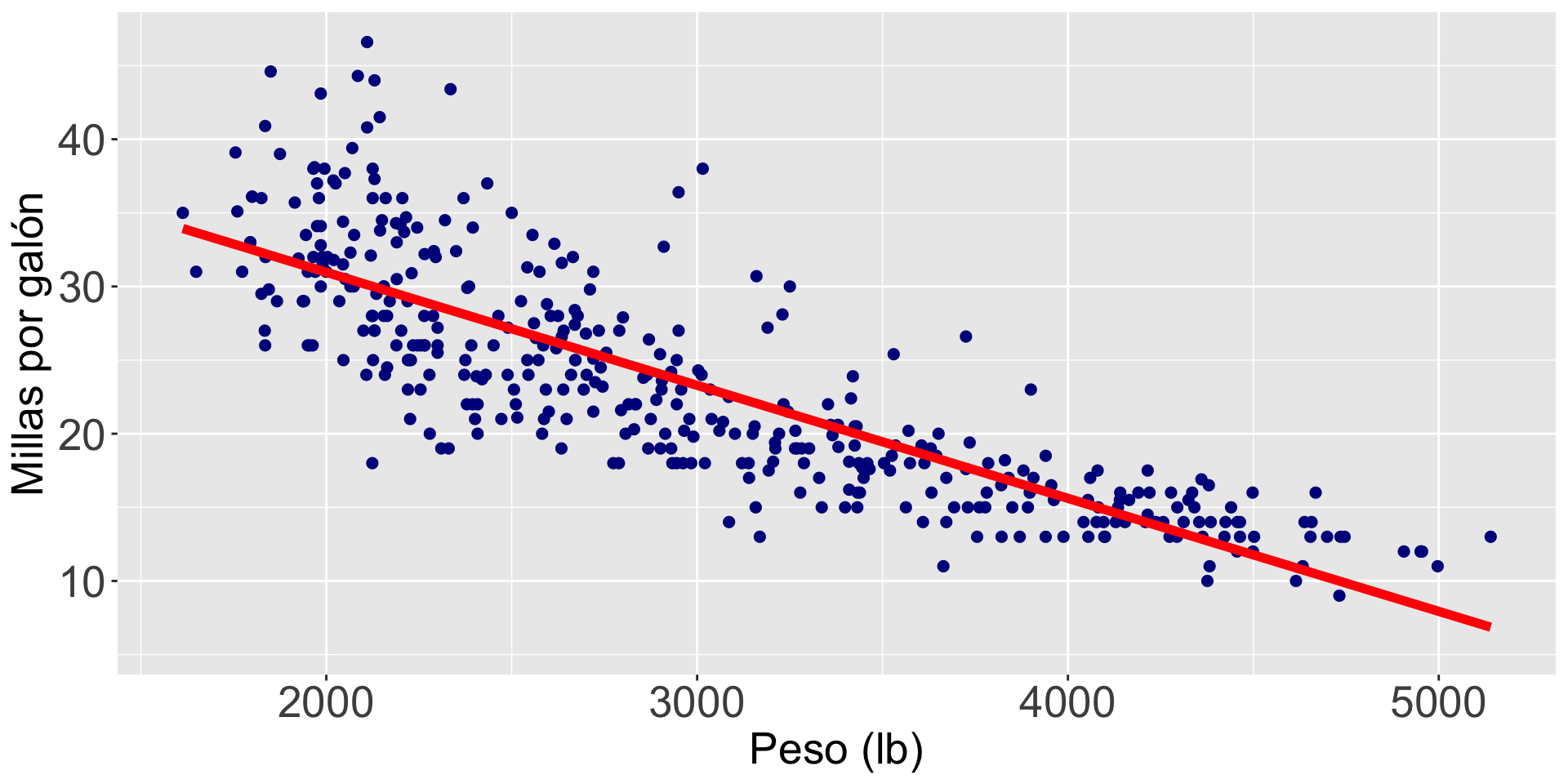
Dispersión constante
Code
mi_modelo = lm(mpg ~ weight, data = auto_data)
datos_modelo = tibble("Predicciones" = mi_modelo$fitted,
"Errores" = mi_modelo$residuals)
mi_diagrama_residuos = gf_point(Errores ~ Predicciones, data = datos_modelo, color = "darkblue", size = 2)
