IN5148: Statistics and Data Science with Applications in Engineering
Alan R. Vazquez
Department of Industrial Engineering
Agenda
Residual analysis
Inference about individual \(\beta\)’s using t-tests
Load the libraries
Let’s import the required libraries into Python together with other relevant libraries.
# Importing necessary librariesimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionimport statsmodels.api as sm
We will introduce the new library statsmodels.api later.
Inference about individual \(\beta\)’s using t-tests
Linear Regression Model
Recall that the linear regression model is a common candidate function for predicting a response:
Where \(i = 1, \ldots, n_t\) is the index of the \(n_t\) training data.
\(\hat{Y}_i\) is the prediction of the actual value of the response \(Y_i\) associated with values of \(p\) predictors denoted by \(\boldsymbol{X}_i = (X_{i1}, \ldots, X_{ip})\).
The values \(\hat{\beta}_0\), \(\hat{\beta}_1\), …, \(\hat{\beta}_p\) are the coefficients of the model.
Example 1
Let’s consider the “auto.xlsx” dataset.
auto_data = pd.read_excel('auto.xlsx')
Let’s assume that we want to train the following model.
where \(\hat{Y}_i\) is the predicted mpg, \(X_{i1}\) is the weight, and \(X_{i2}\) is the acceleration of the \(i\)-th car, \(i = 1, \ldots, 392\).
Here, we will use the entire dataset for training and ignore \(K\)-fold cross-validation to illustrate the concepts.
Research question
Do the weight and acceleration have a significant association with the mpg of a car?
The two cultures of statistical models
Inference: develop a model that fits the data well. Then make inferences about the data-generating process based on the structure of such model.
Prediction: Silent about the underlying mechanism generating the data and allow for many predictive algorithms, which only care about accuracy of predictions.
They overlap very often.
The least squares estimates \(\hat{\beta}_0, \hat{\beta}_1, \ldots, \hat{\beta}_p\) are subject to uncertainty, since they are calculated based on a random sample of data. That is, an instance of training data.
Therefore, assessing the amount of the uncertainty in these estimates is important. To this end, we use hypothesis tests on individual coefficients.
Hypothesis test
A statistical hypothesis is a statement about the coefficients of a model.
\(\hat{\beta}_j\) is the least squares estimate of the true coefficient \(\beta_j\).
\(\sqrt{\hat{v}_{jj}}\) is the standard error of the estimate \(\hat{\beta}_j\) calculated using Python.
Recall that we obtain the least squares estimates (\(\hat{\beta}_{j}\)) in Python using:
# 1. Create the linear regression modelLRmodel = LinearRegression()# 2. Fit the model.LRmodel.fit(auto_X_train, auto_Y_train)# 3. Show estimated coefficients.print("Intercept:", LRmodel.intercept_)print("Coefficients:", LRmodel.coef_)
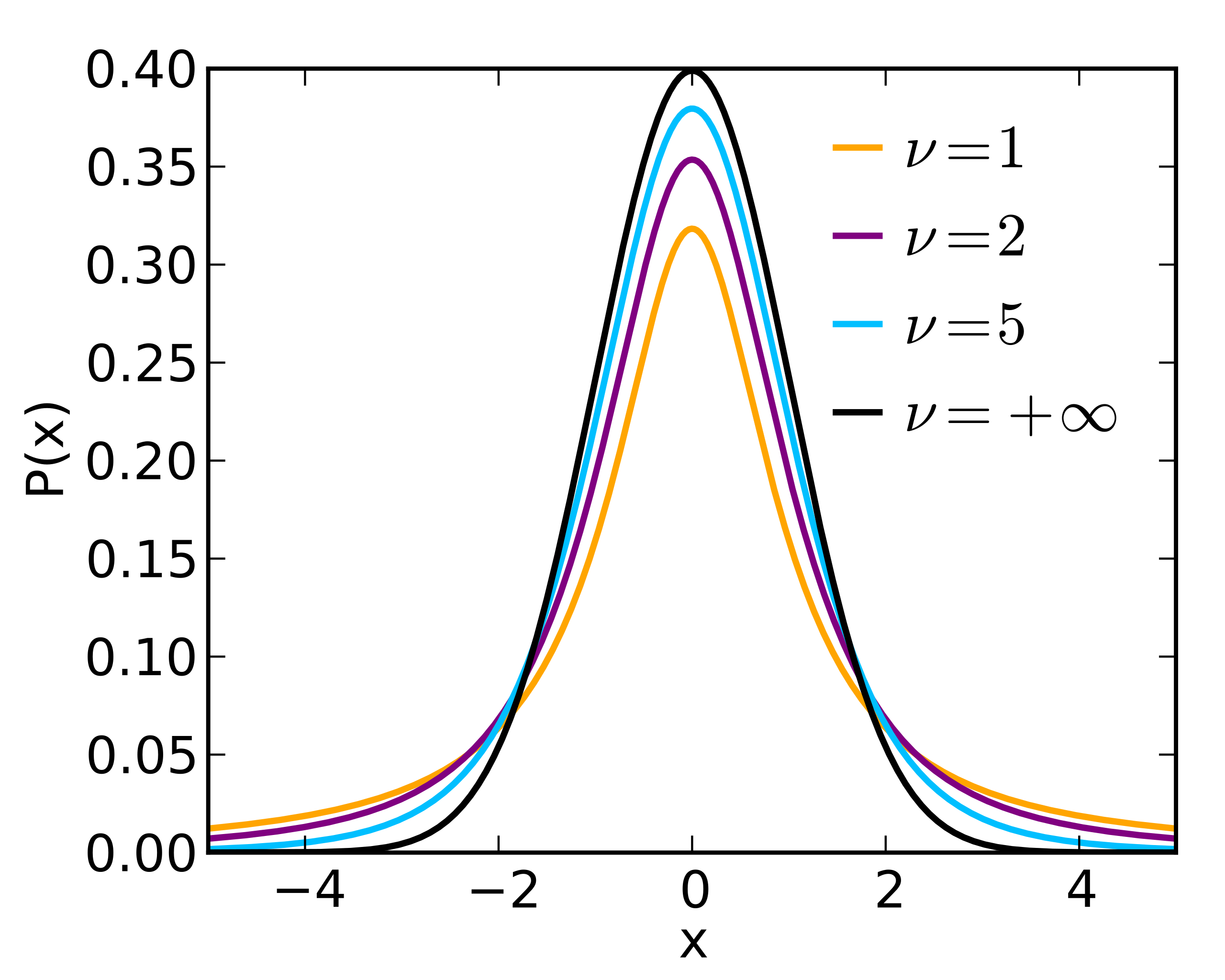
The t-distribution resembles a standard normal distribution when \(\nu\) goes to infinity.