mi_diagrama_residuos = mi_diagrama_residuos + theme(axis.text=element_text(size=20), axis.title=element_text(size=20))
mi_diagrama_residuos = mi_diagrama_residuos %>% gf_hline(yintercept = 0, lty = 2)
mi_diagrama_residuos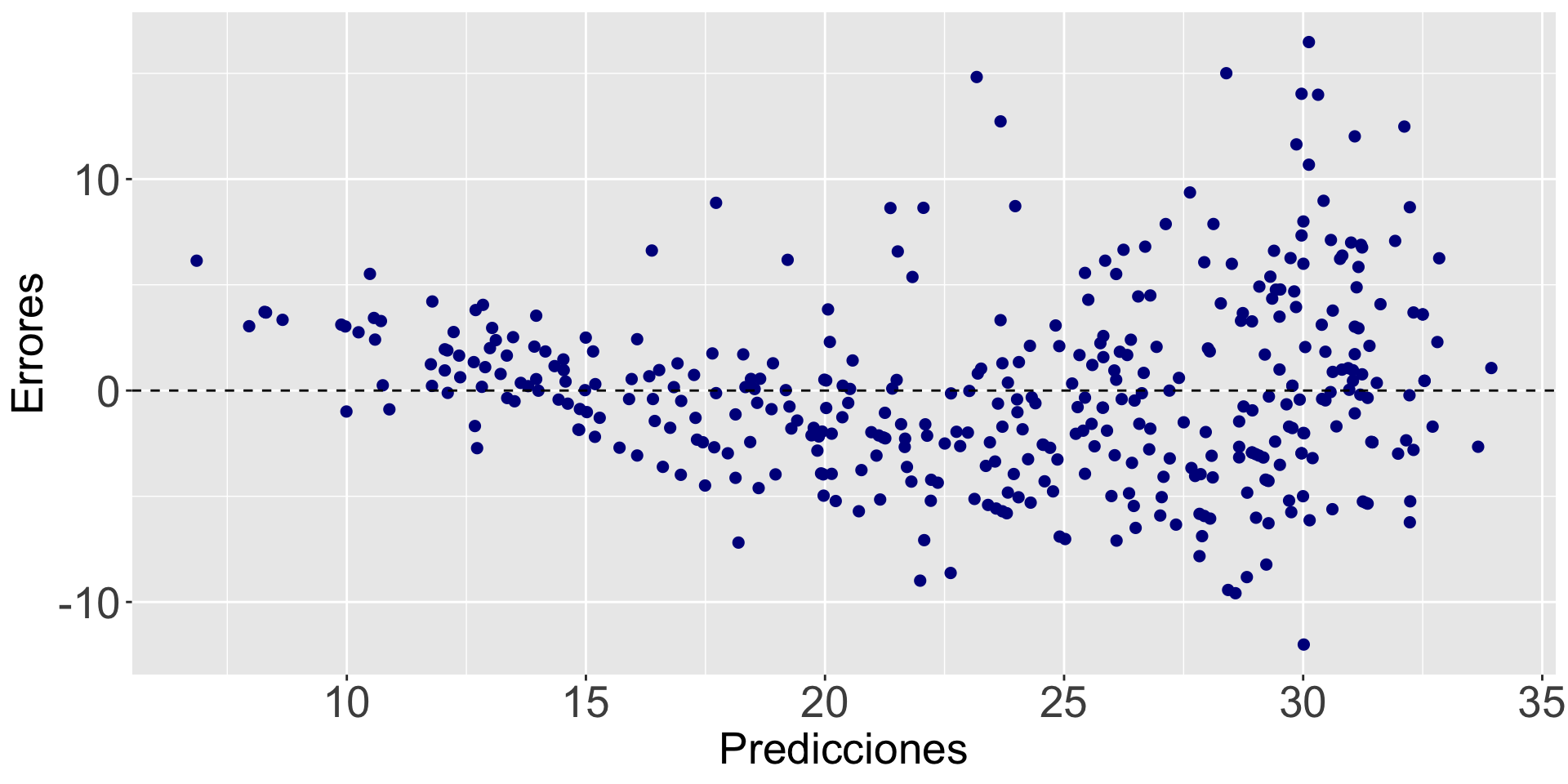
Errores independientes
Code