Step 3. Calculate the p-value
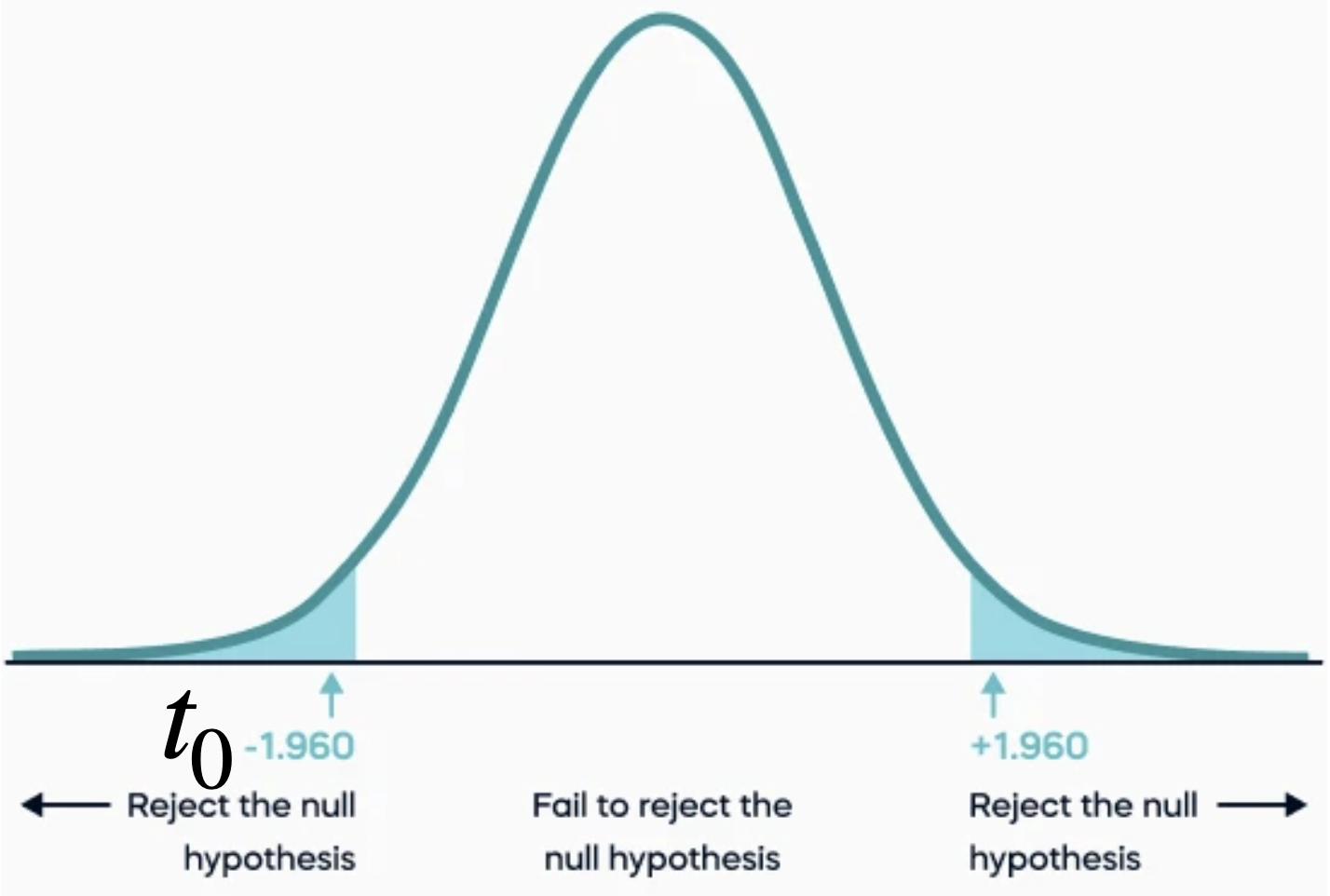
The p-value is the probability that the \(t\) test statistic will get a value that is at least as extreme as the observed \(t_0\) value when the null hypothesis (\(H_0\)) is true.
For \(H_0: \beta_j = 0\) v.s. \(H_1: \beta_j \neq 0\), the p-value is calculated using both tails of the \(t\) distribution. It is the blue area under the curve below.
We use the two tails because \(H_1\) includes the possibility that the value of \(\beta_j\) is positive or negative.
The p-value is not the probability that \(H_0\) is true
Since the p-value is a probability, and since small p-values indicate that \(H_0\) is unlikely to be true, it is tempting to think that the p-value represents the probability that \(H_0\) is true.
This is not the case!
Remember that the p-value is the probability that the \(t\) test statistic will get a value that is at least as extreme as the observed \(t_0\) value when\(H_0\) is true.
How small must the p-value be to reject \(H_0\)?
Answer: Very small!
But, how small?
Answer: Very small!
But, tell me, how small?
Answer: Okay, it must be less than a value called \(\alpha\) which is usually 0.1, 0.05, or 0.01.
We fit or train a linear regression model using the .OLS() and .fit() functions.
# Create linear regression object in statsmodelregr = sm.OLS(auto_Y_train, auto_X_train_with_intercept)# Train the model using the training setslinear_model = regr.fit()
We access the information on the t-tests using the .summary() function.
OLS Regression Results
==============================================================================
Dep. Variable: mpg R-squared: 0.700
Model: OLS Adj. R-squared: 0.698
Method: Least Squares F-statistic: 453.2
Date: Thu, 05 Feb 2026 Prob (F-statistic): 2.43e-102
Time: 18:21:19 Log-Likelihood: -1125.4
No. Observations: 392 AIC: 2257.
Df Residuals: 389 BIC: 2269.
Df Model: 2
Covariance Type: nonrobust
================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------
const 41.0953 1.868 21.999 0.000 37.423 44.768
weight -0.0073 0.000 -25.966 0.000 -0.008 -0.007
acceleration 0.2617 0.086 3.026 0.003 0.092 0.432
==============================================================================
Omnibus: 31.397 Durbin-Watson: 0.818
Prob(Omnibus): 0.000 Jarque-Bera (JB): 39.962
Skew: 0.632 Prob(JB): 2.10e-09
Kurtosis: 3.922 Cond. No. 2.67e+04
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 2.67e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
Table of t-tests
coef
std err
t
P>\(|t|\)
\([0.025\)
\(0.975 ]\)
const
41.0953
1.868
21.999
0.000
37.423
44.768
weight
-0.0073
0.000
-25.966
0.000
-0.008
-0.007
acceleration
0.2617
0.086
3.026
0.003
0.092
0.432
The column std err contains the values of the estimated standard error (\(\sqrt{ \hat{v}_{jj}}\)) of the estimates \(\hat{\beta}_j\). They represent the variability in the estimates.
coef
std err
t
P>\(|t|\)
\([0.025\)
\(0.975 ]\)
const
41.0953
1.868
21.999
0.000
37.423
44.768
weight
-0.0073
0.000
-25.966
0.000
-0.008
-0.007
acceleration
0.2617
0.086
3.026
0.003
0.092
0.432
The column t contains the values of the observed statistic \(t_0\) for the hypothesis tests.
coef
std err
t
P>\(|t|\)
\([0.025\)
\(0.975 ]\)
const
41.0953
1.868
21.999
0.000
37.423
44.768
weight
-0.0073
0.000
-25.966
0.000
-0.008
-0.007
acceleration
0.2617
0.086
3.026
0.003
0.092
0.432
The column P>|t| contains the p-values for the hypothesis tests.
Since the p-value is smaller than \(\alpha = 0.05\), we reject \(H_0\) for acceleration and weight. Therefore, weight and acceleration have a significant association with the mpg of a car.
coef
std err
t
P>\(|t|\)
\([0.025\)
\(0.975 ]\)
const
41.0953
1.868
21.999
0.000
37.423
44.768
weight
-0.0073
0.000
-25.966
0.000
-0.008
-0.007
acceleration
0.2617
0.086
3.026
0.003
0.092
0.432
The columns \([0.025\) and \(0.975]\) show the limits of a 95% confidence interval on each true coefficient \(\beta_j\). This interval contains the true parameter value with a confidence of 95%.