mi_modelo = lm(mpg ~ weight, data = auto_data)
datos_modelo = tibble("Tiempo" = 1:nrow(auto_data),
"Errores" = mi_modelo$residuals)
mi_diagrama_residuos = gf_point(Errores ~ Tiempo, data = datos_modelo, color = "darkblue", size = 2)
mi_diagrama_residuos = mi_diagrama_residuos + theme(axis.text=element_text(size=20), axis.title=element_text(size=20))
mi_diagrama_residuos = mi_diagrama_residuos %>% gf_hline(yintercept = 0, lty = 2)
mi_diagrama_residuos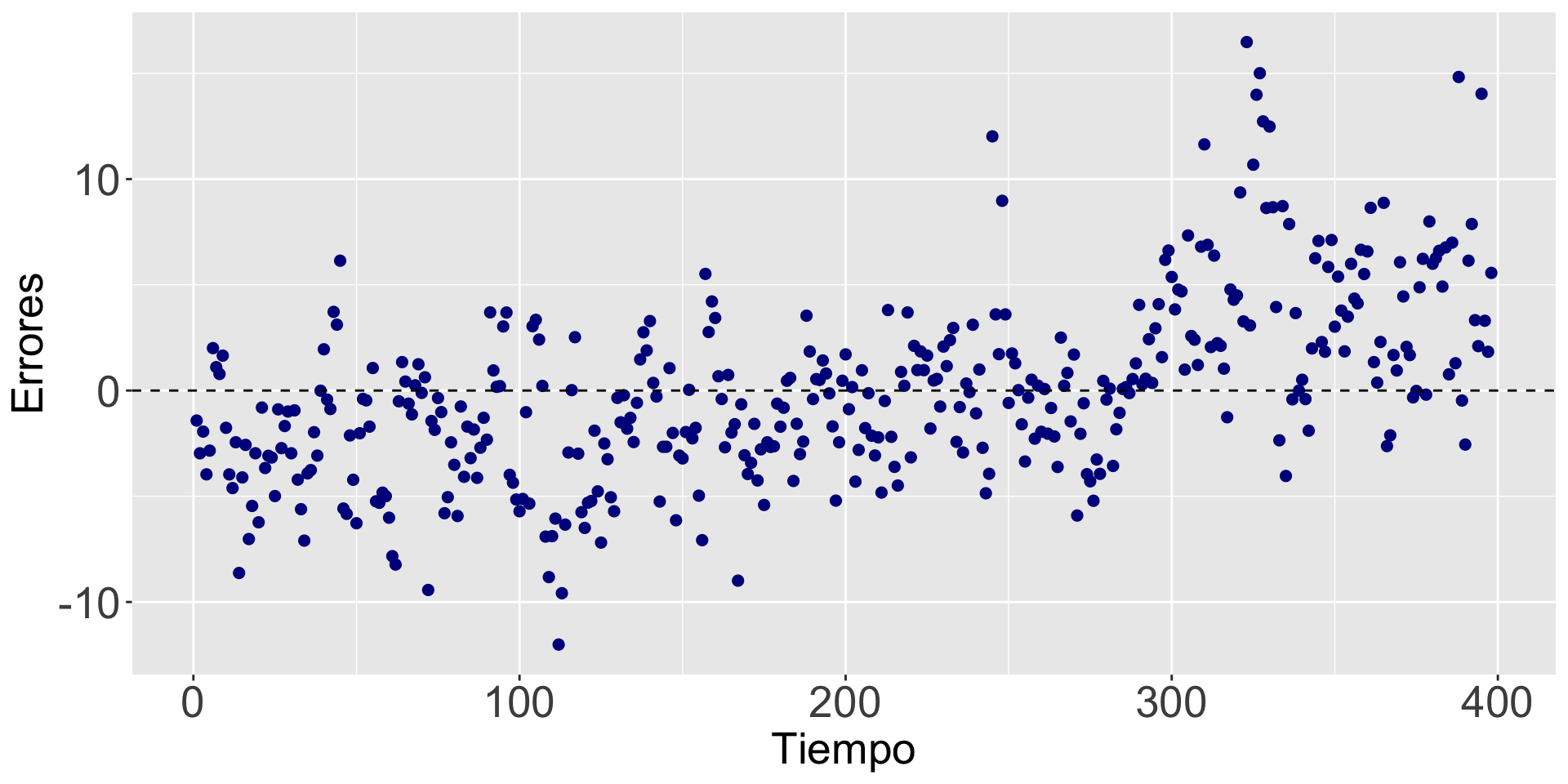
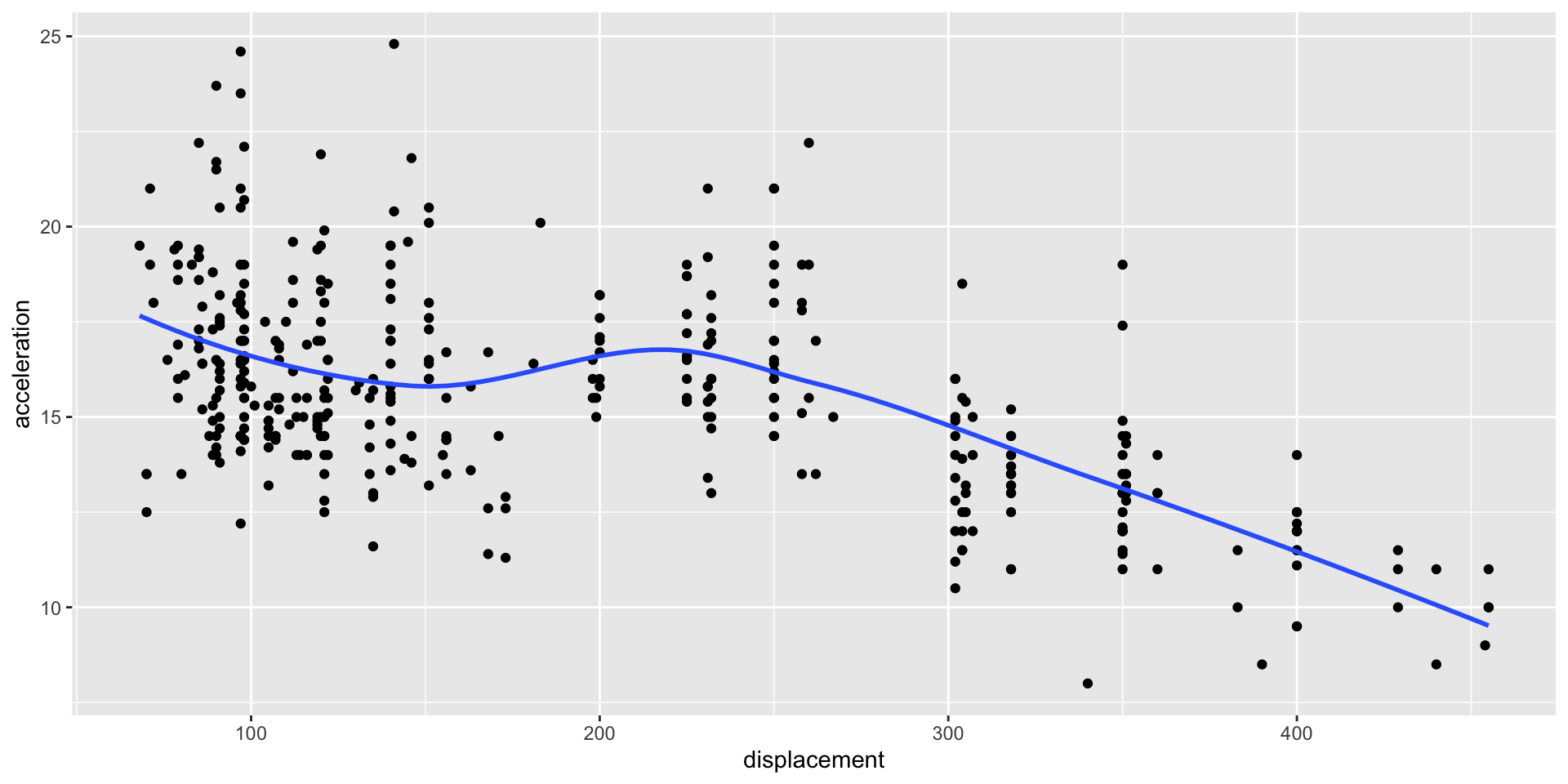
En R, ajustamos una regresión local usando la función gf_smooth().