Residual analysis
Residuals
The errors of the estimated model are called residuals\(\hat{\epsilon}_i = Y_i - \hat{Y}_i\), \(i = 1, \ldots, n.\)
In linear regression, we can validate the adequacy of the model by checking whether the residuals \(\hat{\epsilon}_1, \hat{\epsilon}_2, \ldots, \hat{\epsilon}_n\) satisfy three (or four) assumptions.
Assumptions
The residuals \(\hat{\epsilon}_i\)’s must then satisfy the following assumptions:
On average, they are close to zero for any value of the predictors \(X_j\).
For any value of the predictor \(X_j\), the dispersion or variance is roughly the same.
The \(\epsilon_i\)’s are independent from each other.
The \(\hat{\epsilon}_i\)’s follow normal distribution.
To evaluate the assumption of a linear regression model, we use a Residual analysis.
Residual Analysis
To check the validity of these assumptions, we will follow a graphical approach. Specifically, we will construct three informative plots of the residuals.
Residuals vs Fitted Values Plot. To assess the structure of the model and check for constant variance
Residuals Vs Time Plot. To check independence.
Normal Quantile-Quantile Plot. To assess if the residuals follow a normal distribution
Example 2
This example is inspired by Foster, Stine and Waterman (1997, pages 191–199).
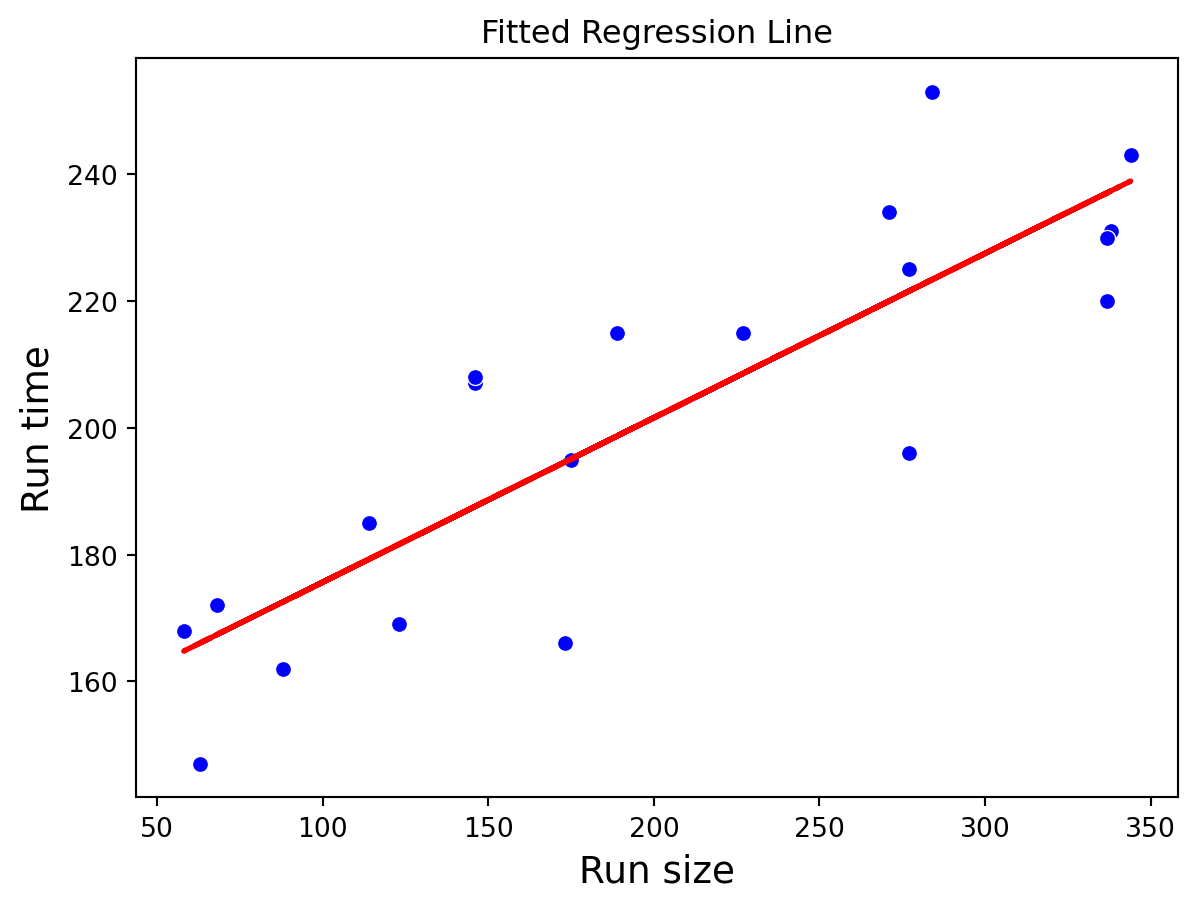
The data are in the form of the time taken (in minutes) for a production run, \(Y\), and the number of items produced, \(X\), for 20 randomly selected orders as supervised by a manager.
We wish to develop an equation to model the relationship between the run time (\(Y\)) and the run size (\(X\)).
where \(X_i\) is the run size and \(\hat{Y}_i\) is the predicted run time for the \(i\)-th observation, \(i = 1, \ldots, 20\).
We fit the model in scikit-learn using the entire data for training.
# Defining the predictor (X) and the response variable (Y).prod_Y_train = production_data['RunTime']prod_X_train = production_data[['RunSize']]# Fitting the simple linear regression model.LRmodelProd = LinearRegression()LRmodelProd.fit(prod_X_train, prod_Y_train)
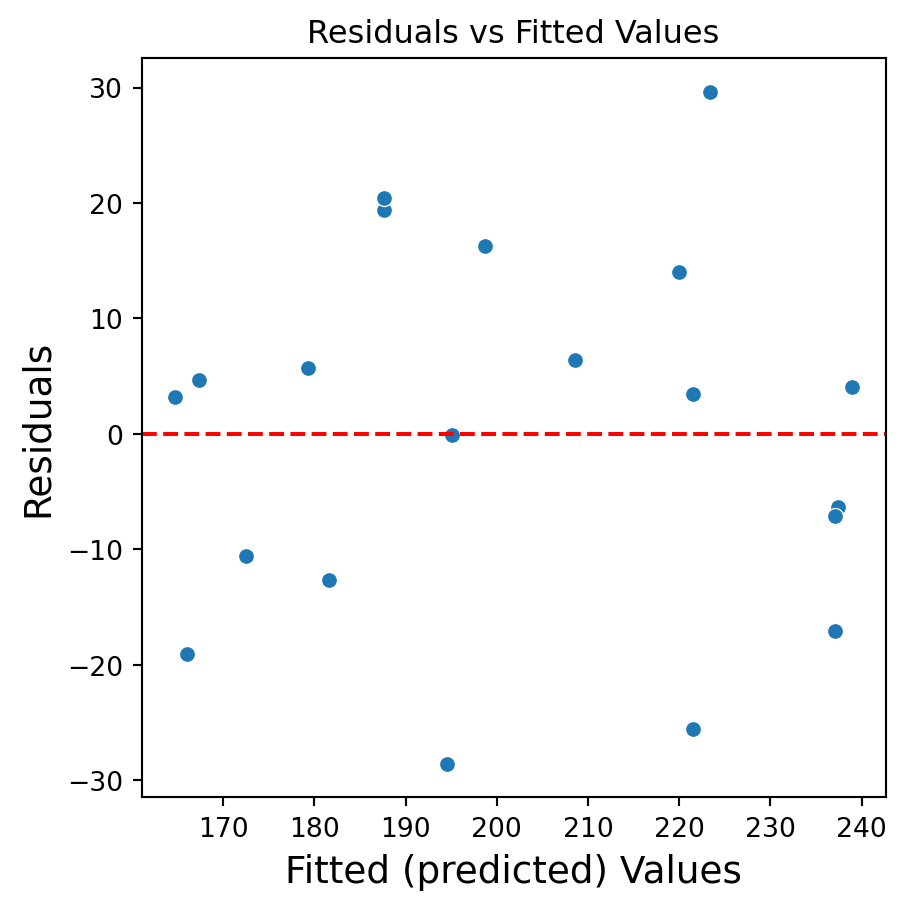
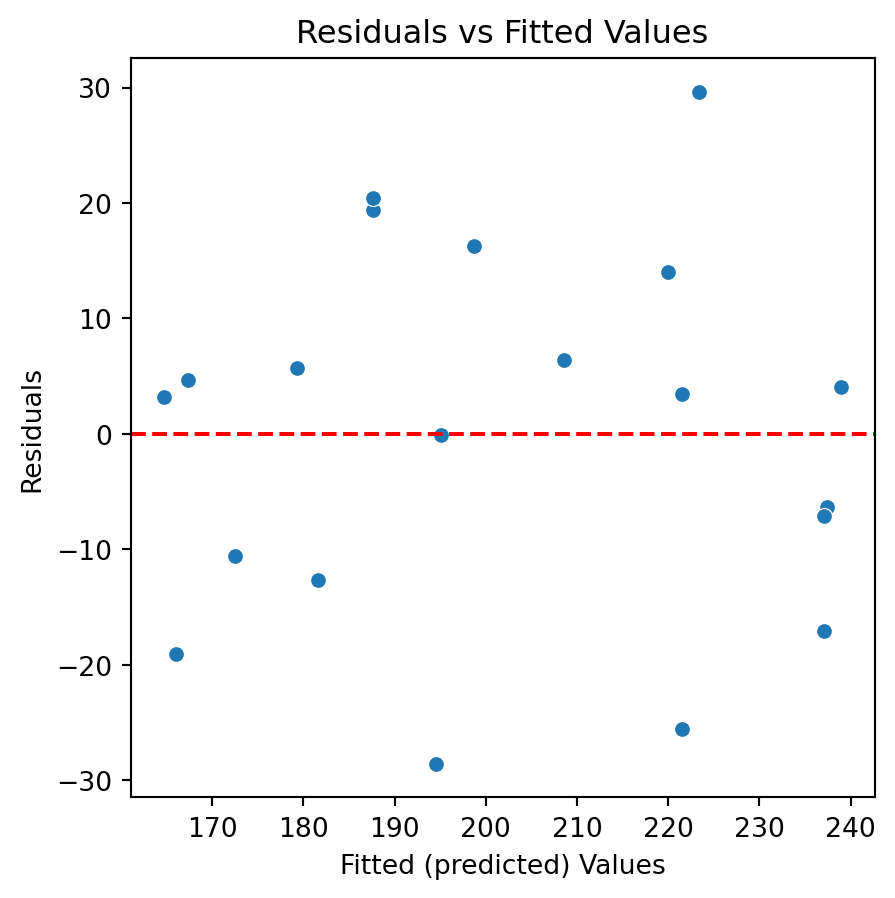
# Residual vs Fitted Values Plotplt.figure(figsize=(5, 5))sns.scatterplot(x = prod_Y_pred, y = residuals)plt.axhline(y=0, color='red', linestyle='--')plt.title('Residuals vs Fitted Values')plt.xlabel('Fitted (predicted) Values', fontsize =14)plt.ylabel('Residuals', fontsize =14)plt.show()
Residuals vs Fitted Values
If there is a trend, the model is misspecified.
A “funnel” shape indicates that the assumption of constant variance is not met.