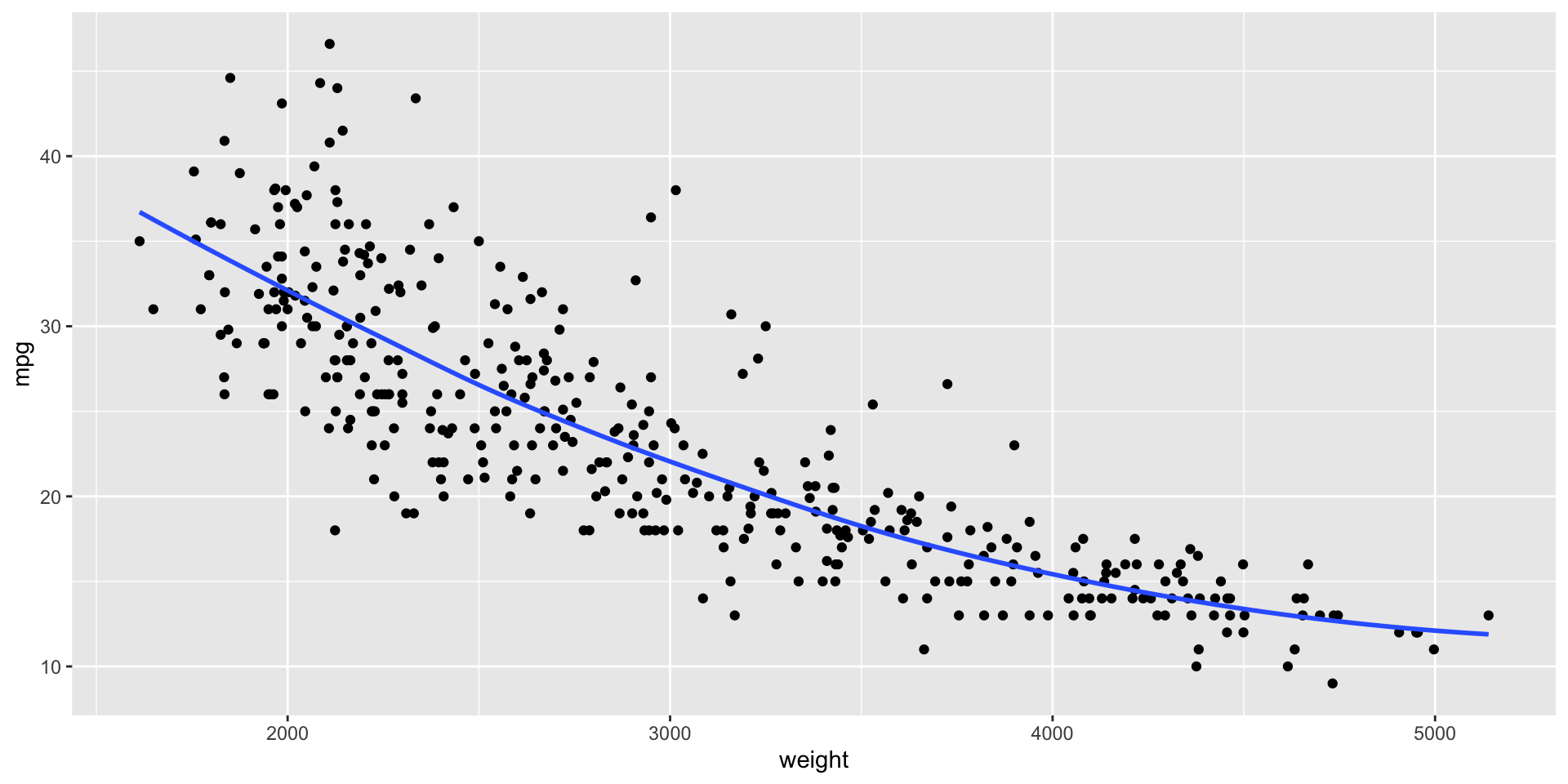
Podemos cambiar el color, grosor, y tipo de linea usando los argumentos color, linewidth, y lty, respectivamente, en la función gf_smooth().