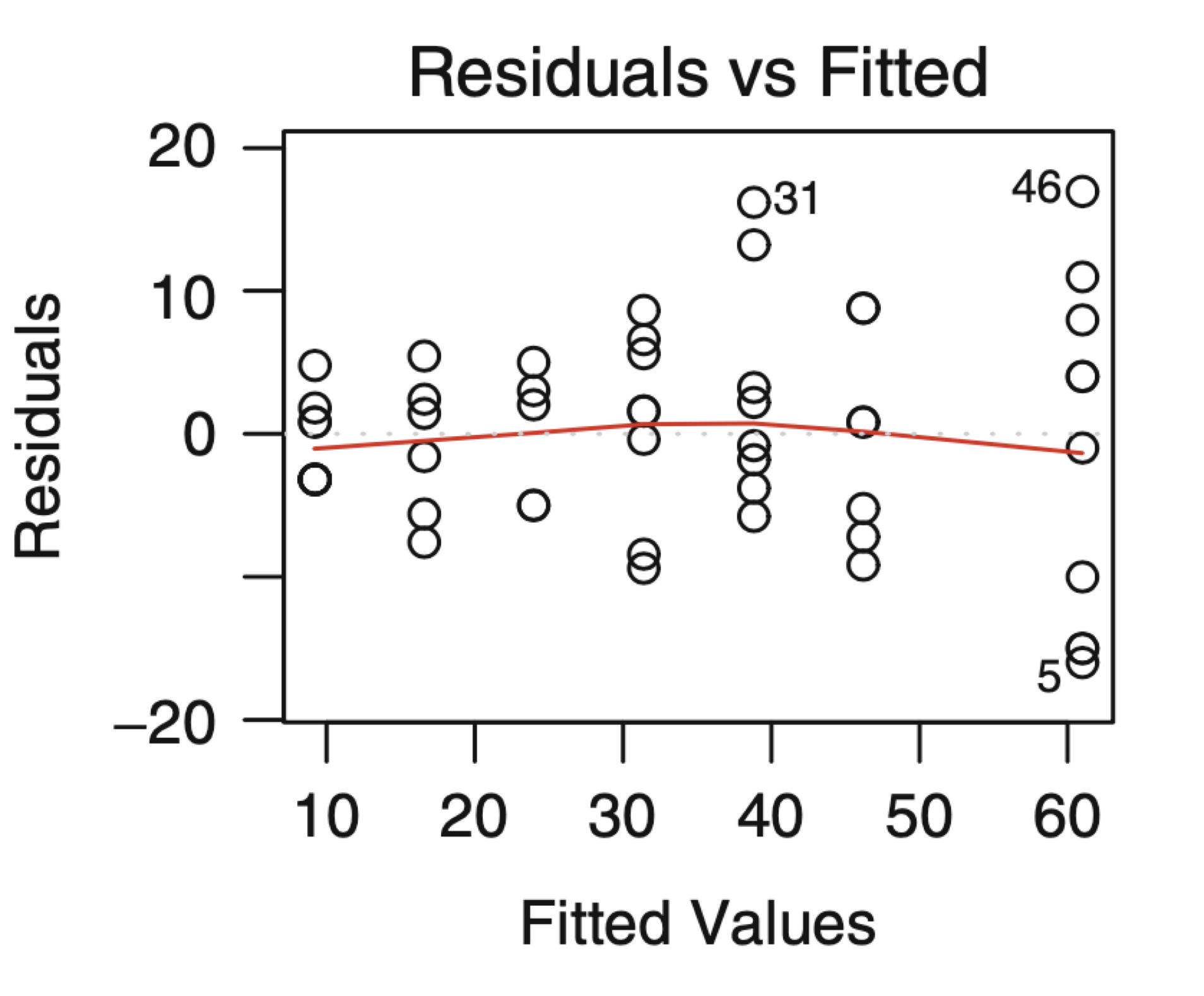
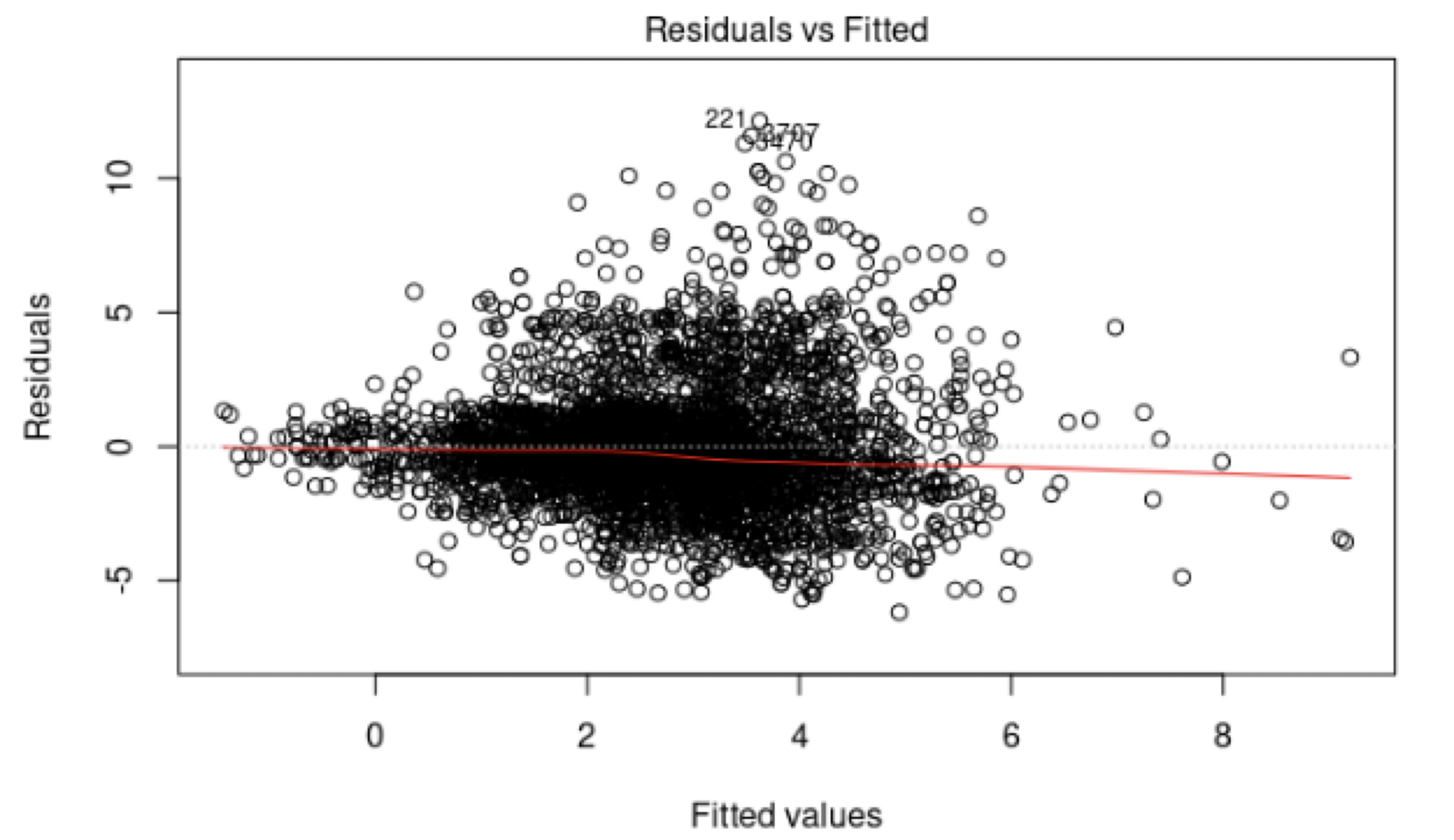
Examples of plots that do not support the conclusion of constant variance.
Another example.
The phenomenon of non-constant variance is called heteroscedasticity.
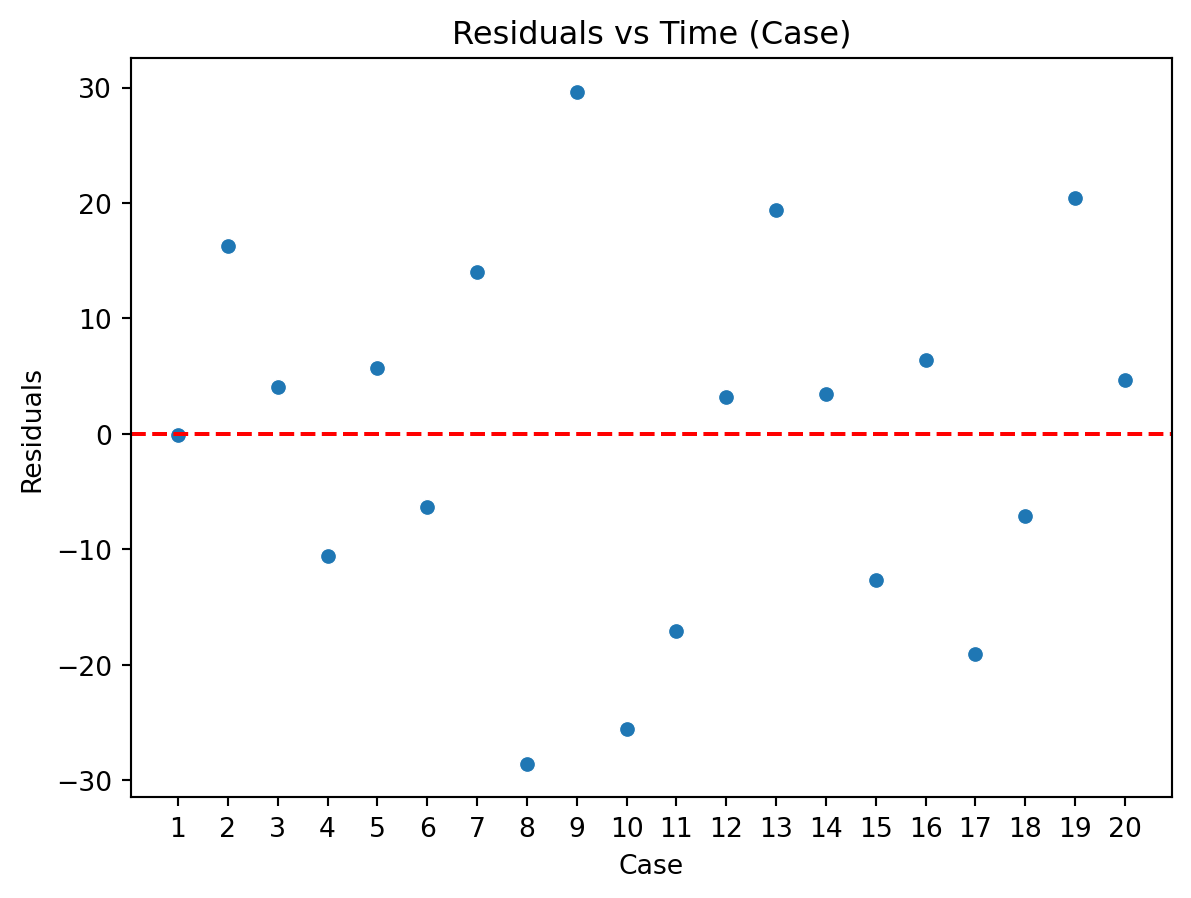
Residuals vs Time Plot
Residuals vs Time Plot
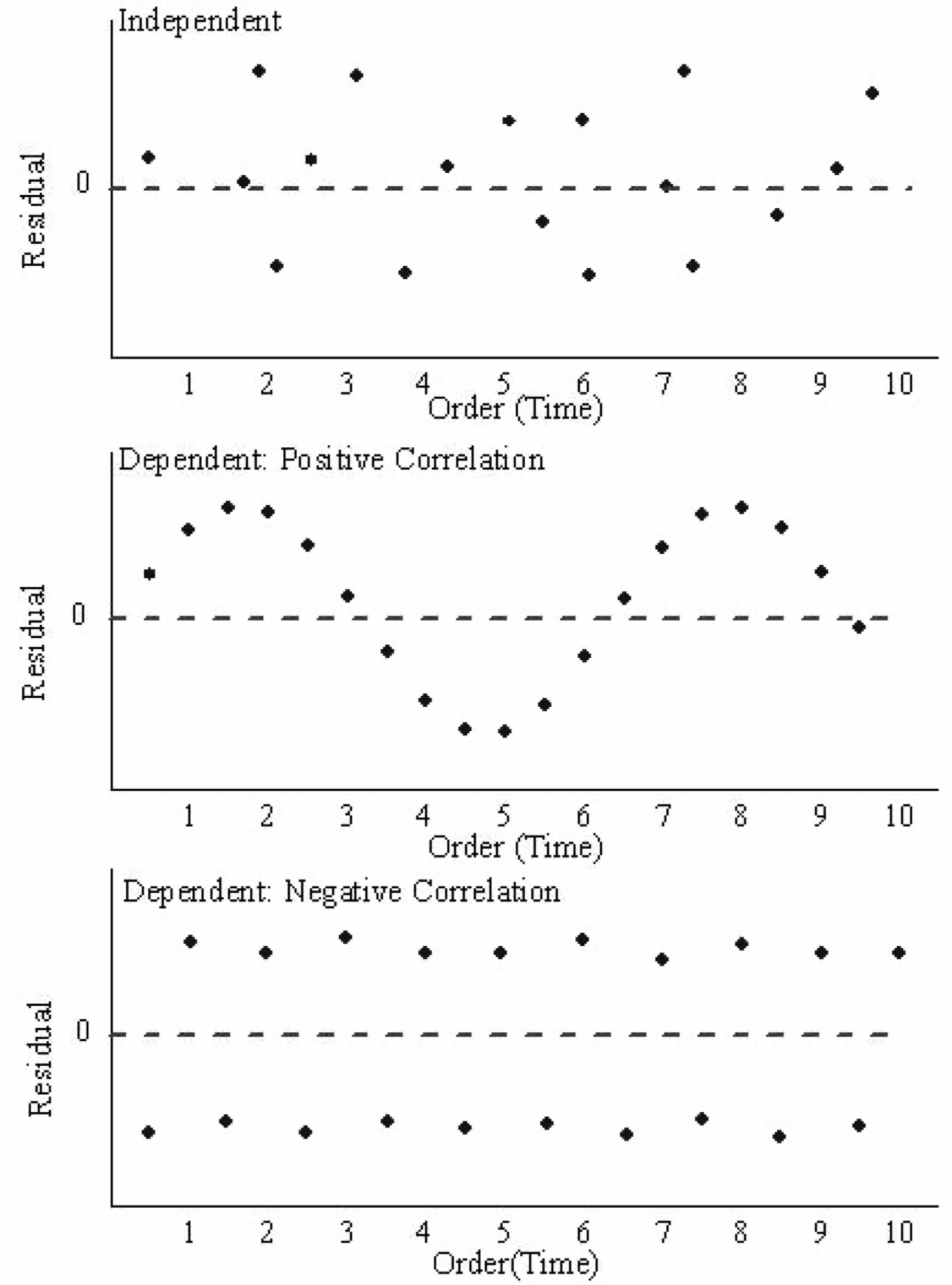
By “time,” we mean that time the observation was taken or the order in which it was taken. The plot should not show any structure or pattern in the residuals.
Dependence on time is a common source of lack of independence, but other plots might also detect lack of independence.
Ideally, we plot the residuals versus each variable of interest we could think of, either included or excluded in the model.
Assessing the assumption of independence is hard in practice.
Code
# Residuals vs Time (Case) Plotplt.figure(figsize=(7, 5))sns.scatterplot(x = production_data['Case'], y = residuals)plt.axhline(y=0, color='red', linestyle='--')plt.title('Residuals vs Time (Case)')plt.xlabel('Case')plt.xticks(production_data['Case'])plt.ylabel('Residuals')plt.show()
Examples of plots that do and do not support the independence assumption.
Normal Quantile-Quantile Plot
Checking for normality
This assumption is generally checked by looking at the distribution of the residuals.
Two plots:
Histogram.
Normal Quantile-Quantile Plot (also called normal probability plot).
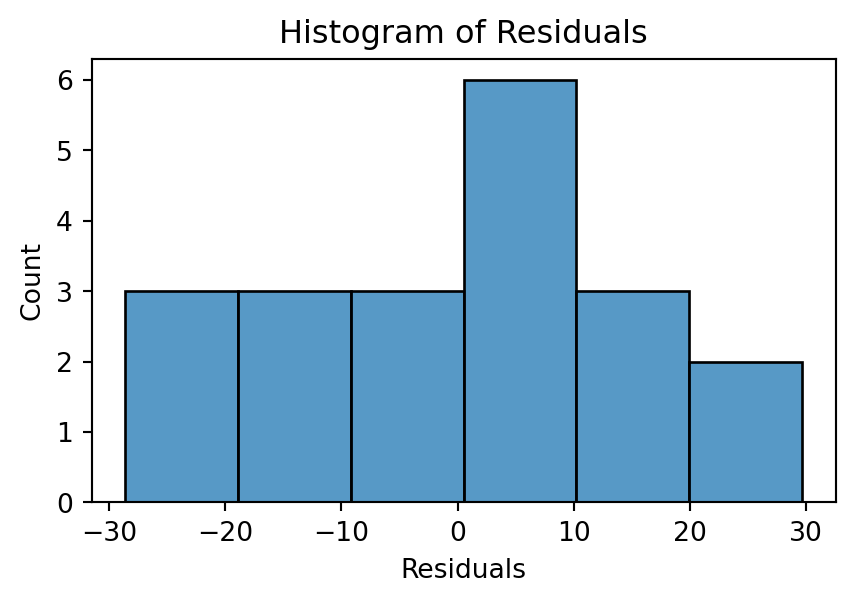
Histogram
Ideally, the histogram resembles a normal distribution around 0. If the number of observations is small, the histogram may not be an effective visualization.