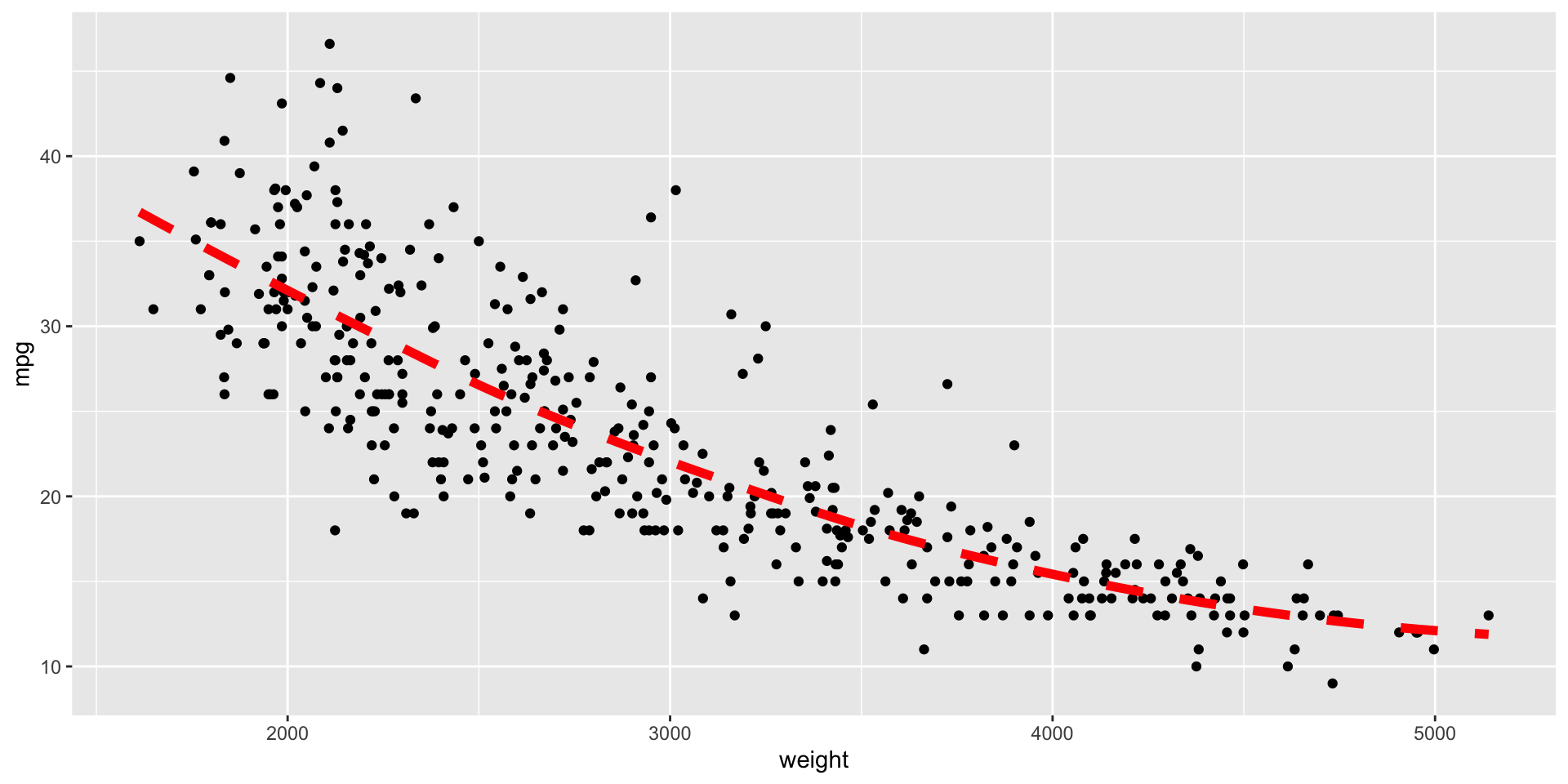
Otro ejemplo
Consideremos la relación entre la aceleración de los autos (acceleration) y el volumen total de todos los cilindros del motor (displacement).
Regresión lineal
Regresión local
Regresar a página principal
![]()