Code
# Histogram of residualsplt.figure(figsize=(5, 3))sns.histplot(residuals)plt.title('Histogram of Residuals')plt.xlabel('Residuals')plt.show()
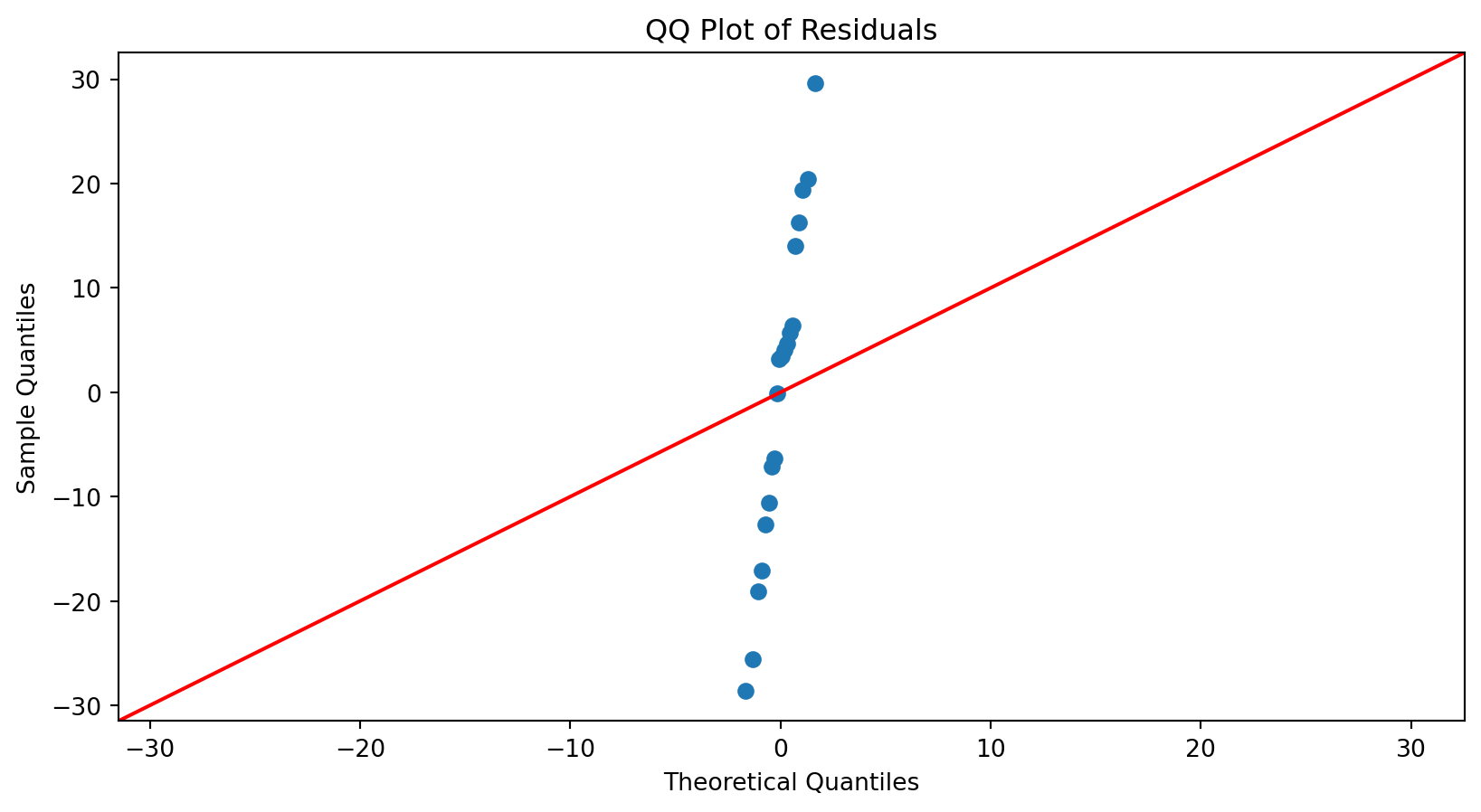
Normal Quantile-Quantile (QQ) Plot
A normal QQ plot is helpful for deciding whether a sample was drawn from a distribution that is approximately normal.
First, let \(\hat{\epsilon}_{[1]}, \hat{\epsilon}_{[2]}, \ldots, \hat{\epsilon}_{[n]}\) be the residuals ranked in an increasing order, where \(\hat{\epsilon}_{[1]}\) is the minimum and \(\hat{\epsilon}_{[n]}\) is the maximum. These points define the sample percentiles (or quantiles) of the distribution of the residuals.
Next, calculate the theoretical percentiles of a (standard) Normal distribution calculated using Python.
The normal QQ plot displays the (sample) percentiles of the residuals versus the percentiles of a normal distribution.
If these percentiles agree with each other, then they would approximate a straight line.
The straight line is usually determined visually, with emphasis on the central values rather than the extremes.
To construct a QQ plot, we use the function qqplot() from the statsmodels library.
# QQ plot to assess normality of residualsplt.figure(figsize=(5, 3))sm.qqplot(residuals, fit =True, line ='45')plt.title('QQ Plot of Residuals')plt.show()
Substantial departures from a straight line indicate that the distribution is not normal.
<Figure size 672x384 with 0 Axes>
This plot suggests that the residuals are consistent with a Normal curve.
<Figure size 672x384 with 0 Axes>
Comments
These data are truly Normally distributed. But note that we still see deviations. These are entirely due to chance.
When \(n\) is relatively small, you tend to see deviations, particularly in the tails.
Normal probability plots for data sets following various distributions. 100 observations in each data set.
Consequences of faulty assumptions
If the model structure is incorrect, the estimated coefficients \(\hat{\beta}_j\) will be incorrect and the predictions \(\hat{Y}_i\) will be inaccurate.
If the residuals do not follow a normal distribution, we have two cases:
If sample size is large, we still get accurate p-values for the t-tests for the coefficients thanks to the Central Limit Theorem.
Otherwiese, the t-tests and p-values are unreliable.
If the residuals do not have constant variance, then the linear model is incorrect and everything falls apart!
If the residuals are dependent, then the linear model is incorrect and everything falls apart!
There are methods to correct the faulty assumptions, but we will not discus them here.



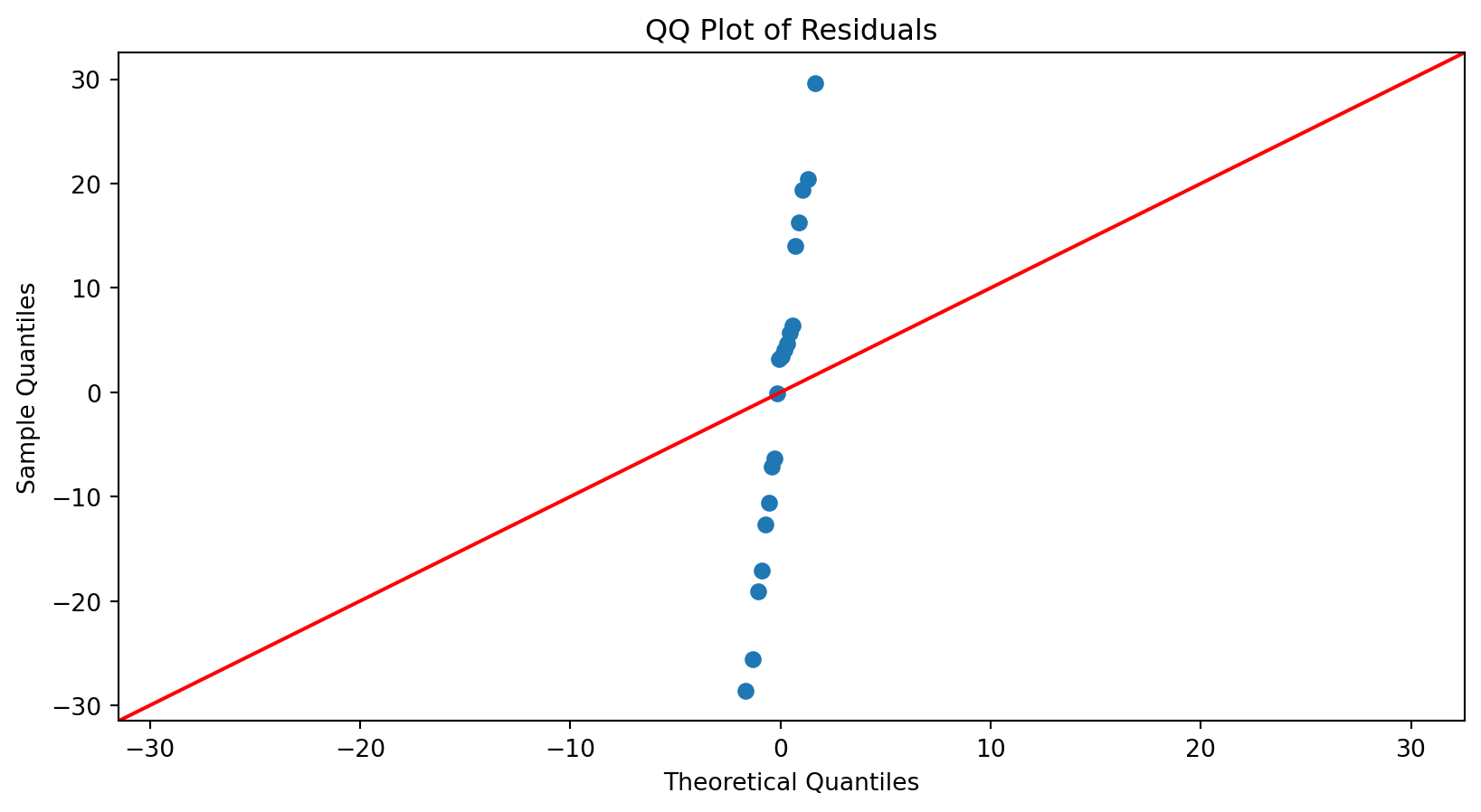
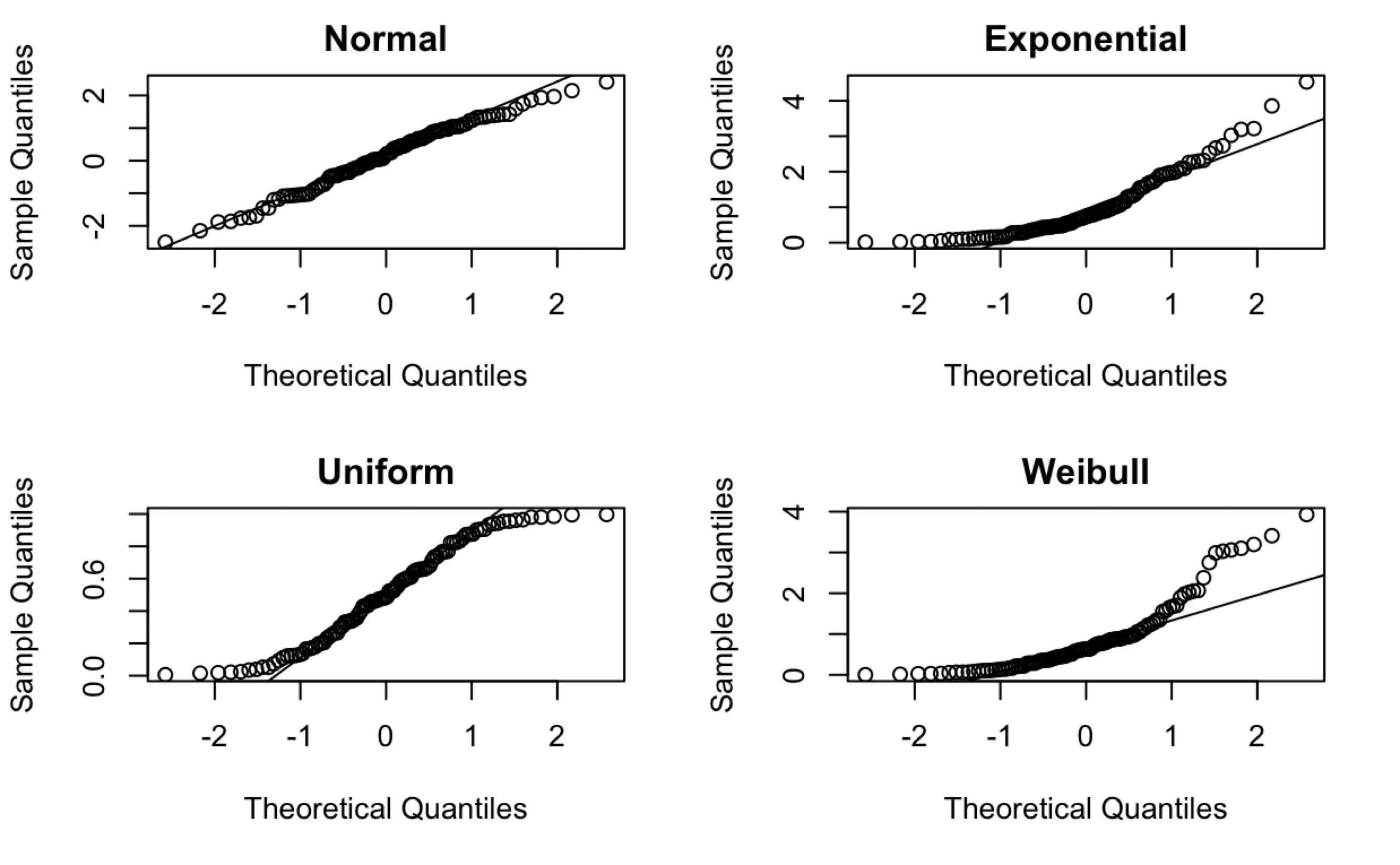
Comments
These data are truly Normally distributed. But note that we still see deviations. These are entirely due to chance.
When \(n\) is relatively small, you tend to see deviations, particularly in the tails.